Cross-Validation für Kreditmodelle
Kreditrisikomodellierung in Python

Michael Crabtree
Data Scientist, Ford Motor Company
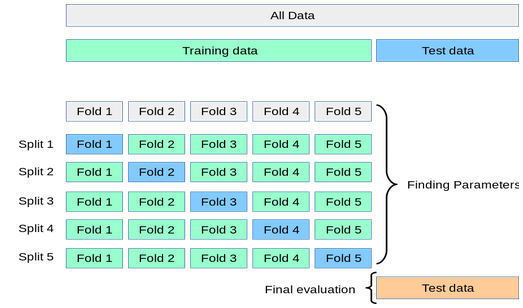
So funktioniert Cross-Validation
- Verarbeitet Teile der Trainingsdaten (Folds) und testet gegen ungenutzte Teile
- Abschließender Test gegen das eigentliche Testset
1 https://scikit-learn.org/stable/modules/cross_validation.html
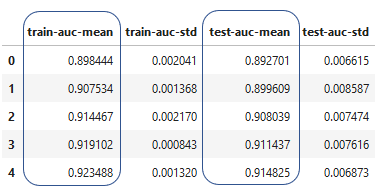
Ergebnisse der Cross-Validation
- Erstellt ein DataFrame mit den Werten aus der Cross-Validation