Evaluación y visualización de modelos
Machine Learning de extremo a extremo

Joshua Stapleton
Machine Learning Engineer
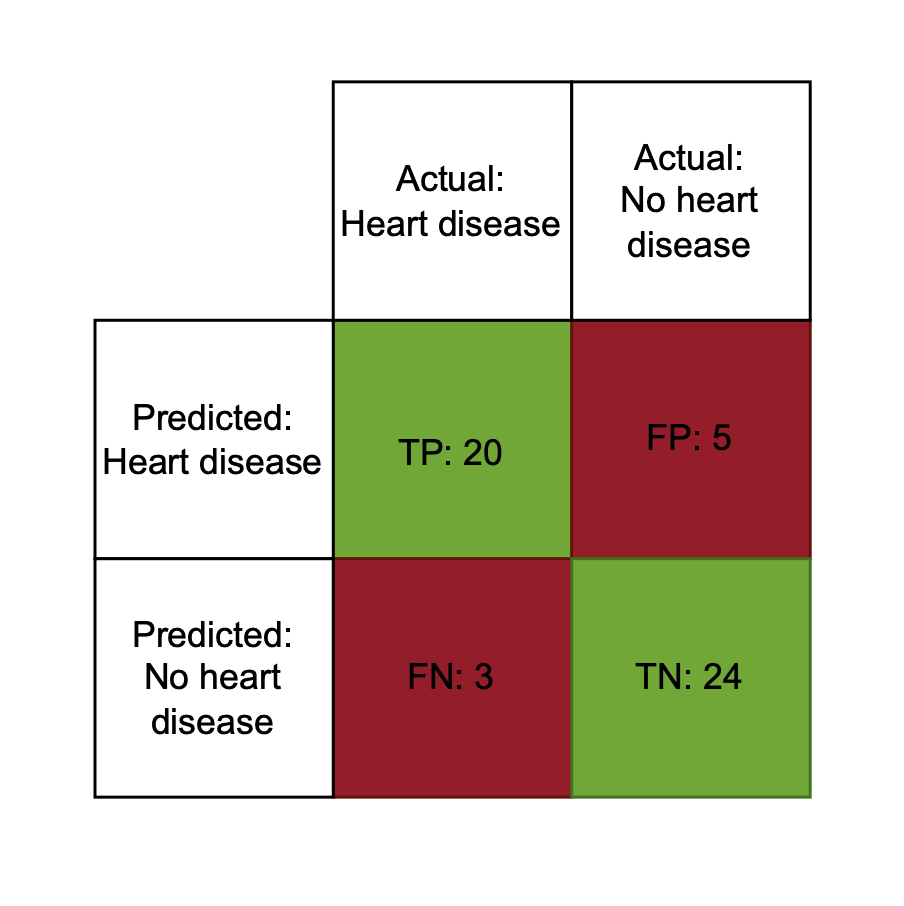
Uso de la matriz de confusión
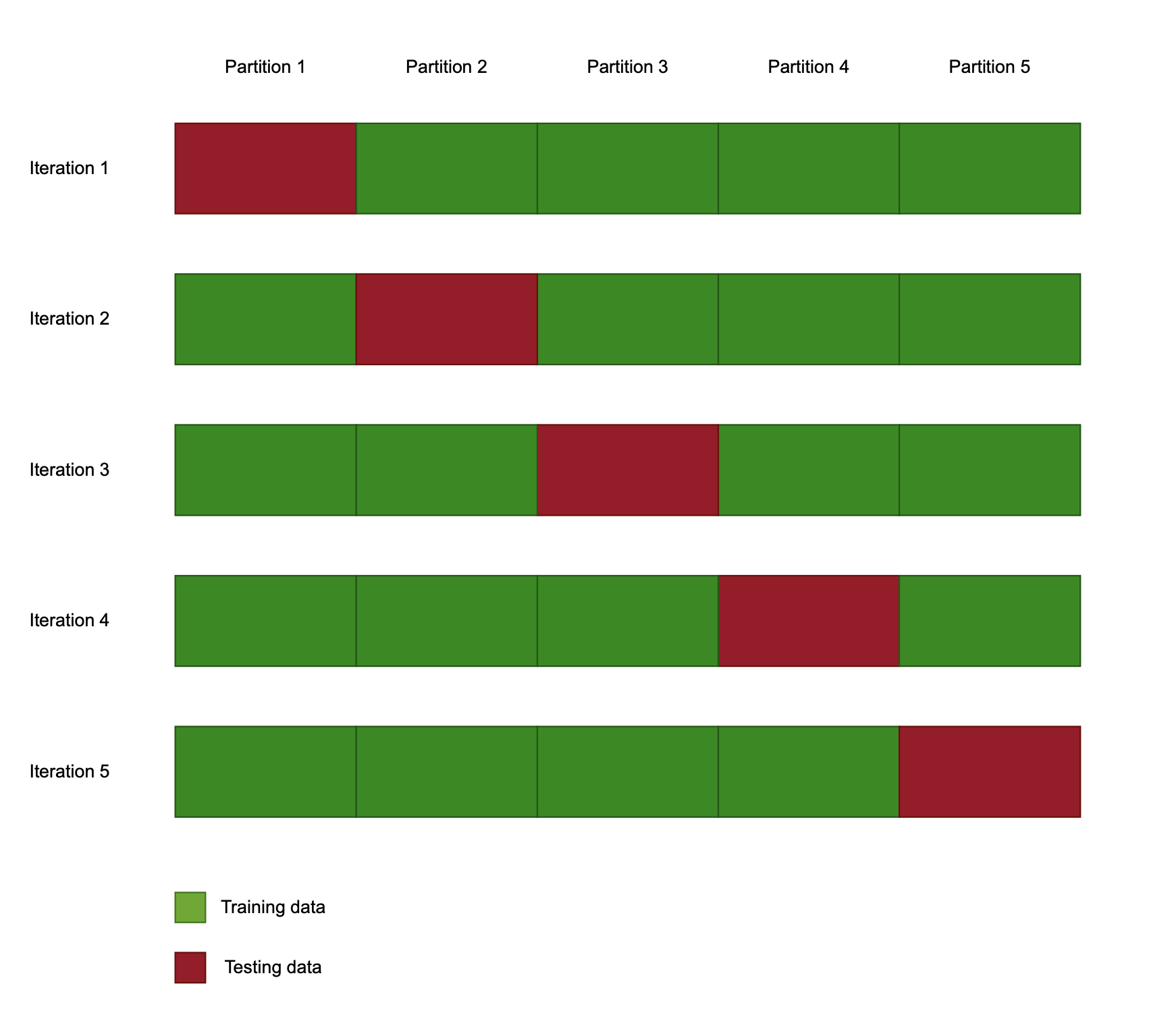
Validación cruzada
Machine Learning de extremo a extremo
Joshua Stapleton
Machine Learning Engineer

