Procesos de decisión de Markov
Reinforcement Learning con Gymnasium en Python

Fouad Trad
Machine Learning Engineer
MDP
- Modela matemáticamente los entornos de RL

MDP
- Modela matemáticamente los entornos de RL

Propiedad de Markov
- El estado futuro depende solo del estado actual y la acción

Frozen Lake como MDP
- El agente debe llegar a la meta sin caer en agujeros

Frozen Lake como MDP - estados
- Posiciones que el agente puede ocupar

Frozen Lake como MDP - estados terminales
- Llevan a terminar el episodio
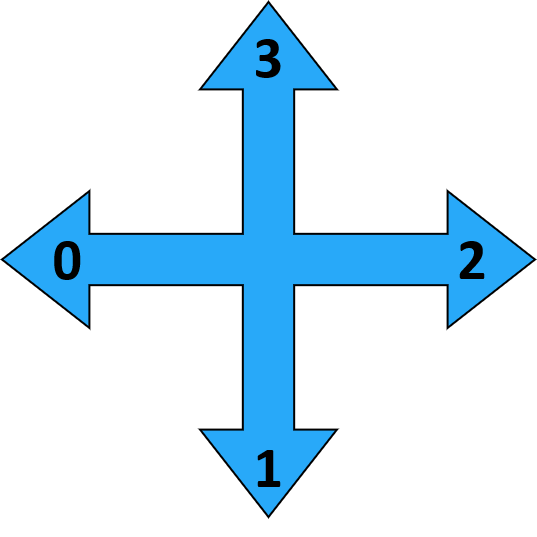
Frozen Lake como MDP - acciones
- Arriba, abajo, izquierda, derecha
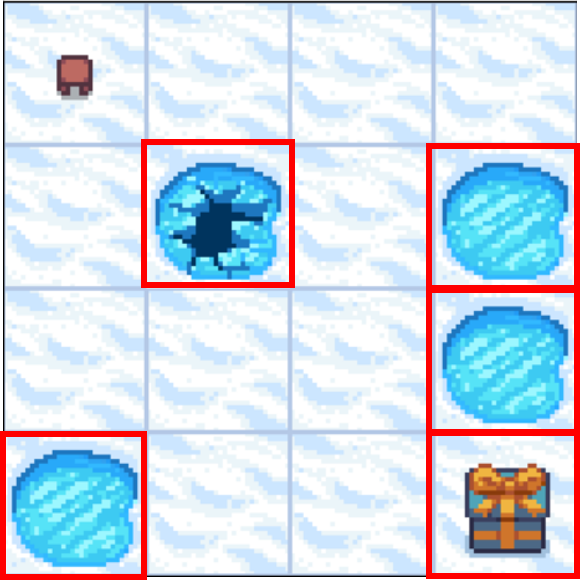
Frozen Lake como MDP - transiciones
- Las acciones no siempre dan el resultado esperado
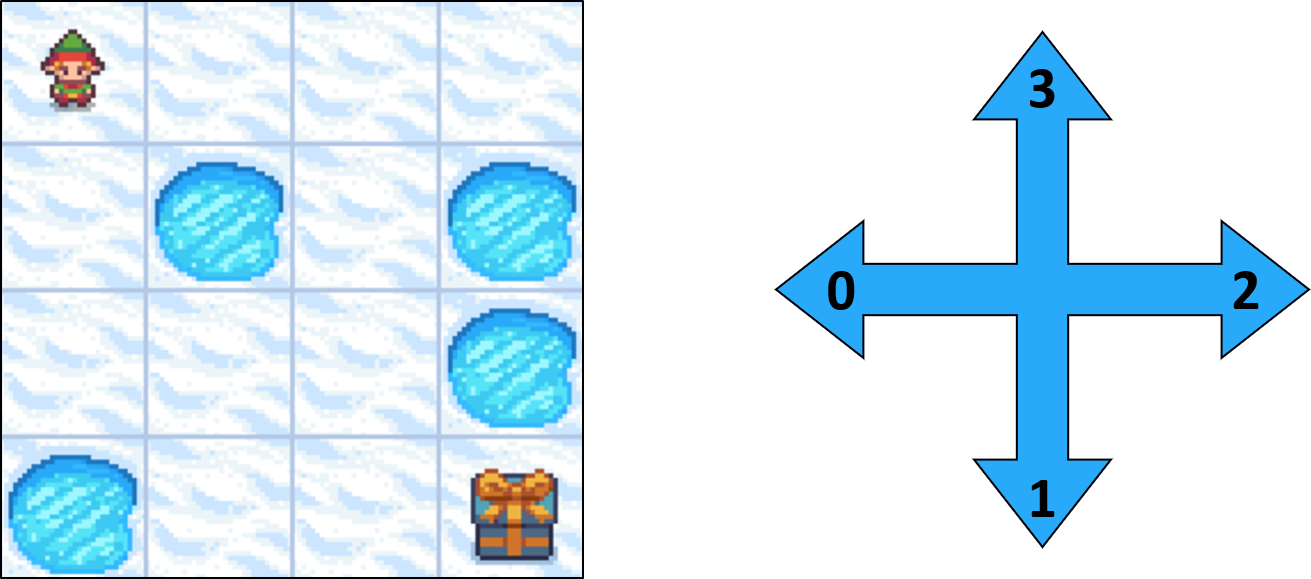
Frozen Lake como MDP - transiciones
- Las acciones no siempre dan el resultado esperado
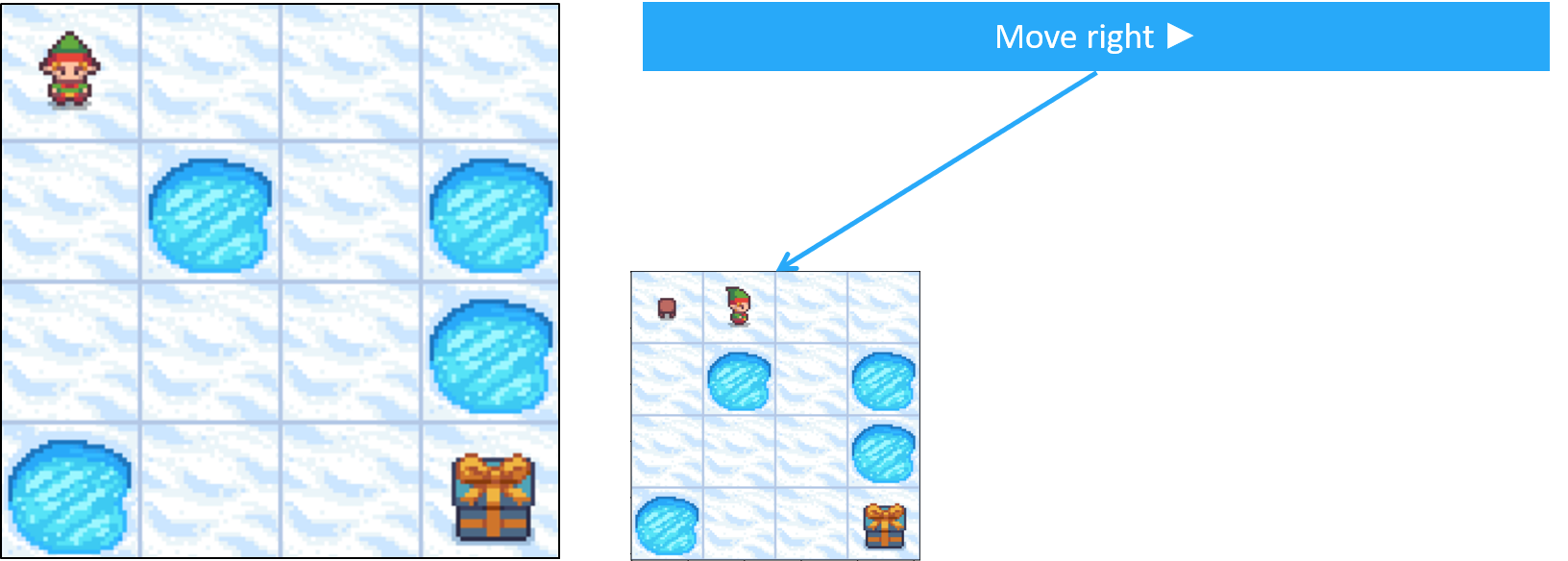
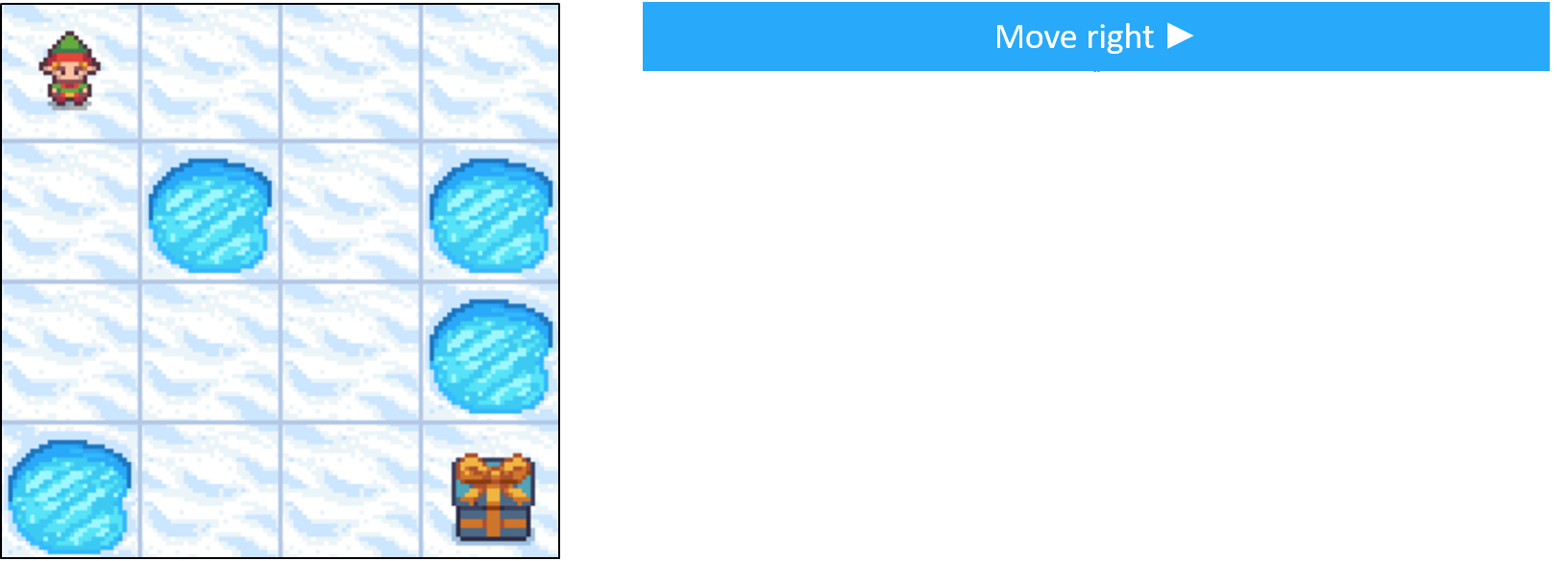
Frozen Lake como MDP - transiciones
- Las acciones no siempre dan el resultado esperado
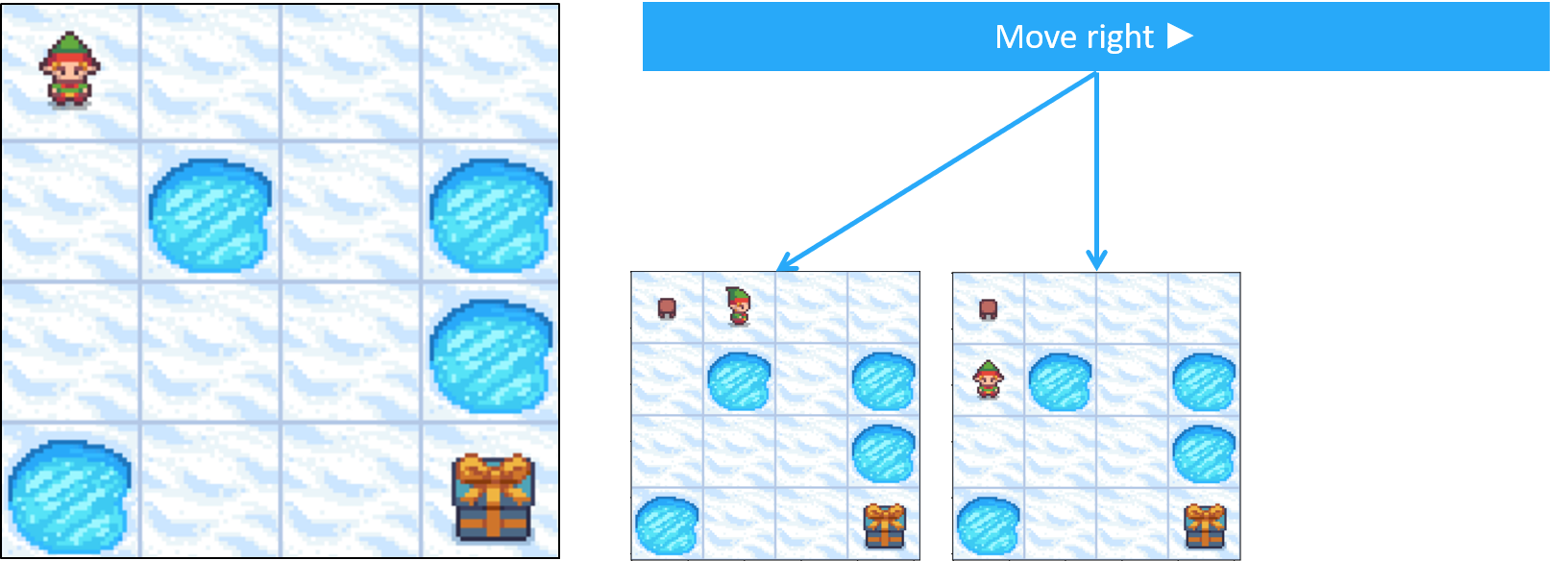
Frozen Lake como MDP - transiciones
- Las acciones no siempre dan el resultado esperado
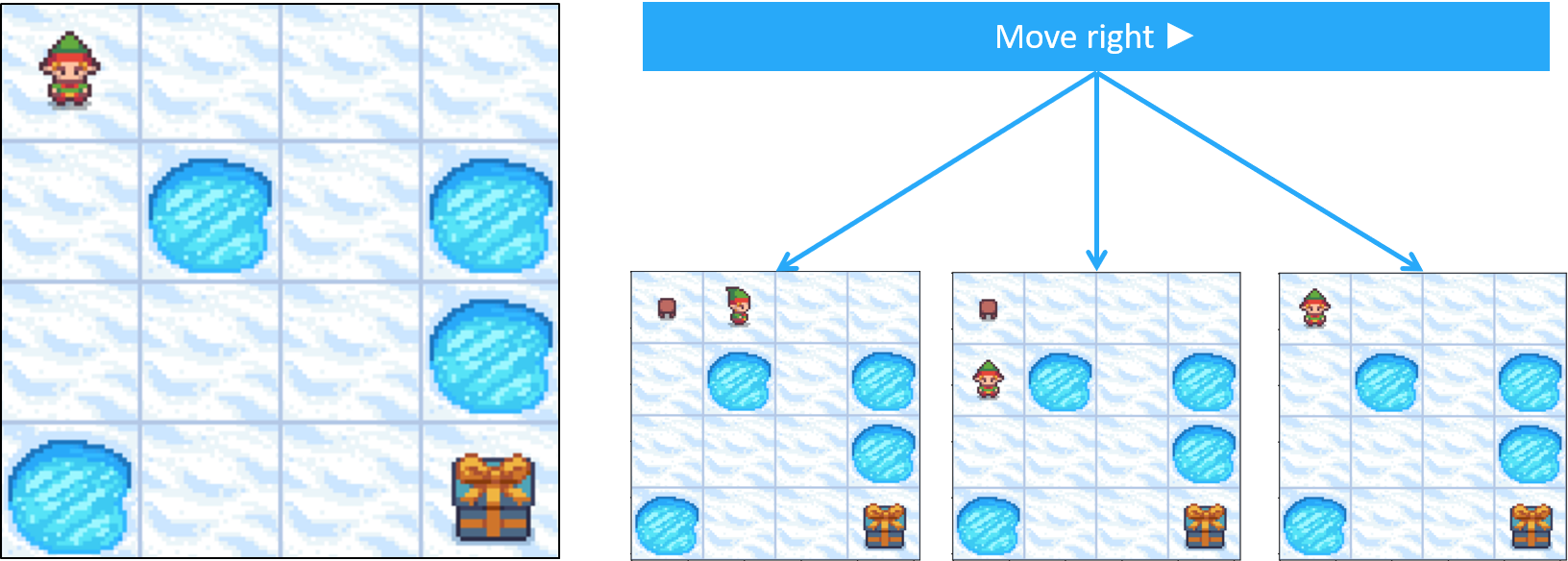
Frozen Lake como MDP - transiciones
- Las acciones no siempre dan el resultado esperado
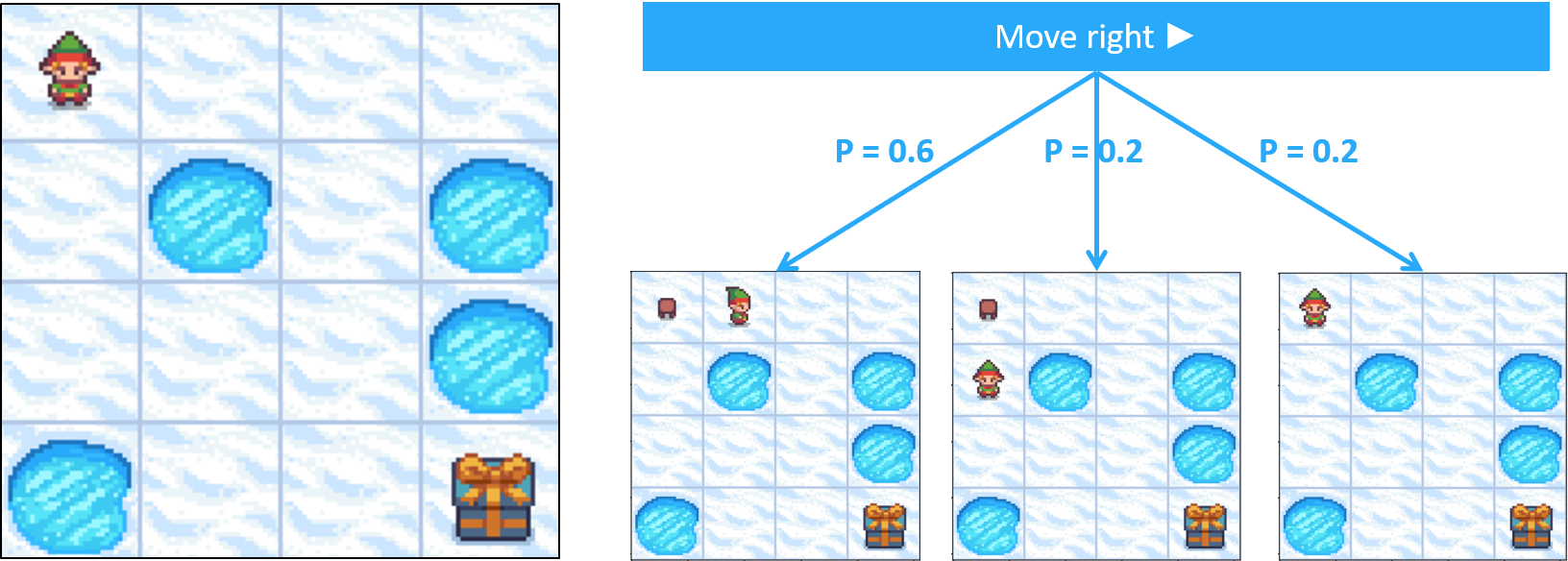
- Probabilidades de transición: probabilidad de llegar a un estado dado un estado y una acción
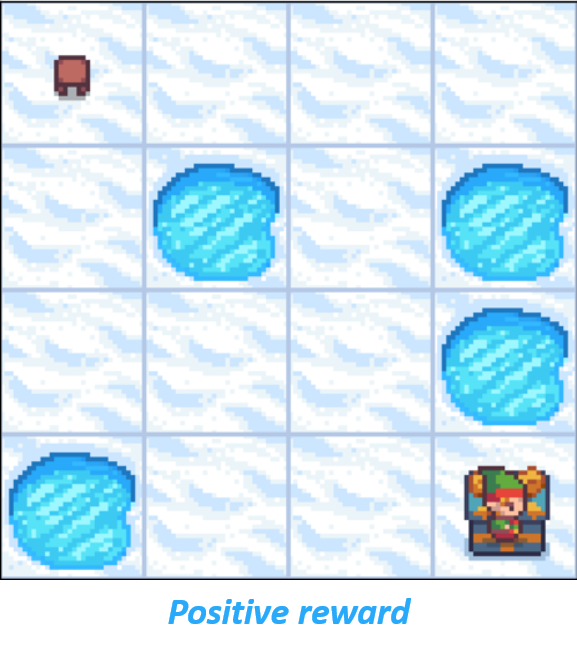
Frozen Lake como MDP - recompensas
- Recompensa solo en el estado objetivo
Recompensas y transiciones en Gymnasium - ejemplo
state = 6 action = 0print(env.unwrapped.P[state][action])
[(0.3333333333333333, 2, 0.0, False),
(0.3333333333333333, 5, 0.0, True),
(0.3333333333333333, 10, 0.0, False)]