Kreditannahmeraten
Kreditrisikomodellierung in Python

Michael Crabtree
Data Scientist, Ford Motor Company
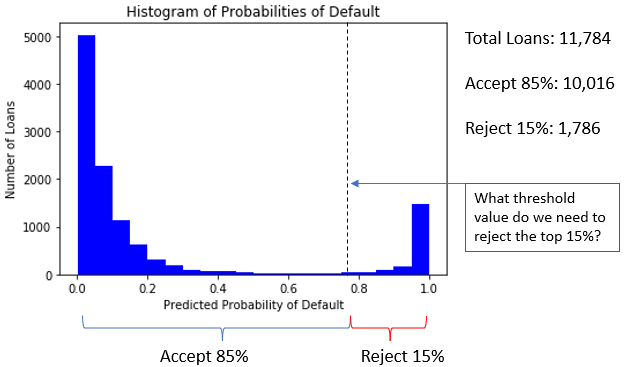
Annahmerate verstehen
- Beispiel: 85% der Kredite mit der niedrigsten
prob_defaultannehmen
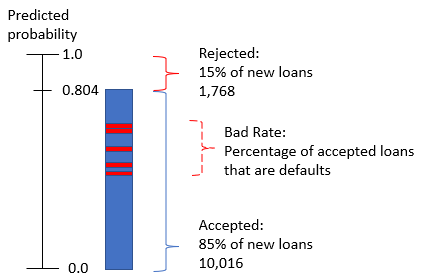
Bad Rate
- Auch mit berechnetem Schwellenwert werden einige angenommene Kredite ausfallen
- Das sind Kredite mit
prob_defaultnahe Bereichen, in denen das Modell schlecht kalibriert ist
Berechnung der Bad Rate
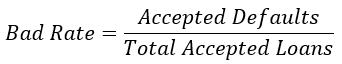
#Calculate the bad rate
np.sum(accepted_loans['true_loan_status']) / accepted_loans['true_loan_status'].count()
- Wenn Nichtausfall
0und Ausfall1ist, dann istsum()die Anzahl der Ausfälle .count()einer einzelnen Spalte entspricht der Zeilenanzahl des DataFrames

