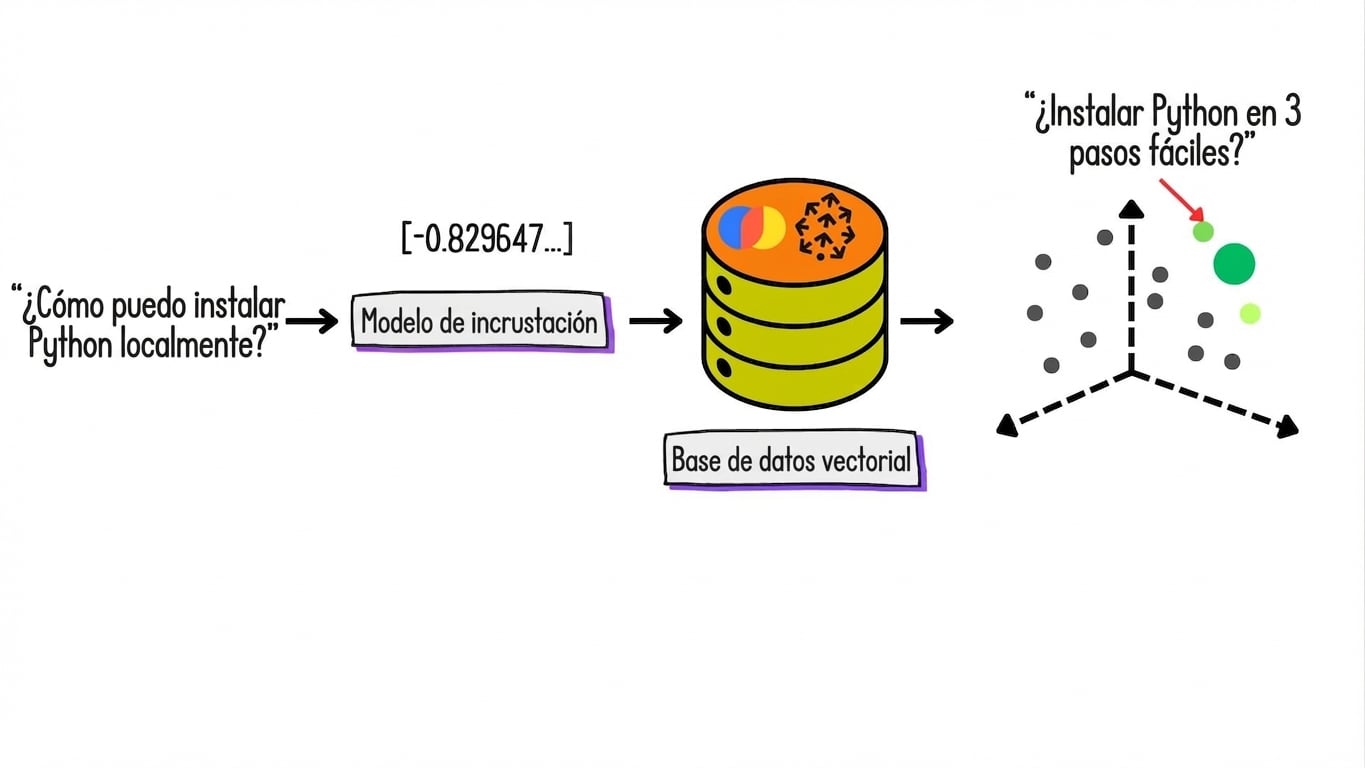
División de texto, embeddings y almacenamiento de vectores
Retrieval Augmented Generation (RAG) con LangChain

Meri Nova
Machine Learning Engineer
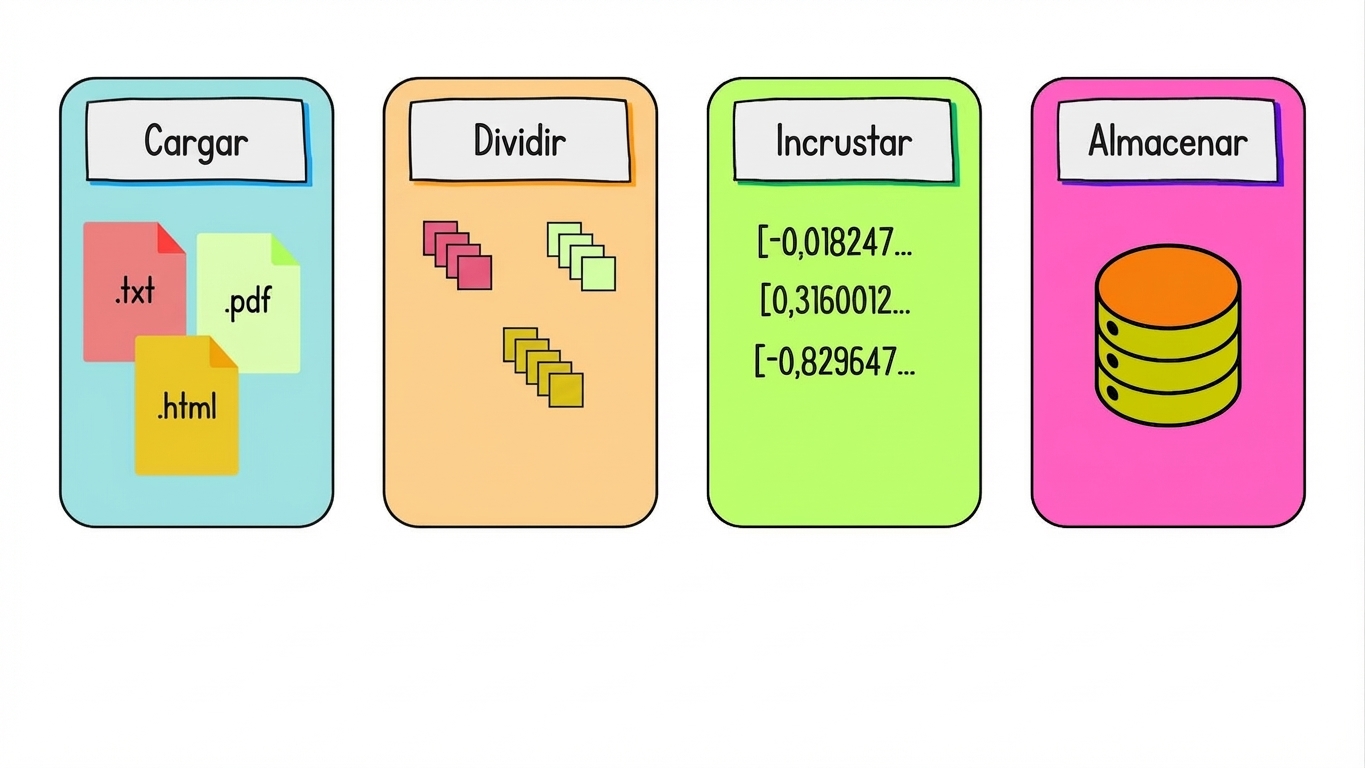
Preparar datos para la recuperación
Preparar datos para la recuperación
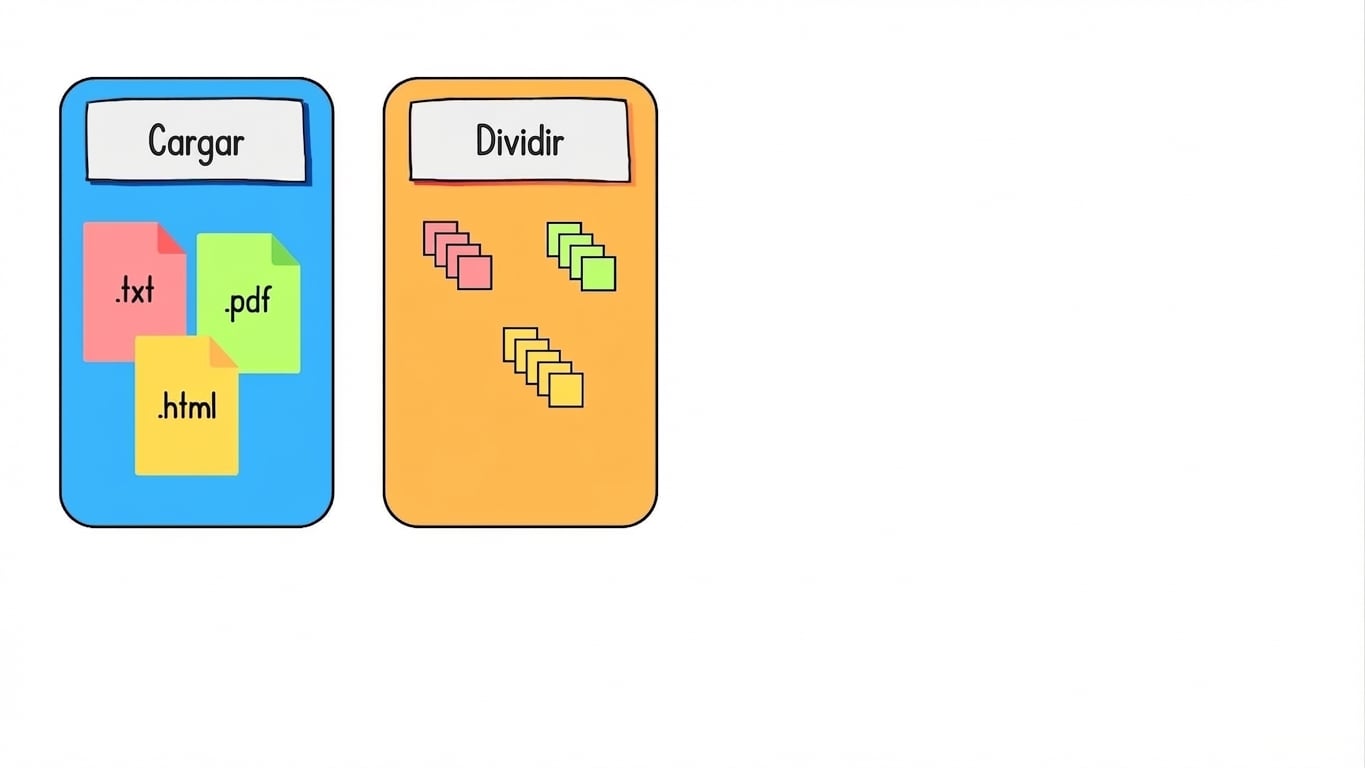
Preparar datos para la recuperación
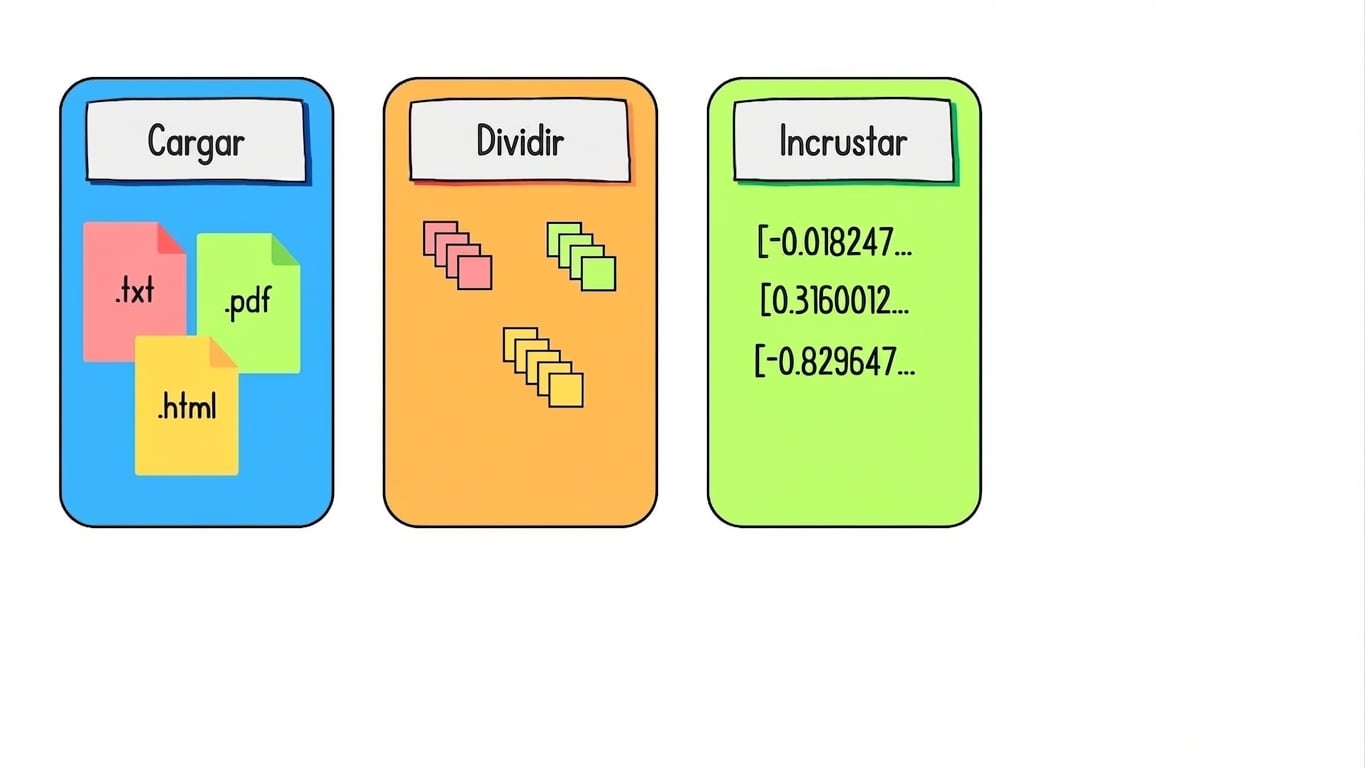
Preparar datos para la recuperación
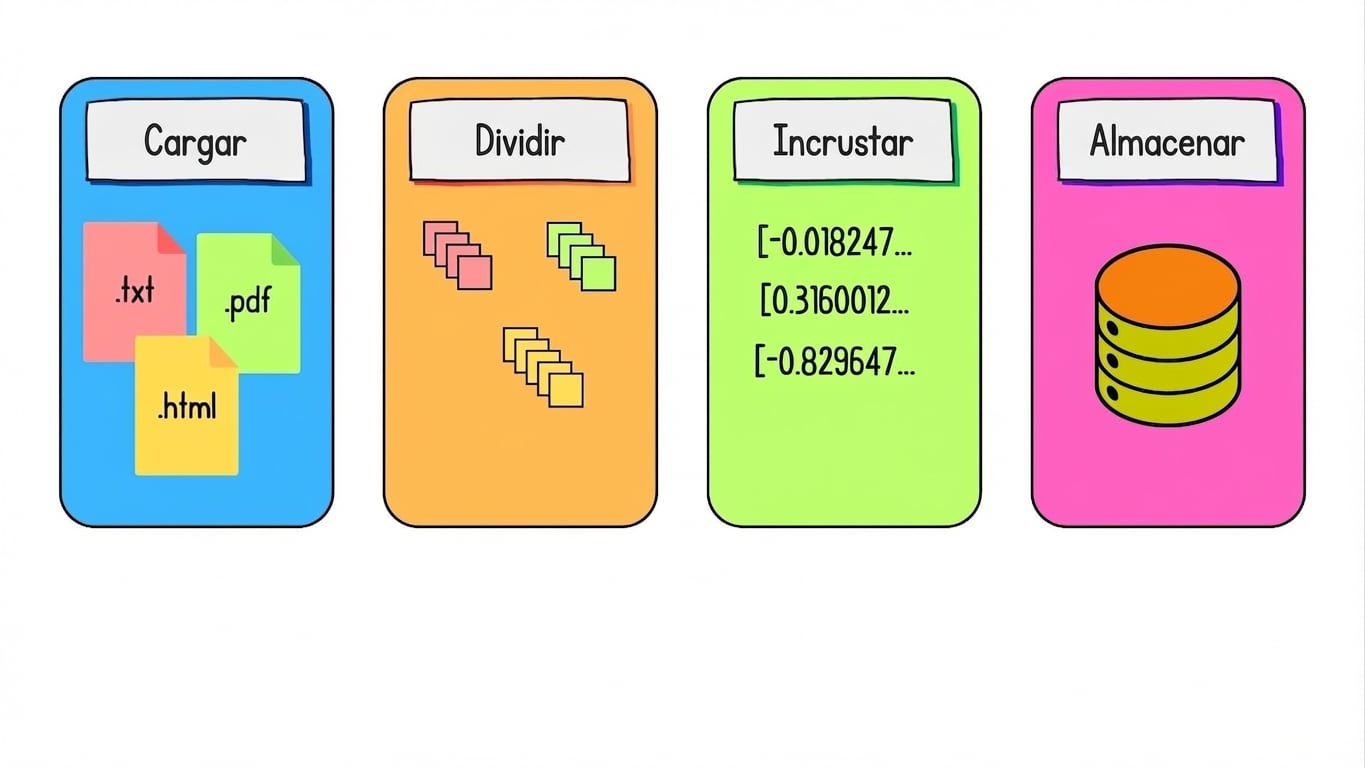
Preparar datos para la recuperación
chunk_size
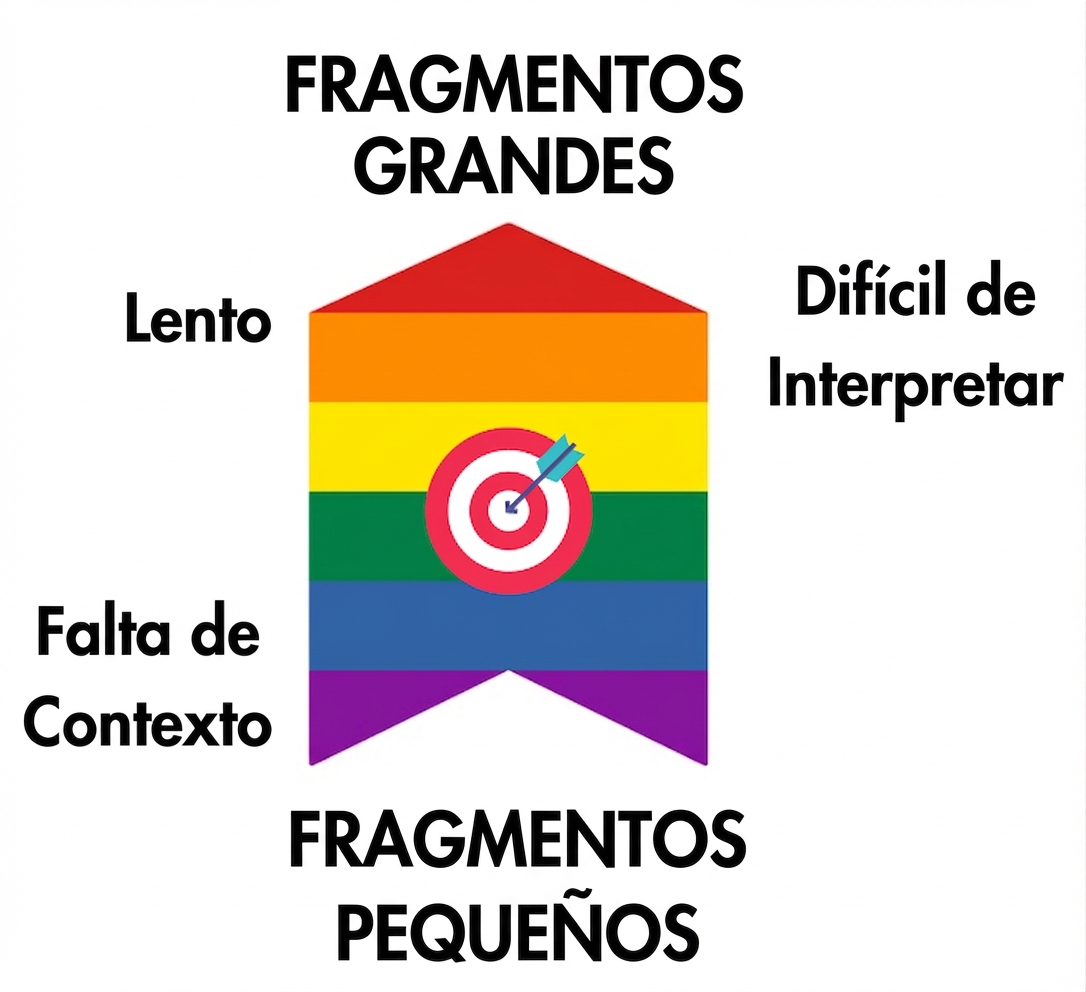
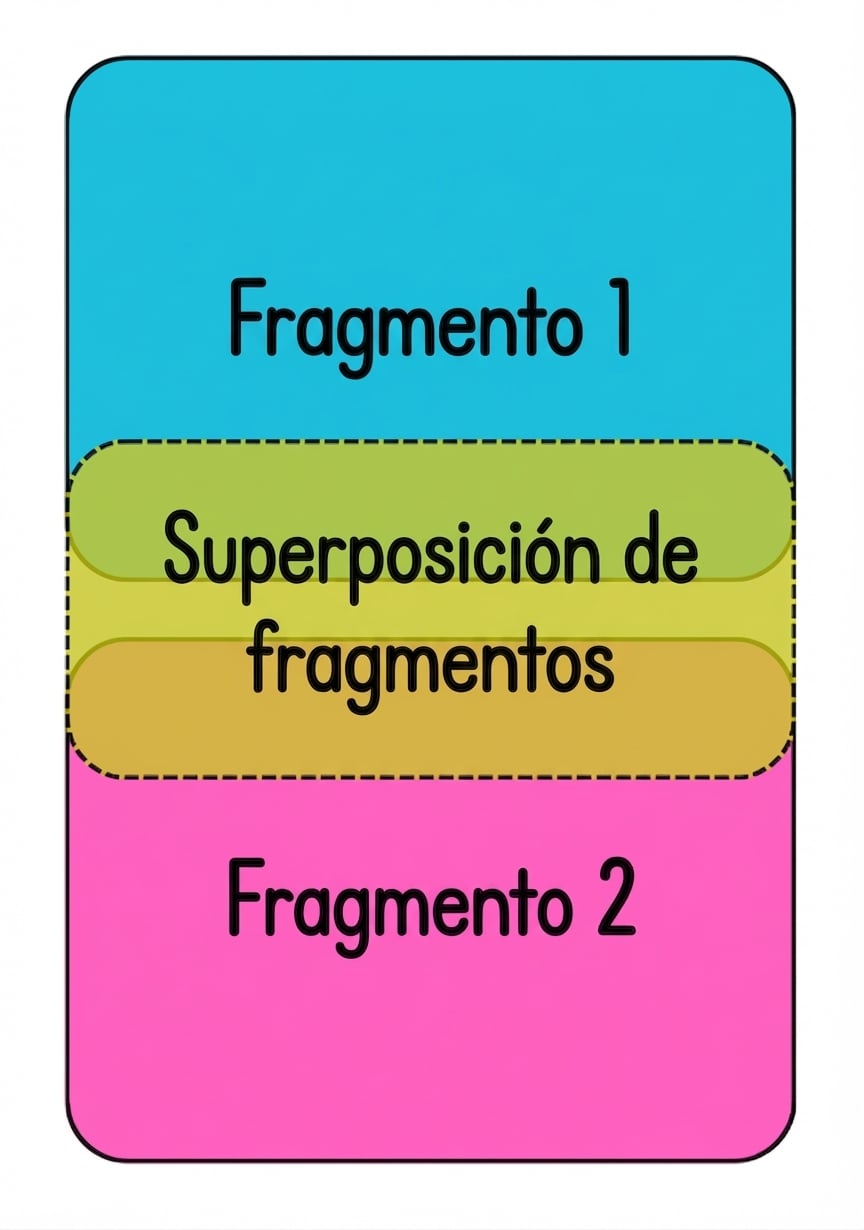
chunk_overlap
- Incluye info más allá del límite
Embedding y almacenamiento
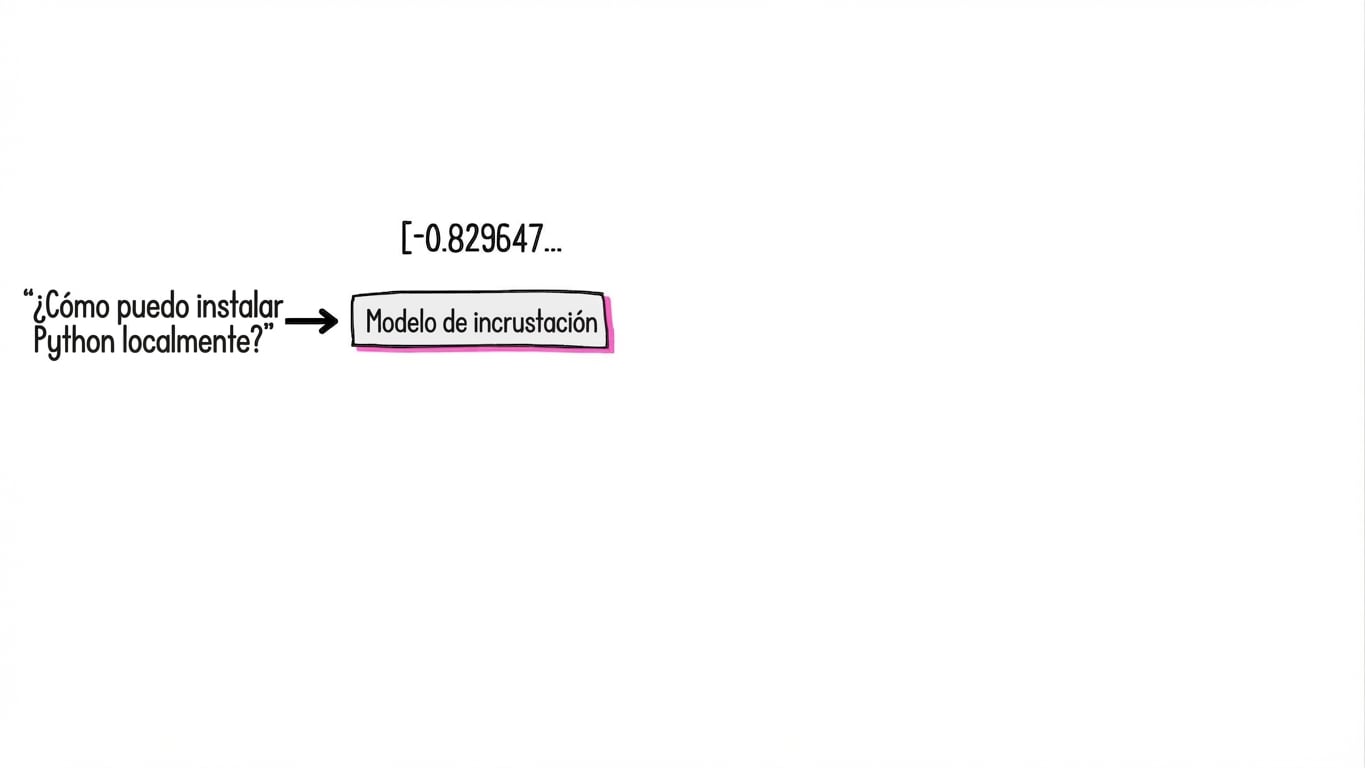
¿Qué son los embeddings?

¿Qué son los embeddings?
¿Qué son los embeddings?
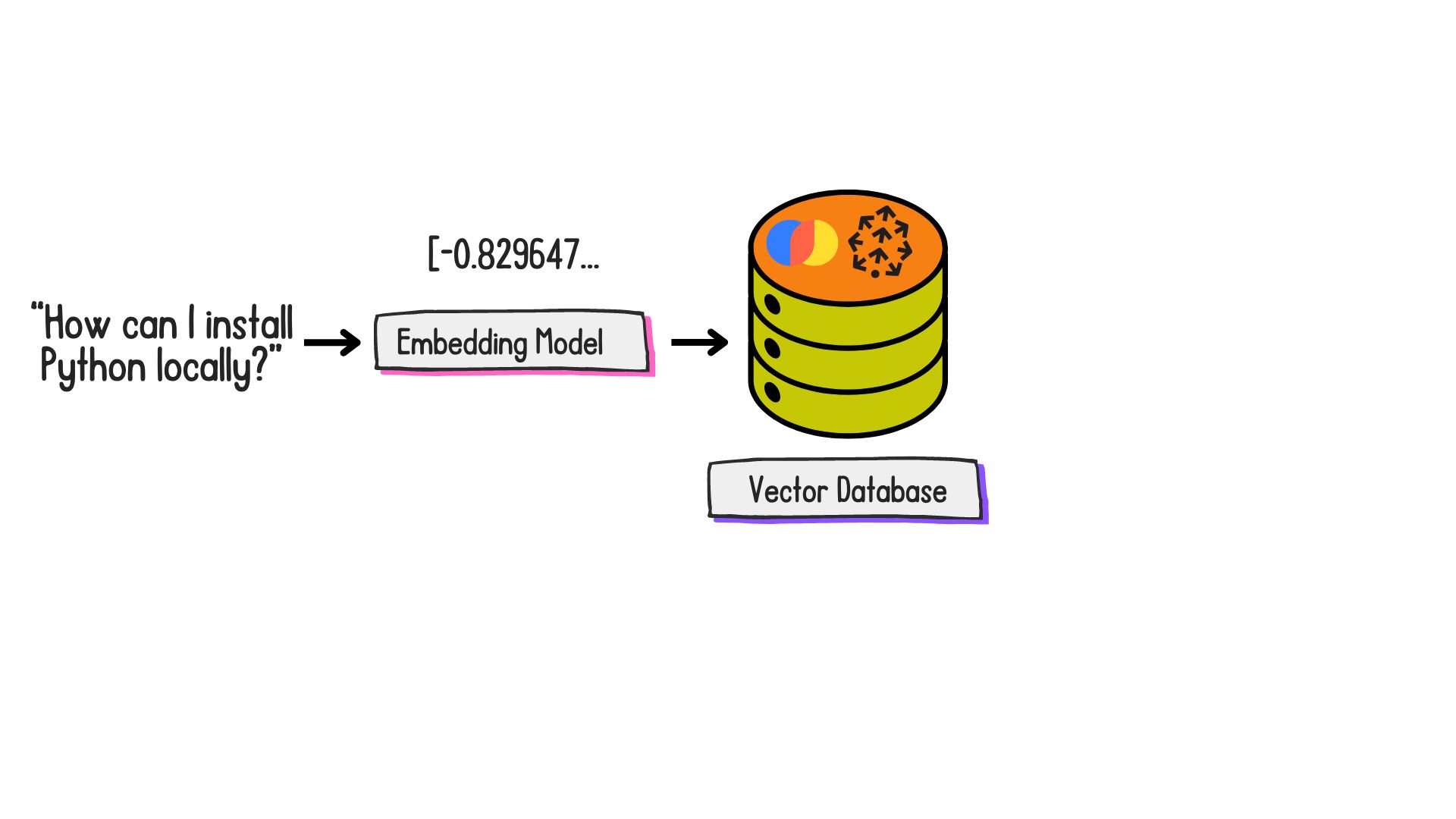
¿Qué son los embeddings?