Métodos Monte Carlo
Reinforcement Learning con Gymnasium en Python

Fouad Trad
Machine Learning Engineer
Repaso: aprendizaje con modelo
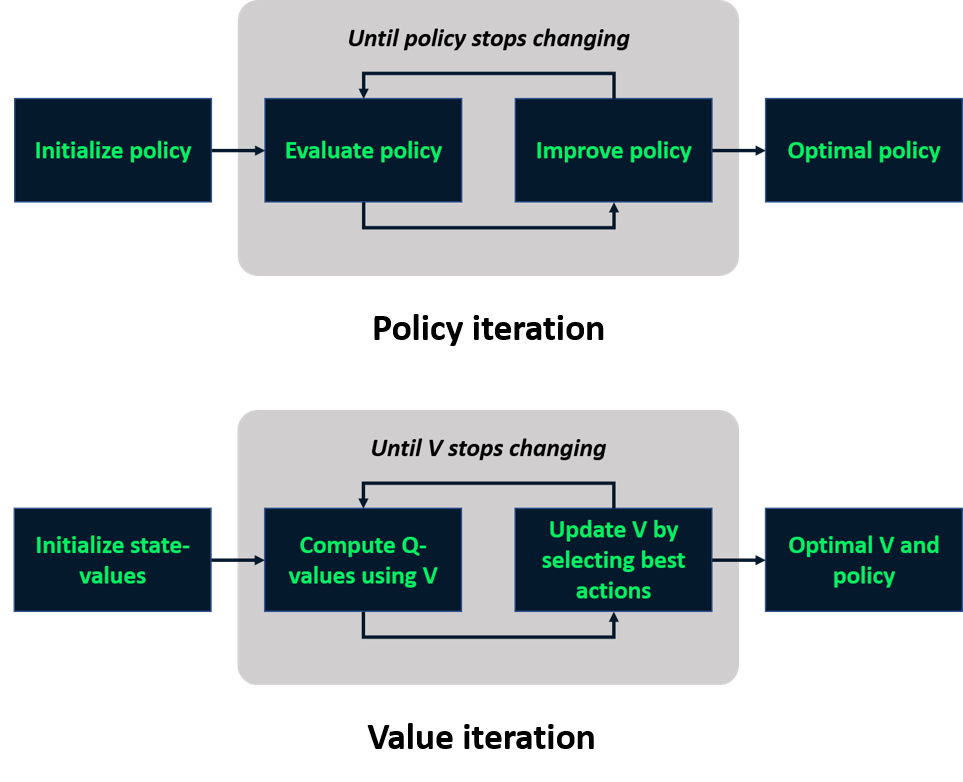
Aprendizaje sin modelo

Métodos Monte Carlo
- Técnicas sin modelo
- Estiman Q a partir de episodios
Métodos Monte Carlo
- Técnicas sin modelo
- Estiman Q a partir de episodios

Métodos Monte Carlo
- Técnicas sin modelo
- Estiman Q a partir de episodios

- Dos métodos: first-visit, every-visit
Grid world personalizado
Recoger dos episodios
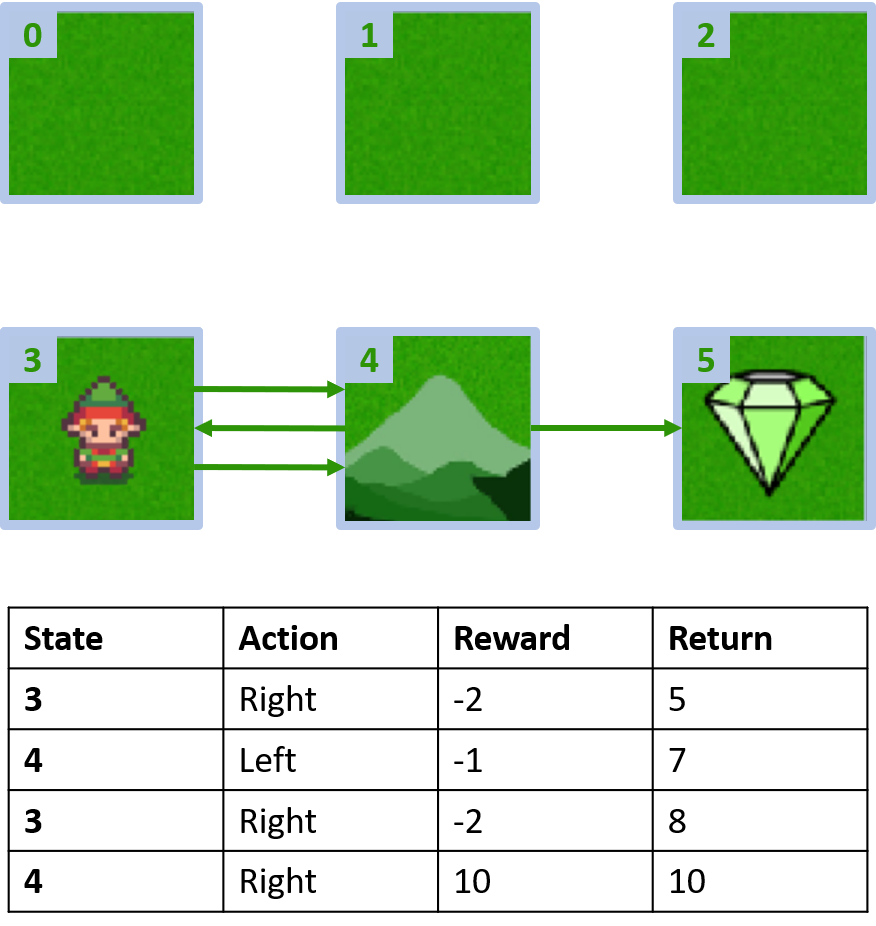
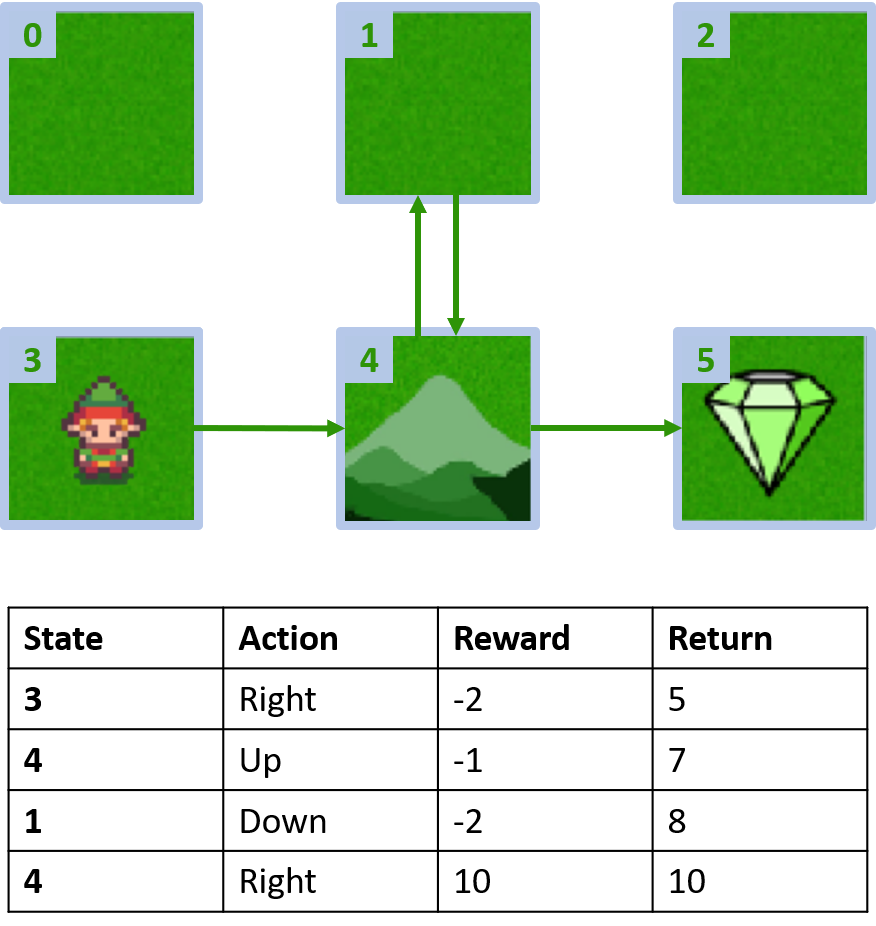
Estimación de Q-values
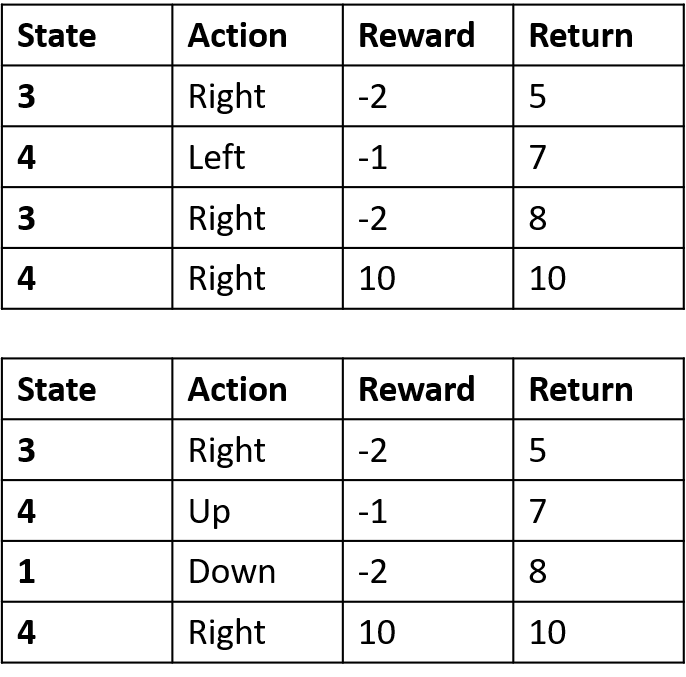
- Q-table: tabla de valores Q
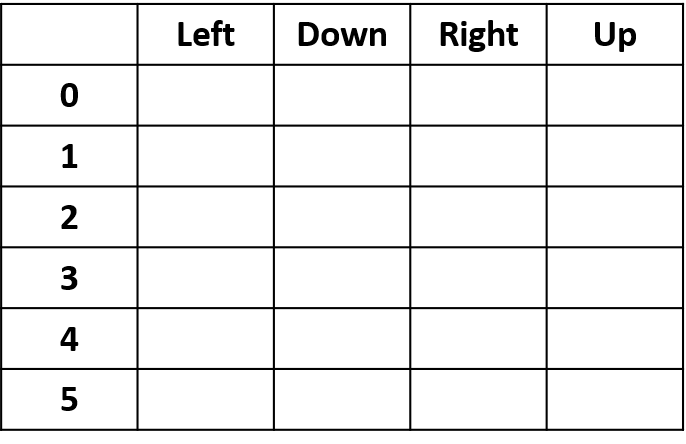
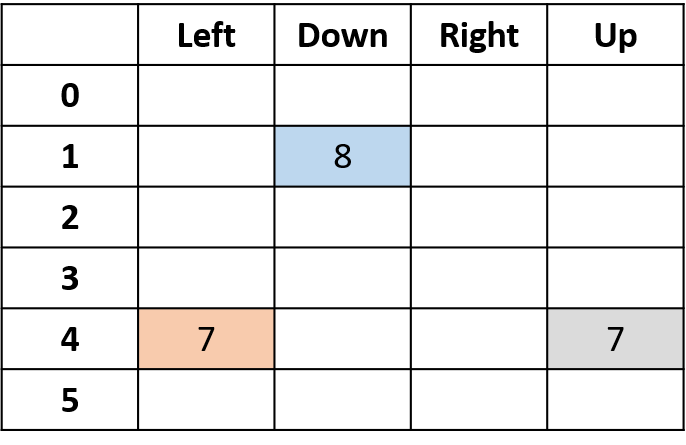
Q(4, izquierda), Q(4, arriba) y Q(1, abajo)
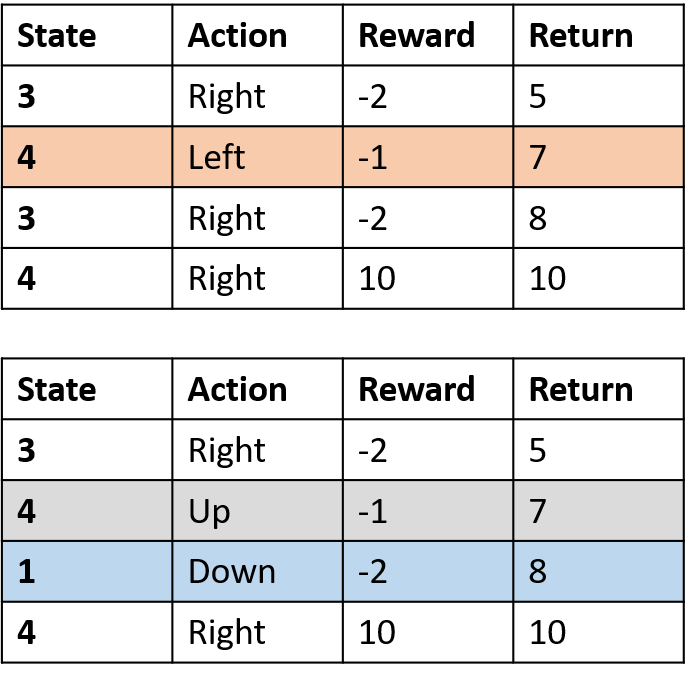
- (s,a) aparece una vez -> rellena con el retorno
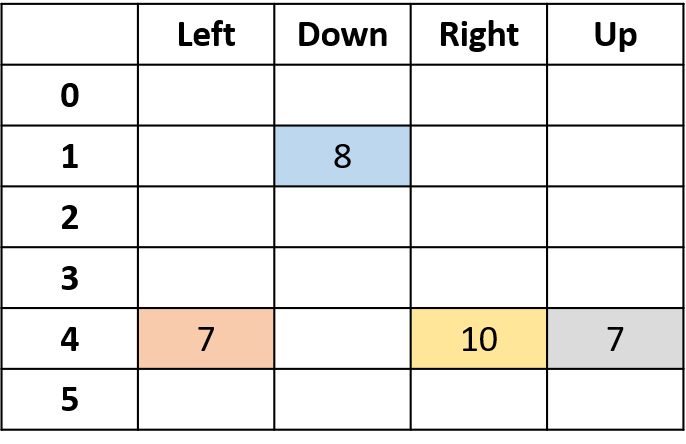
Q(4, derecha)
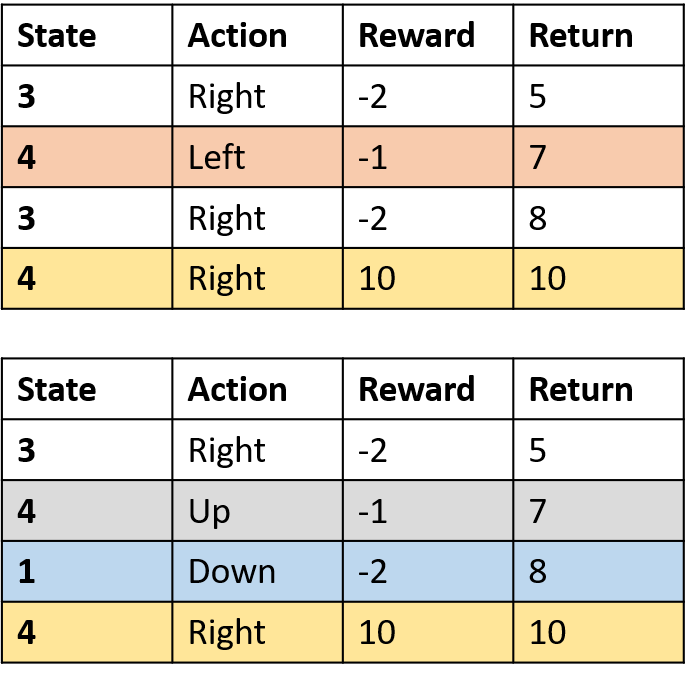
- (s,a) ocurre una vez por episodio -> promedio
Q(3, derecha) - Monte Carlo de primera visita
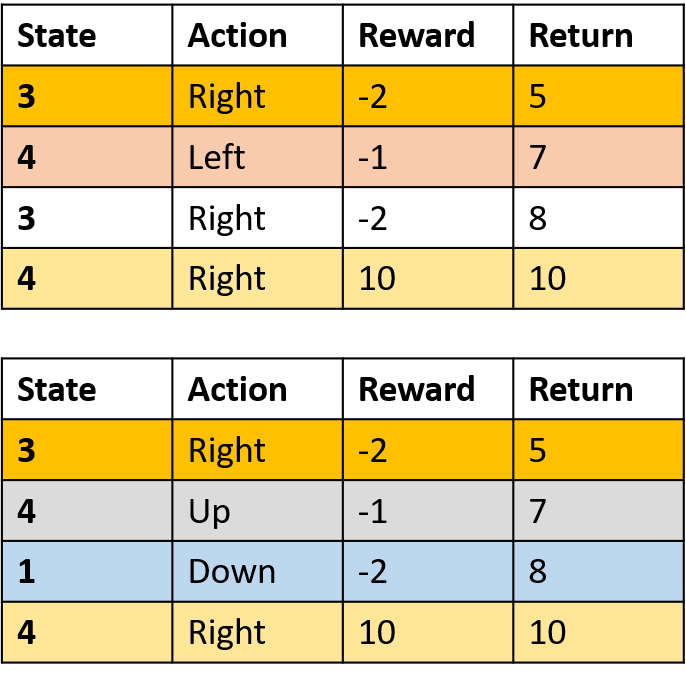
- Promedia la primera visita a (s,a) en cada episodio
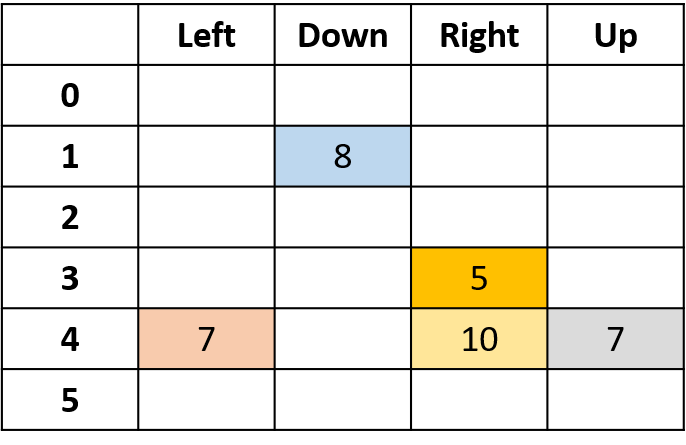
Q(3, derecha) - Monte Carlo de cada visita
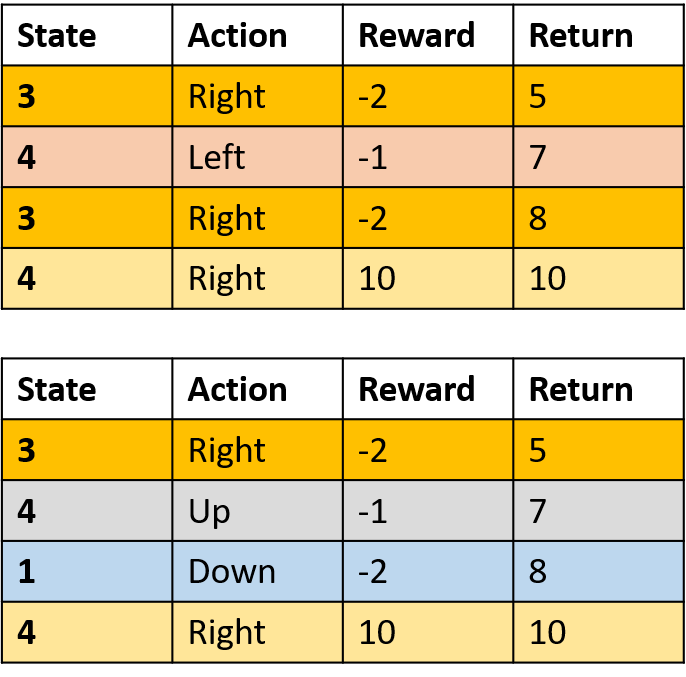
- Promedia cada visita a (s,a) en los episodios
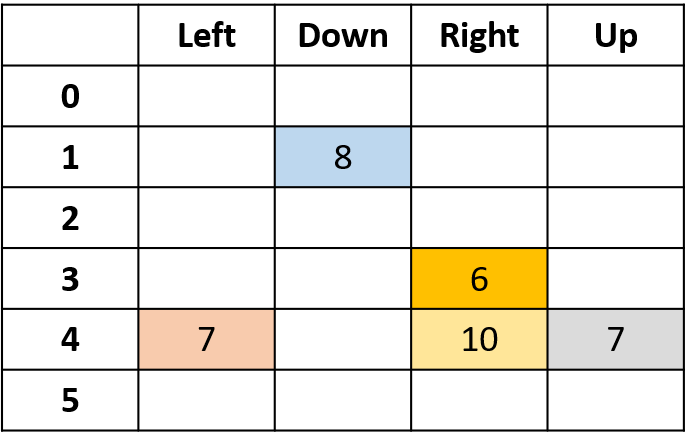
Juntándolo todo