Deriva de datos
Machine Learning de extremo a extremo

Joshua Stapleton
Machine Learning Engineer
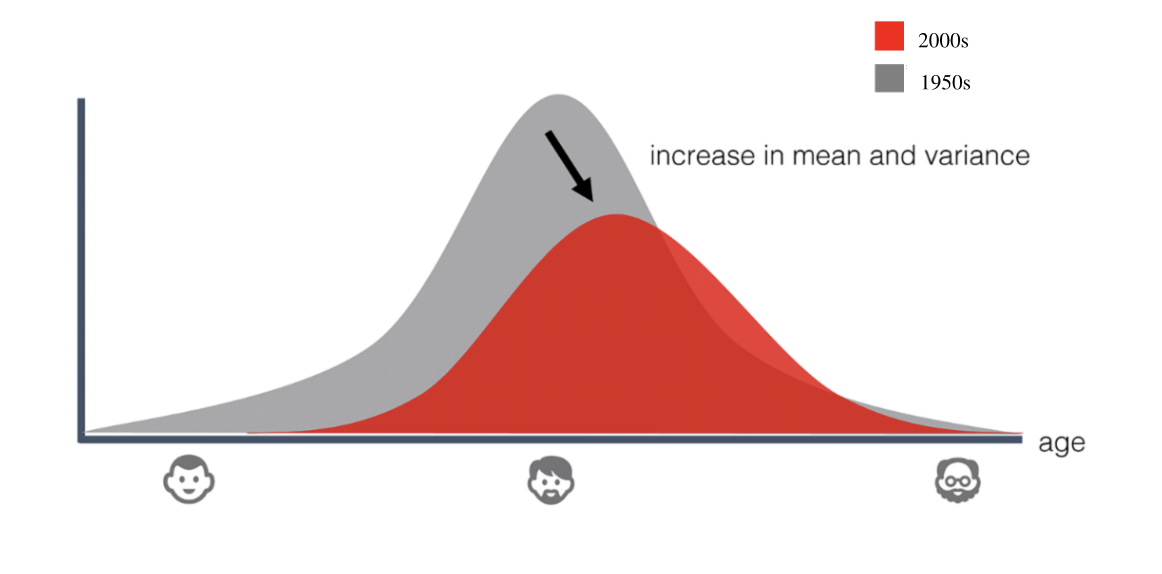
La necesidad de detectar deriva de datos
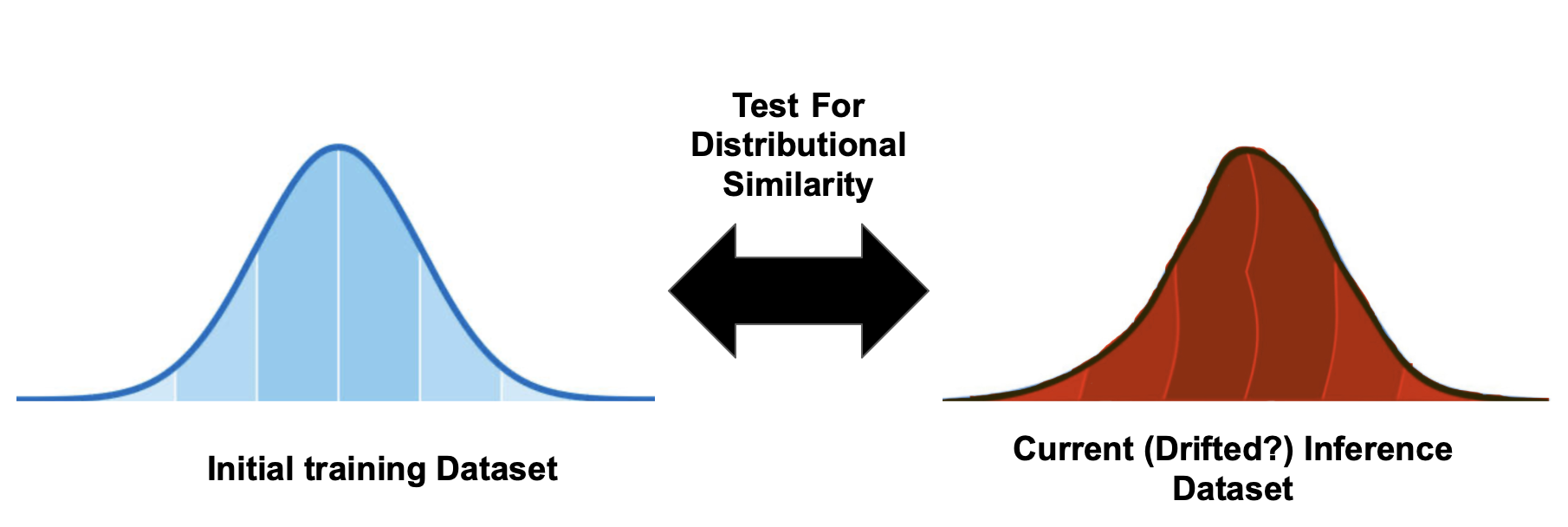
Prueba de Kolmogórov-Smirnov
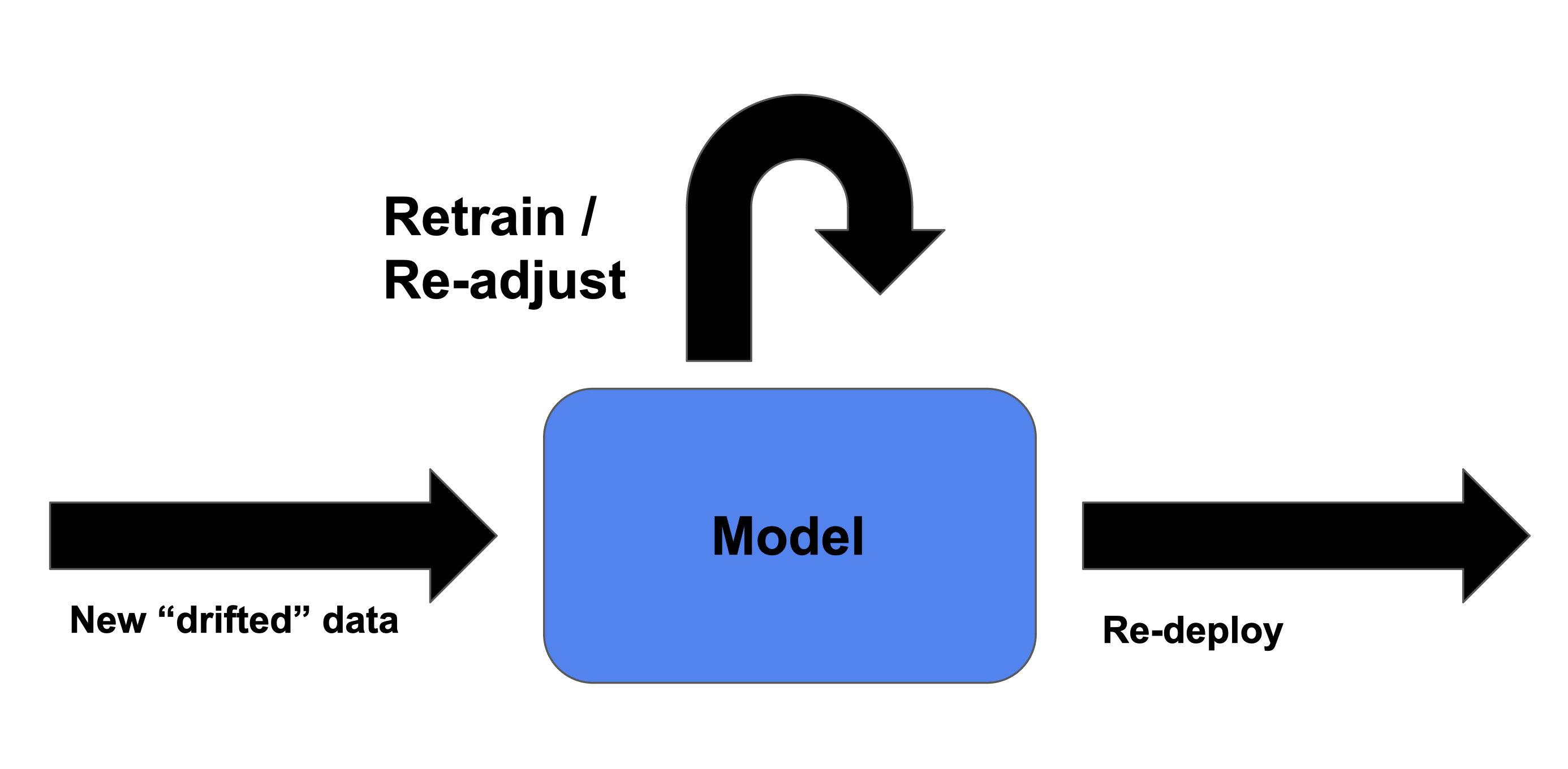
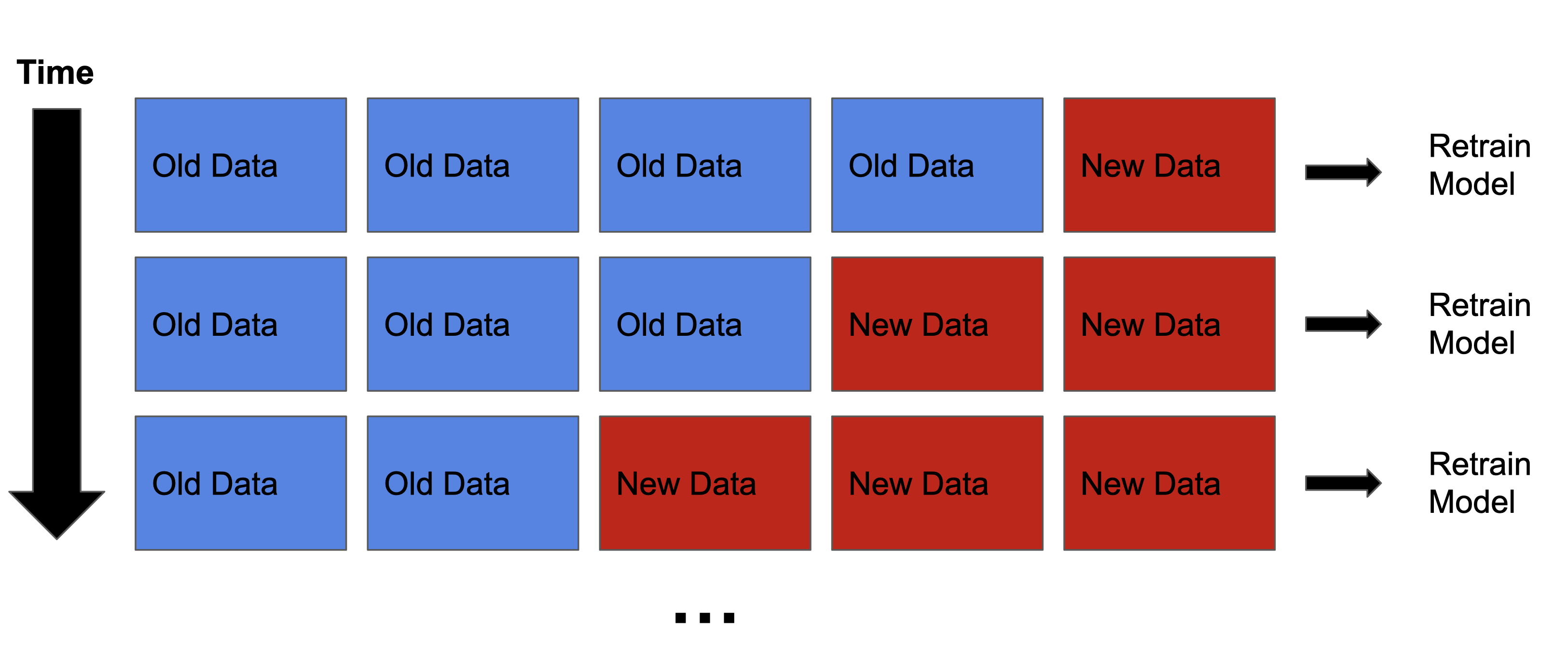
Corregir la deriva de datos
Machine Learning de extremo a extremo
Joshua Stapleton
Machine Learning Engineer

