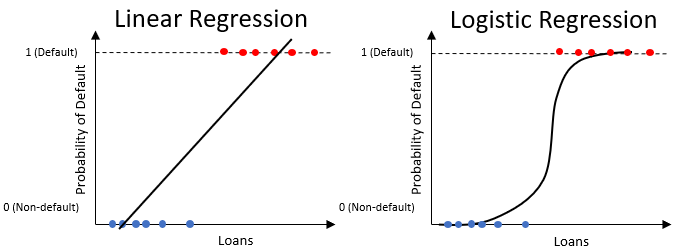
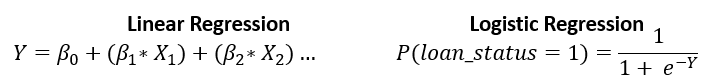Logistische Regression für Ausfallwahrscheinlichkeit
Kreditrisikomodellierung in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Wahrscheinlichkeiten vorhersagen
- Ausfallwahrscheinlichkeiten als Ergebnis von Machine Learning
- Lernen aus Spalten (Features)
- Klassifikationsmodelle (Ausfall, kein Ausfall)
- Zwei gängige Modelle:
- Logistische Regression
- Entscheidungsbaum
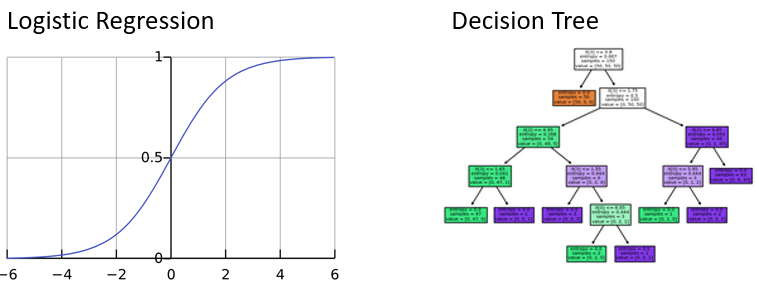
Logistische Regression
- Ähnlich wie lineare Regression, liefert aber nur Werte zwischen
0und1