Double Q-learning
Reinforcement Learning con Gymnasium en Python

Fouad Trad
Machine Learning Engineer
Q-learning
- Estima la función óptima de valor-acción
- Sobreestima Q al actualizar con el máximo Q
- Puede llevar a una política subóptima

Double Q-learning
- Mantiene dos tablas Q
- Cada tabla se actualiza a partir de la otra
- Reduce el riesgo de sobreestimar Q
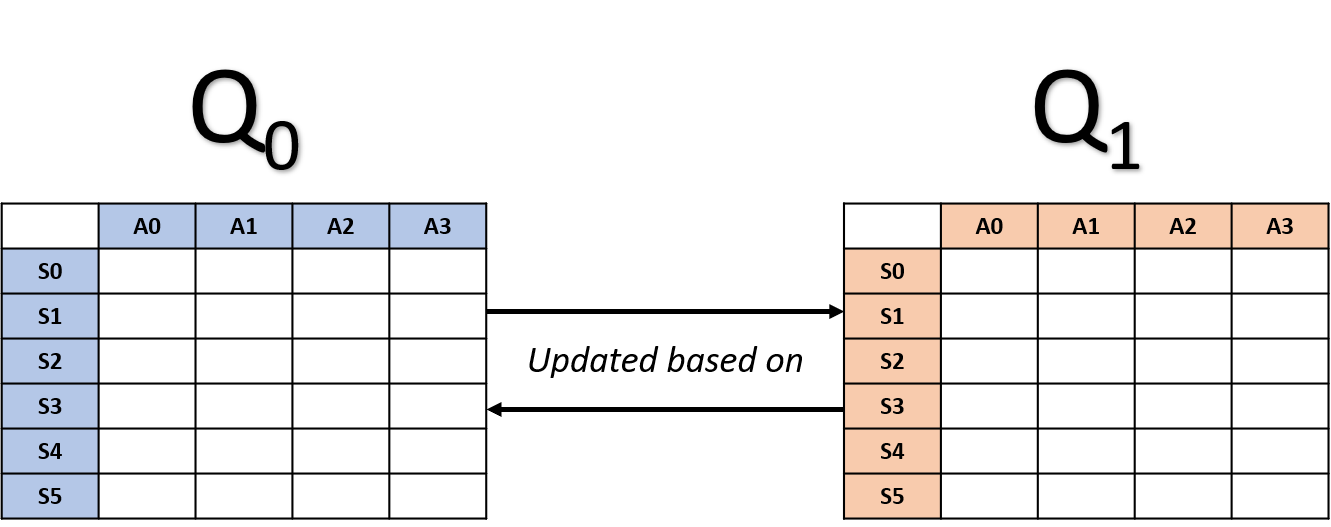
Actualizaciones en Double Q-learning
- Selecciona una tabla al azar
Actualización de Q0
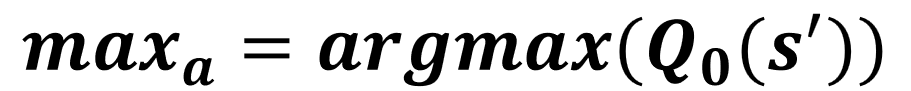
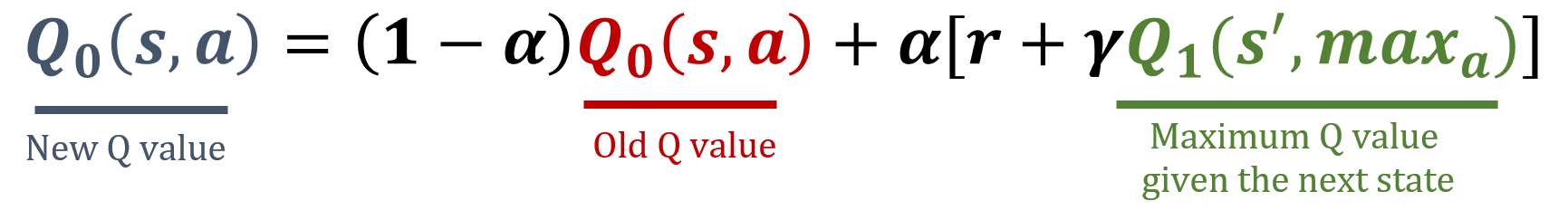
Actualización de Q1
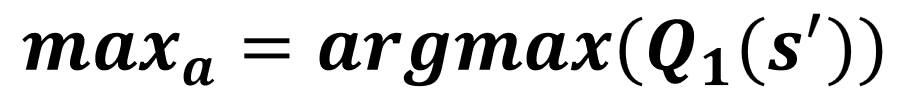
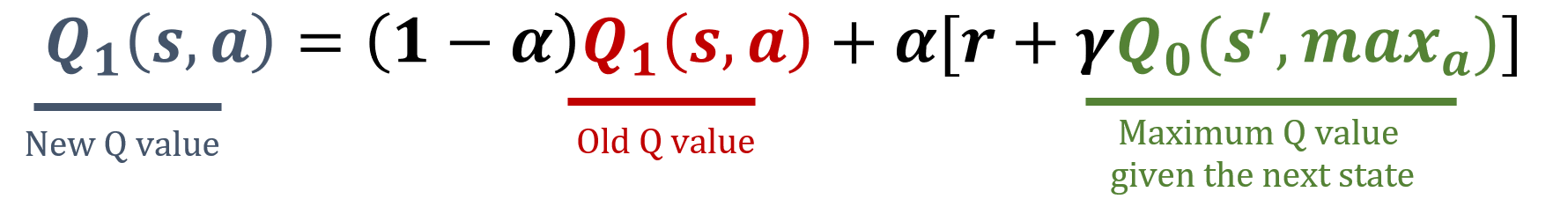
Double Q-learning
- Reduce el sesgo de sobreestimación
- Alterna actualizaciones entre Q0 y Q1
- Ambas tablas aportan al aprendizaje
Implementación con Frozen Lake

Implementar update_q_tables()
def update_q_tables(state, action, reward, next_state): # Select a random Q-table index (0 or 1) i = np.random.randint(2)# Update the corresponding Q-table best_next_action = np.argmax(Q[i][next_state])Q[i][state, action] = (1 - alpha) * Q[i][state, action] + alpha * (reward + gamma * Q[1-i][next_state, best_next_action])
Política del agente