Bandidos de varios brazos
Reinforcement Learning con Gymnasium en Python

Fouad Trad
Machine Learning Engineer
Bandidos de varios brazos

Tragaperras

- La recompensa de un brazo es 0 o 1
- Objetivo del agente → acumular la máxima recompensa
Resolver el problema
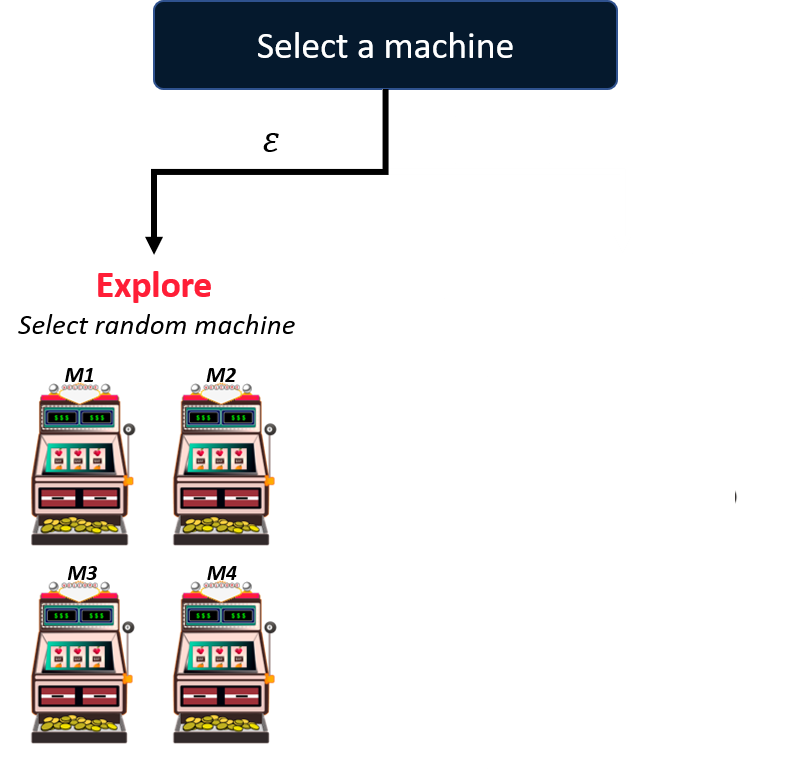
Resolver el problema

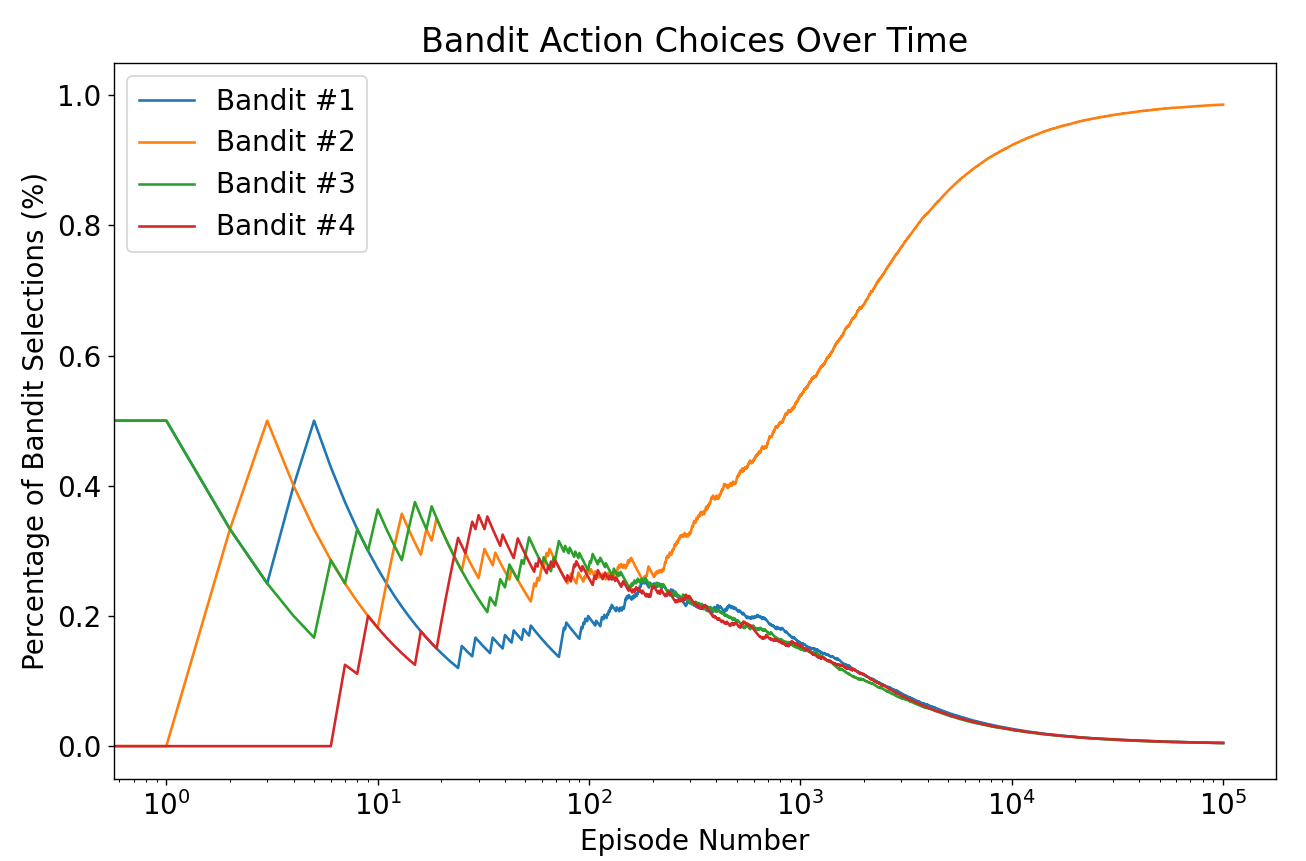
Analizar selecciones
selections_percentage = np.zeros((n_iterations, n_bandits))

Analizar selecciones
selections_percentage = np.zeros((n_iterations, n_bandits))for i in range(n_iterations): selections_percentage[i, selected_arms[i]] = 1
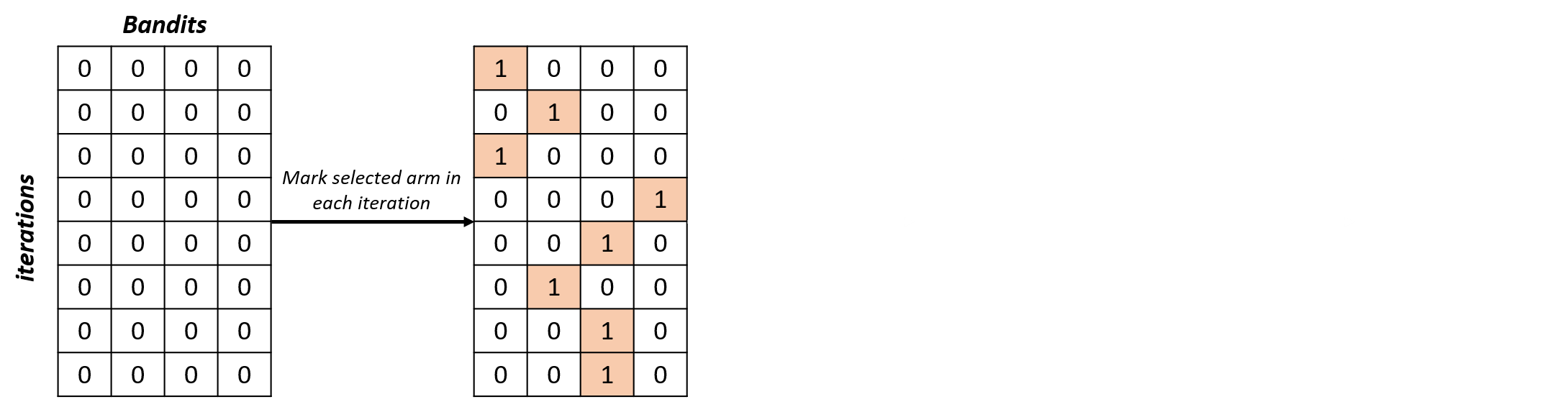
Analizar selecciones
selections_percentage = np.zeros((n_iterations, n_bandits))for i in range(n_iterations): selections_percentage[i, selected_arms[i]] = 1selections_percentage = np.cumsum(selections_percentage, axis=0) / np.arange(1, n_iterations + 1).reshape(-1, 1)
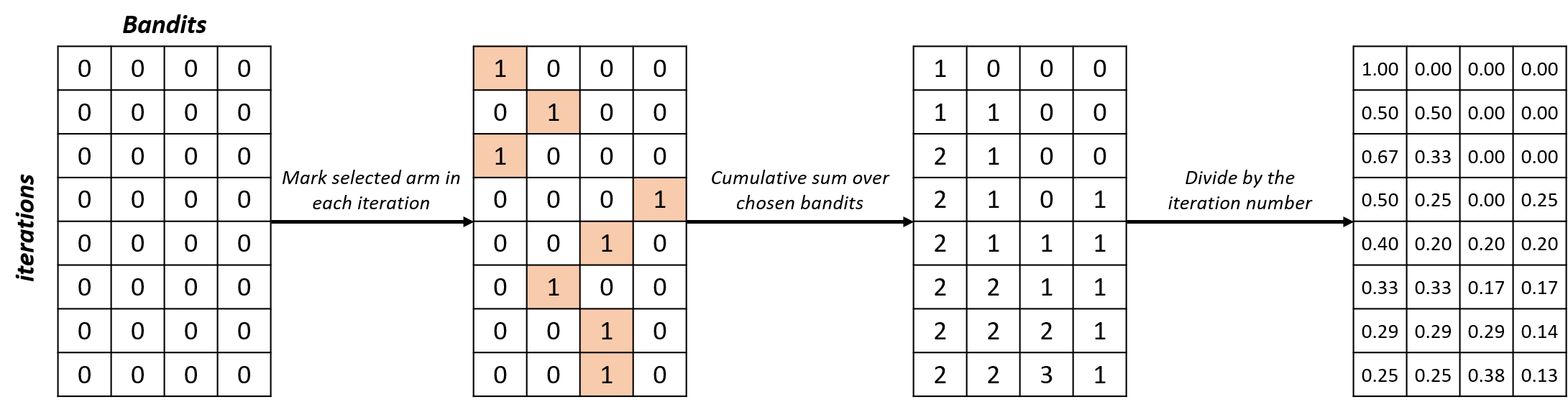
Analizar selecciones