Análisis exploratorio de datos
Machine Learning de extremo a extremo

Joshua Stapleton
Machine Learning Engineer
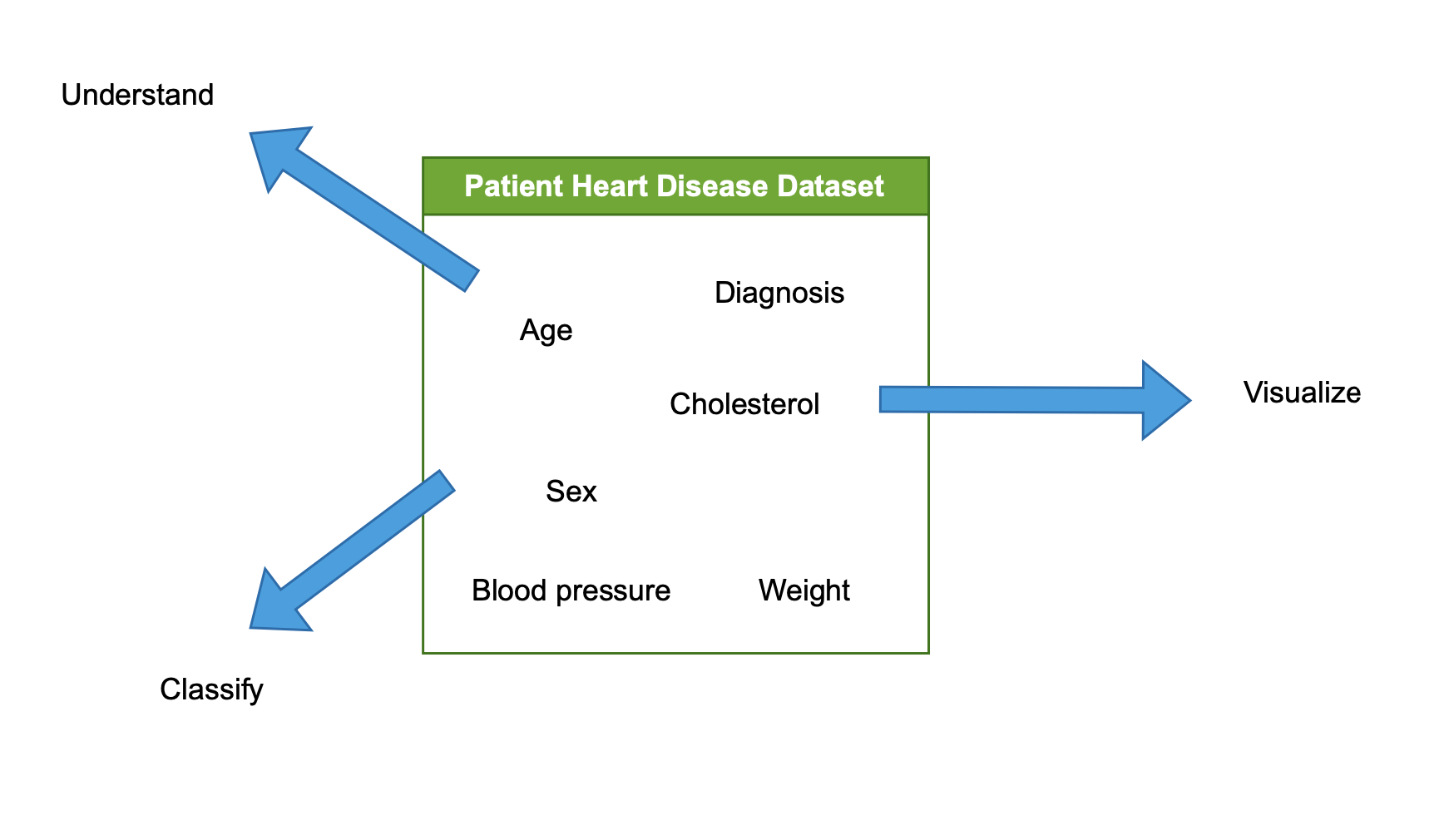
Proceso de EDA
- Examinar y analizar el dataset
- Entender el dataset
- Visualizar el dataset
- Caracterizar / clasificar el dataset
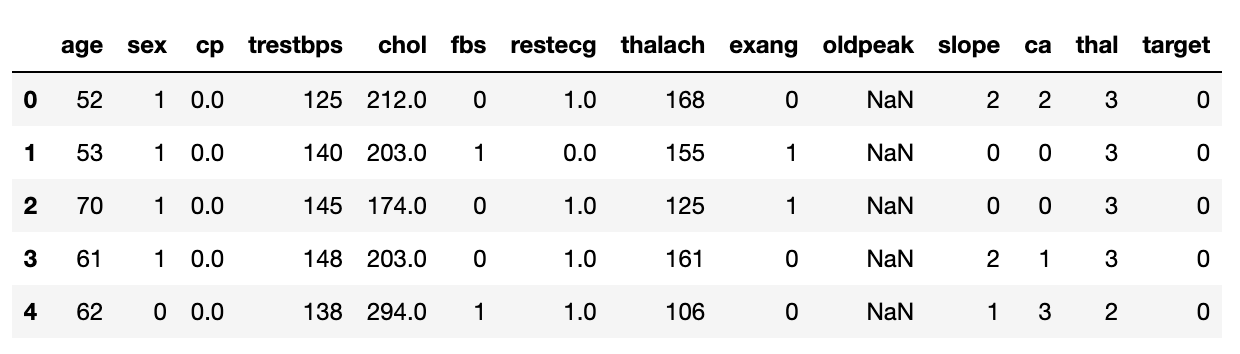
Entender los datos
df.head()
- Muestra las primeras filas
- Ofrece una vista rápida de la estructura
# Print the first 5 rows
print(heart_disease_df.head())
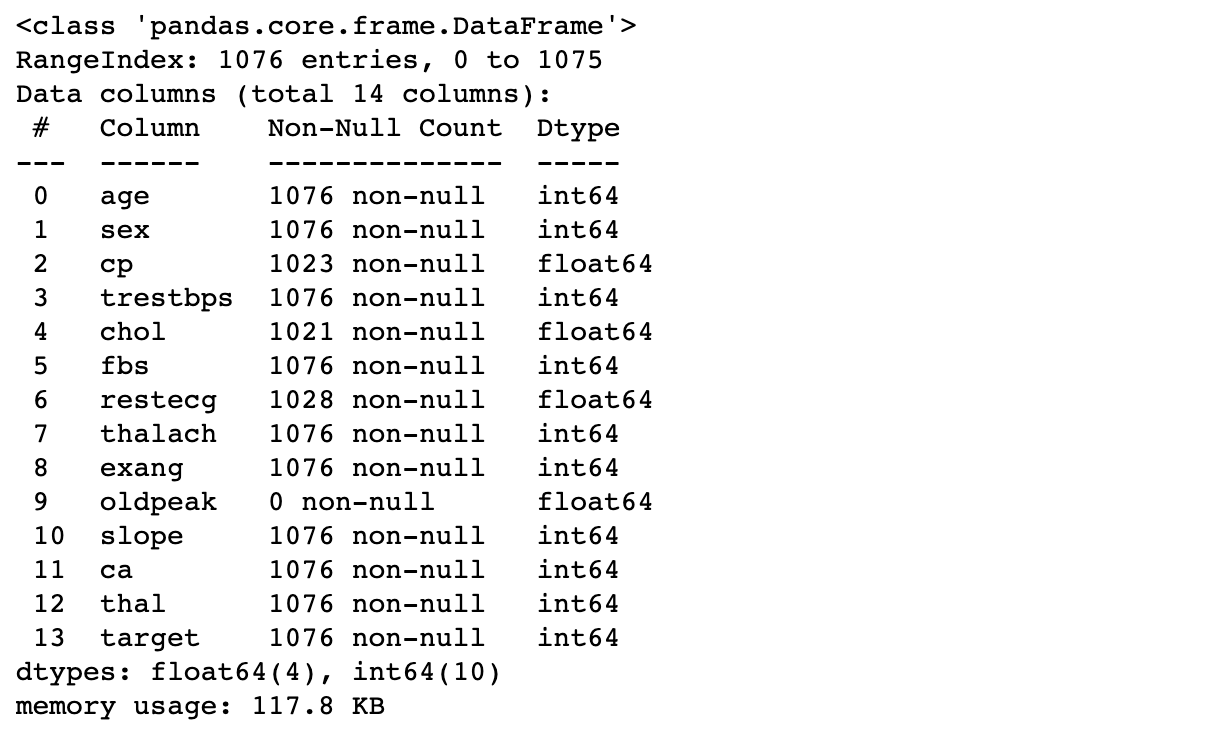
df.info()
- Resume las features
- Muestra entradas no nulas y tipos
# Print out details
print(heart_disease_df.info())
(Des)balance de clases
df.value_counts()
- Cuenta ocurrencias únicas por clase
- Clase: presencia binaria de cardiopatía (1/0)
- Importante para modelado
# print the class balance
print(heart_disease_df['target'].value_counts(normalize=True))

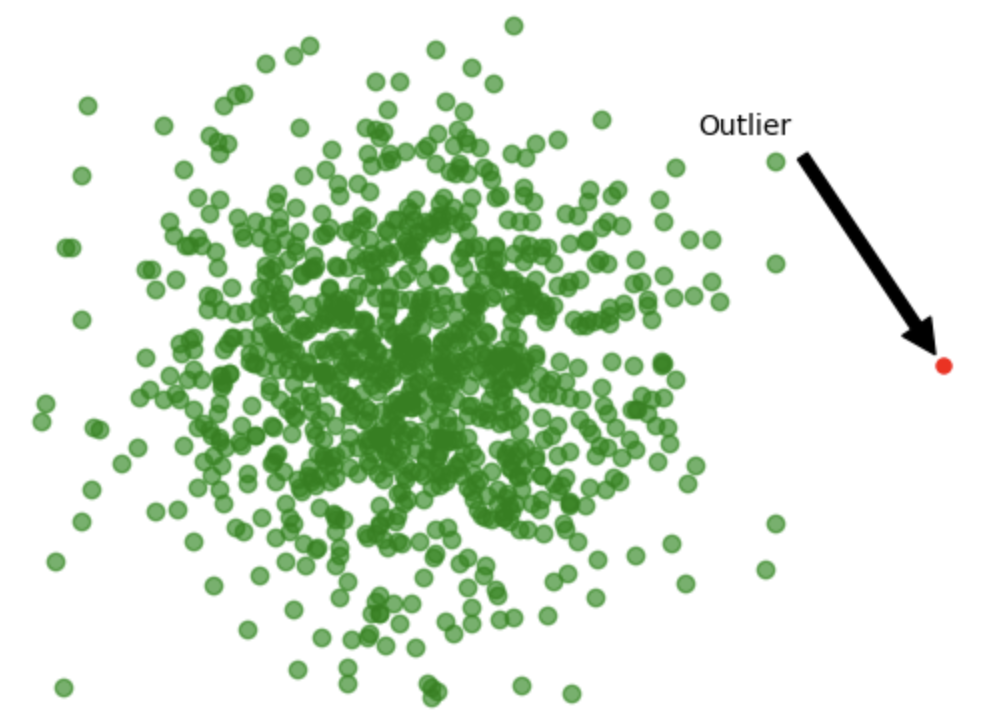
Valores atípicos
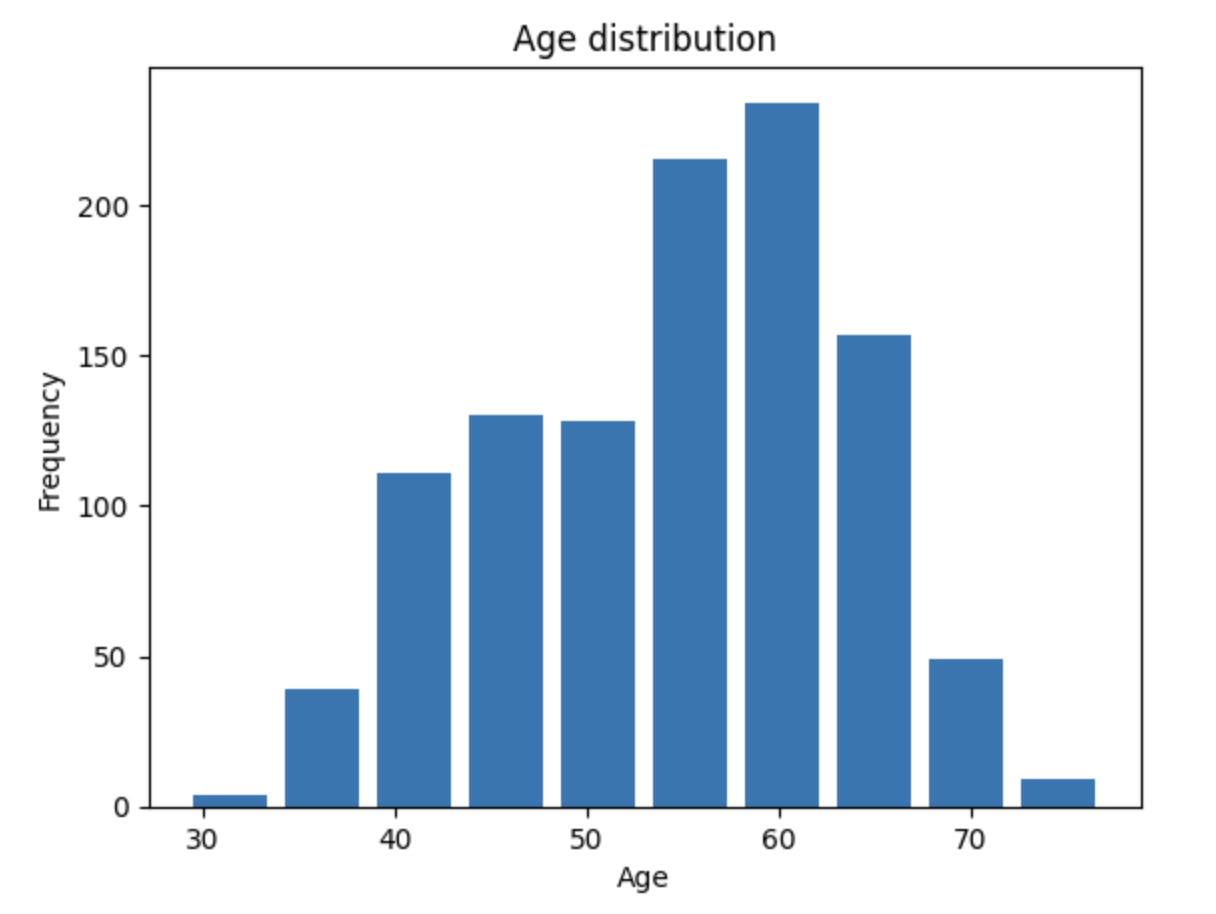
Visualizar los datos
df['age'].plot(kind='hist')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
1 https://seaborn.pydata.org/tutorial/distributions.html, https://app.datacamp.com/learn/courses/intermediate-data-visualization-with-seaborn

