Funciones valor-acción
Reinforcement Learning con Gymnasium en Python

Fouad Trad
Machine Learning Engineer
Funciones valor-acción (Q-valores)
- Retorno esperado de:
- Empezando en un estado $s$
- Tomando la acción $a$
- Siguiendo la política
- Estima la conveniencia de acciones dentro de estados
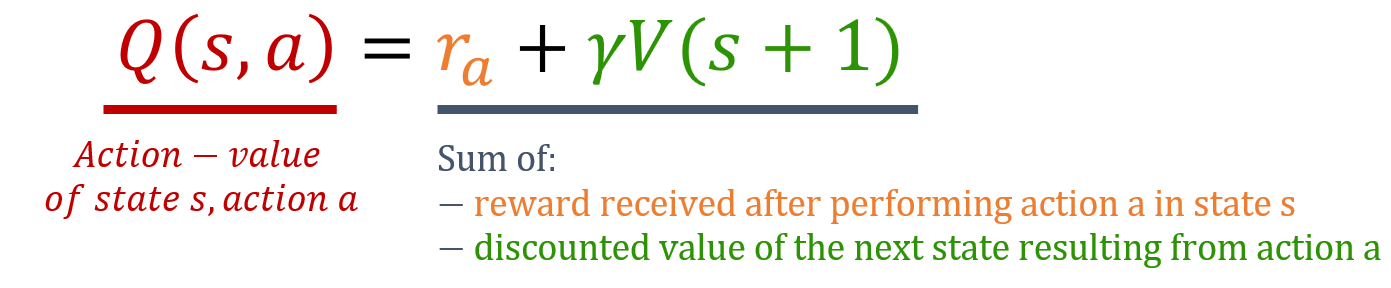
Mundo en cuadrícula

- Valores de estado
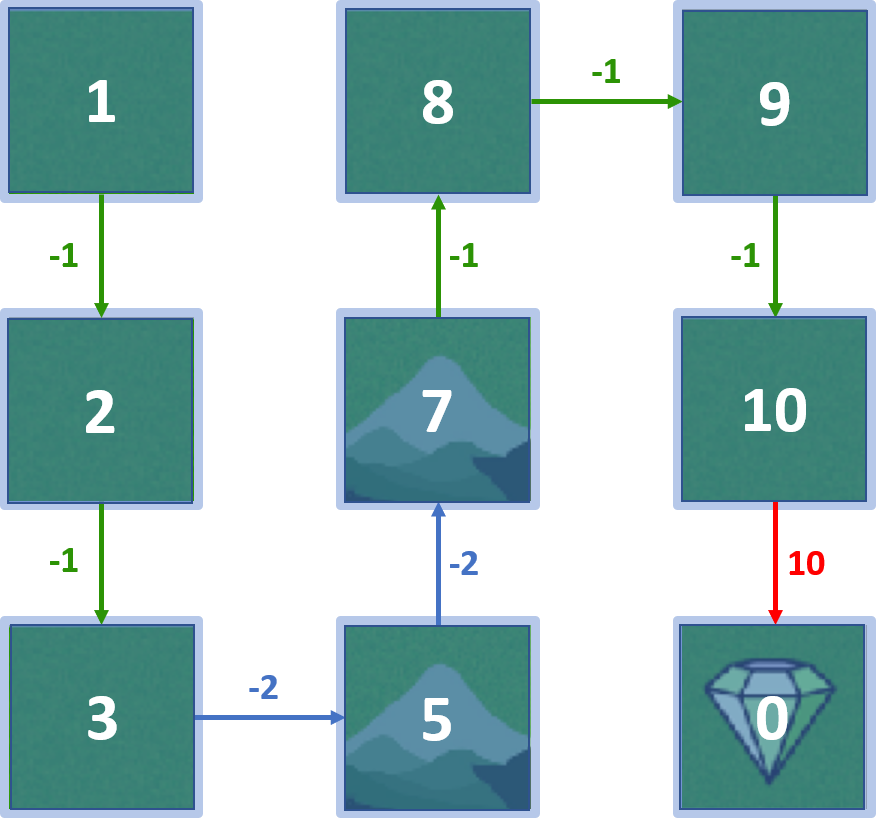
Q-valores - estado 4
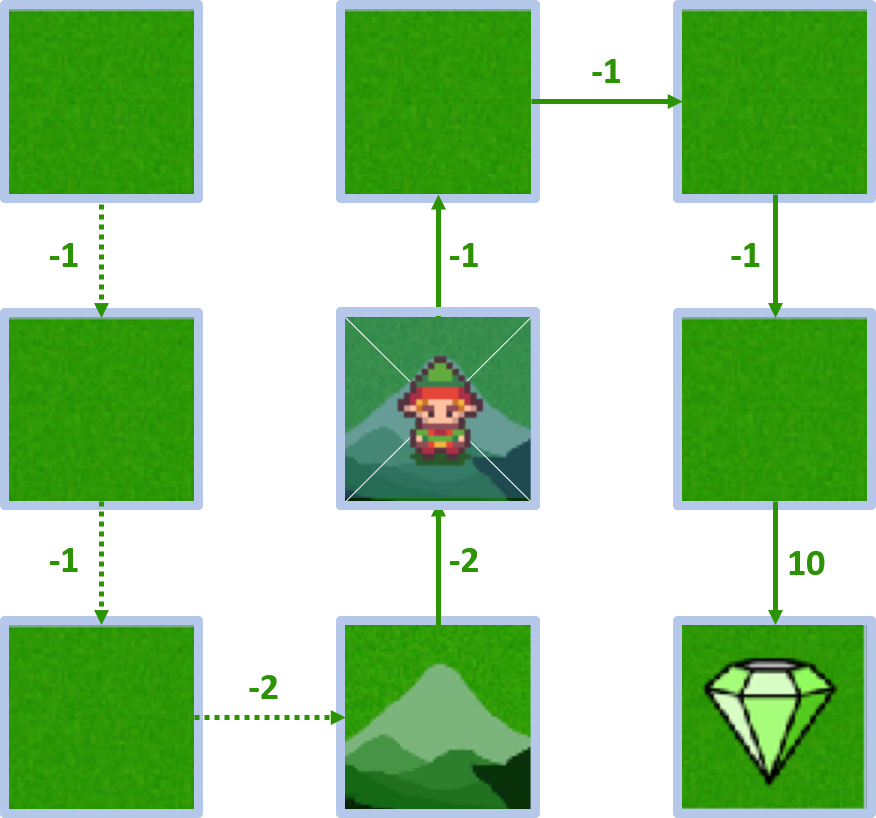
- Agente nace en el estado 4
Q-valores - estado 4
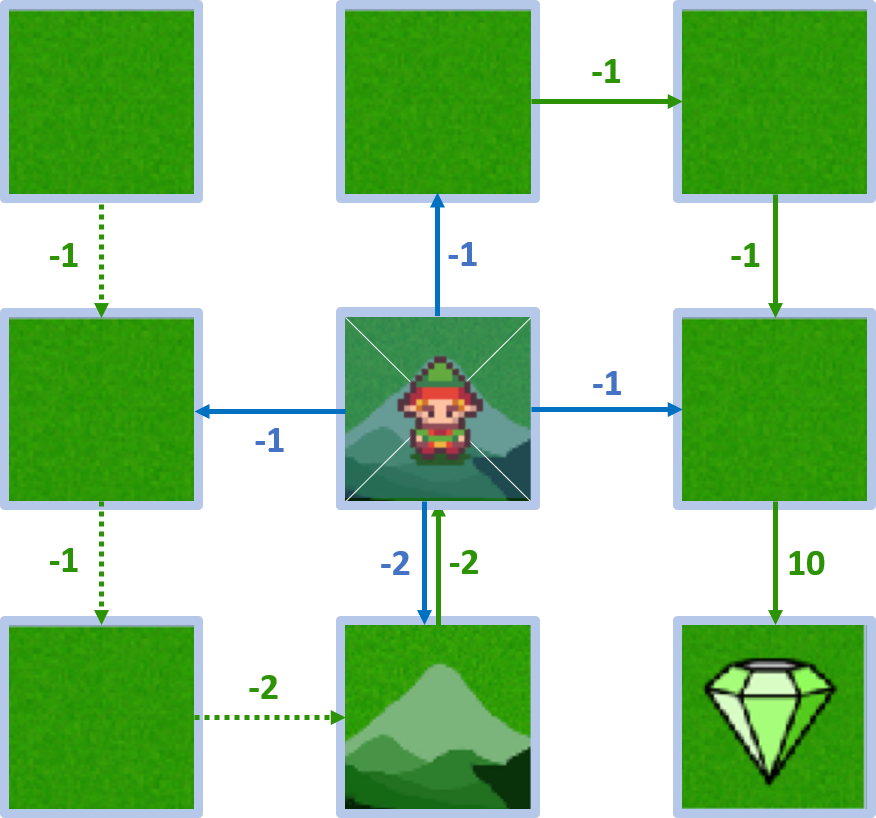
- El agente puede ir arriba, abajo, izquierda, derecha
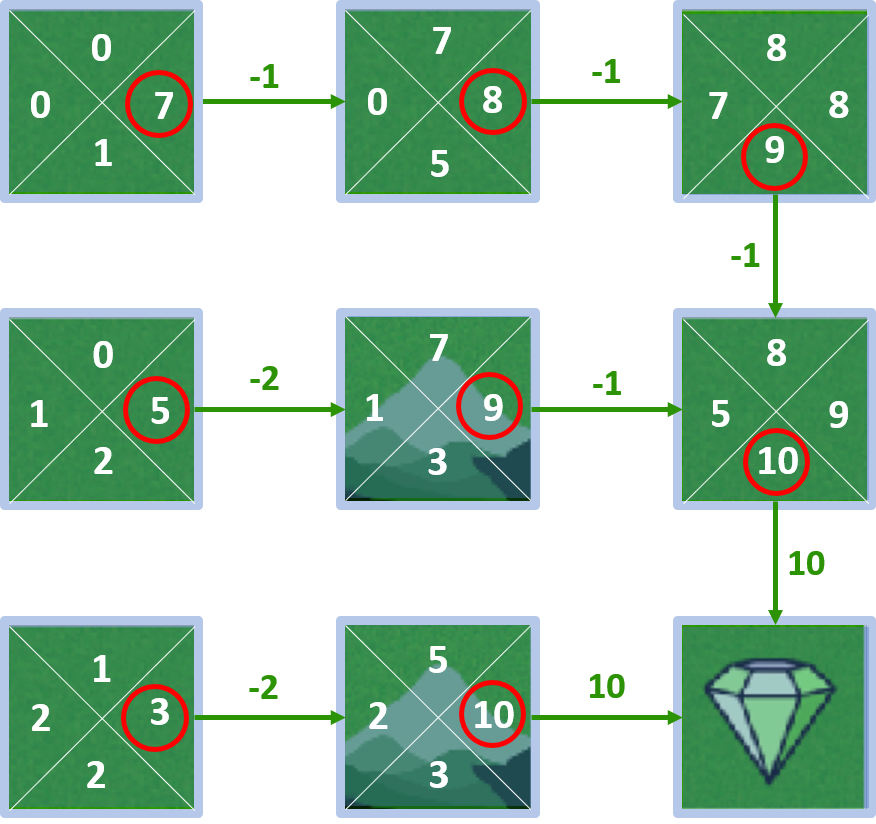
Estado 4 - acción abajo
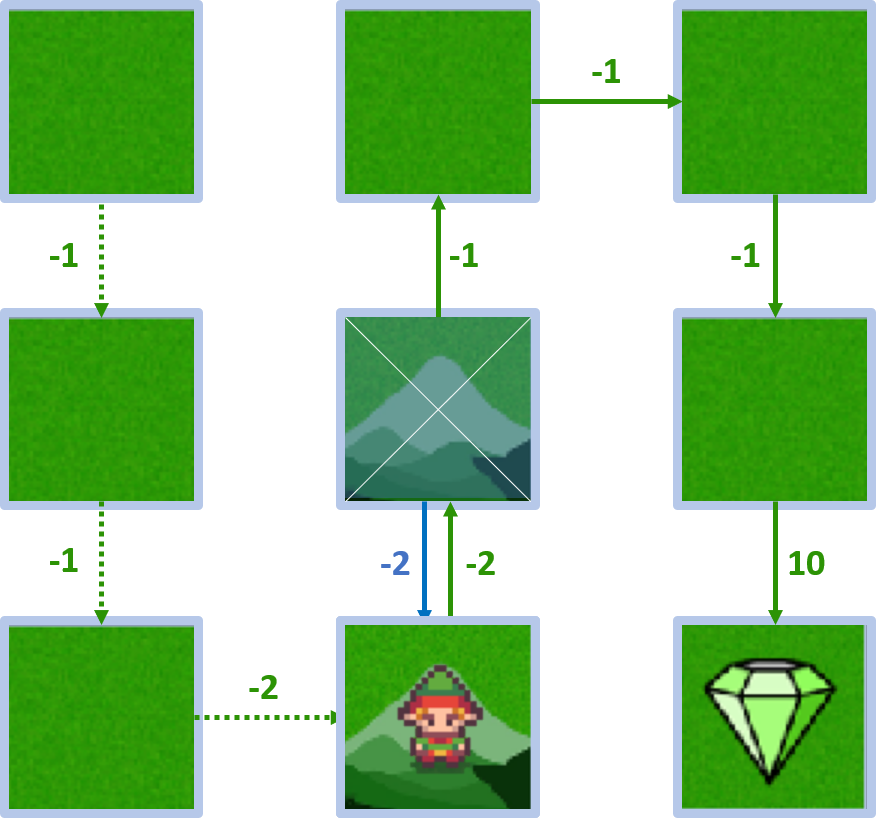
- Recompensa: -2, valor de estado: 5
Estado 4 - acción abajo
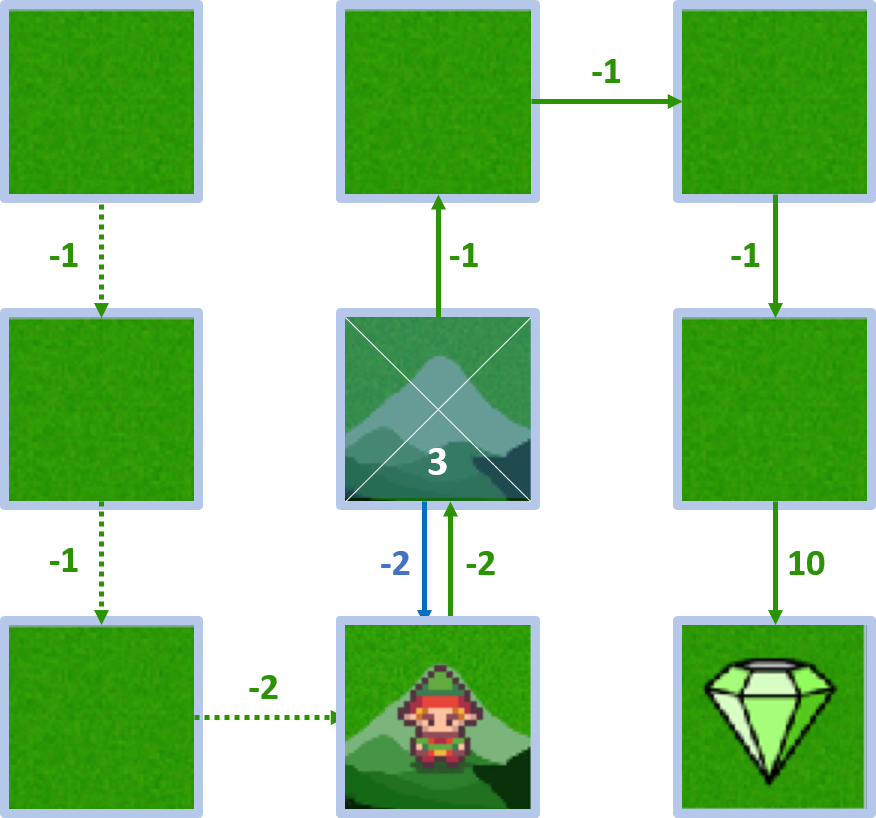
- $Q(4, \text{down}) = -2 + 1 \times 5 = 3$
Estado 4 - acción izquierda
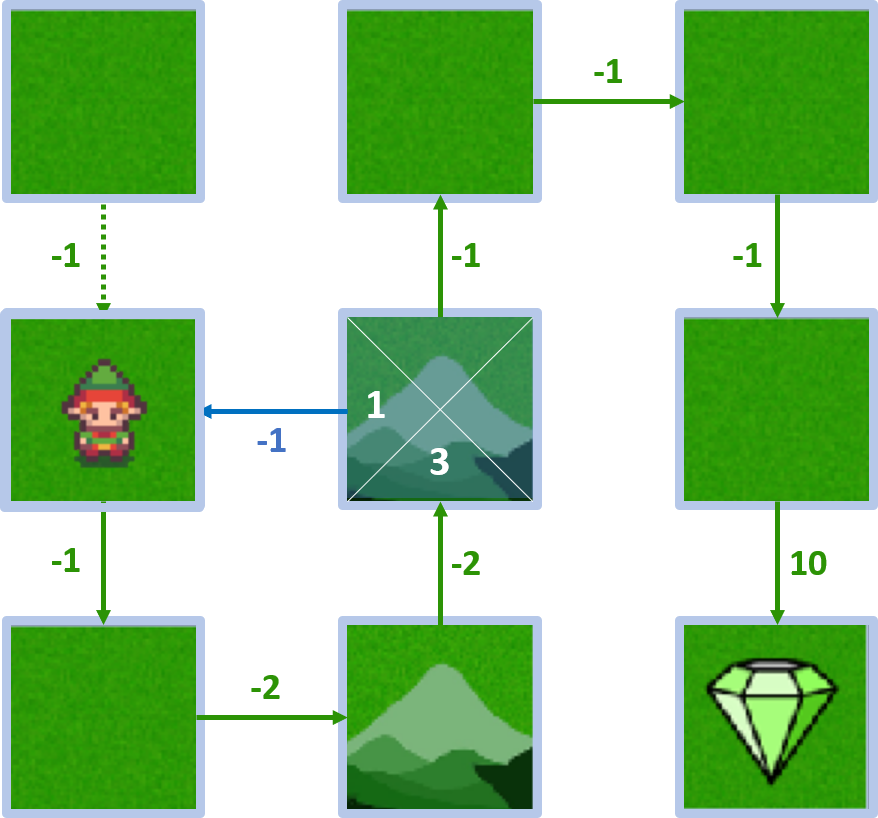
- $Q(4, \text{left}) = -1 + 1 \times 2 = 1$
Estado 4 - acción arriba
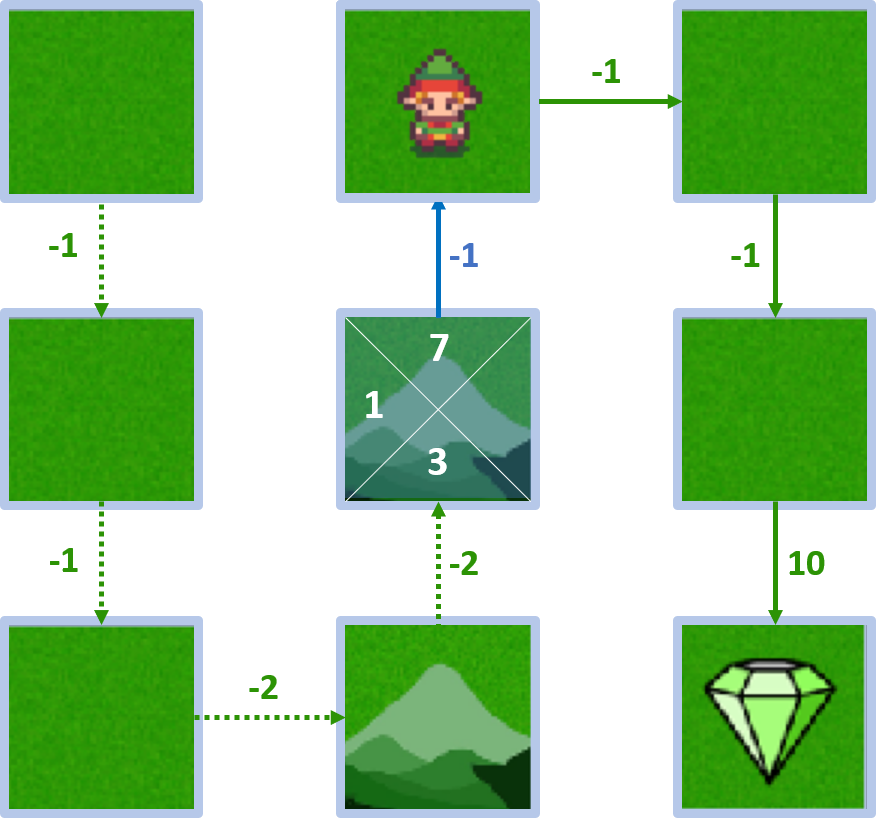
- $Q(4, \text{up}) = -1 + 1 \times 8 = 7$
Estado 4 - acción derecha
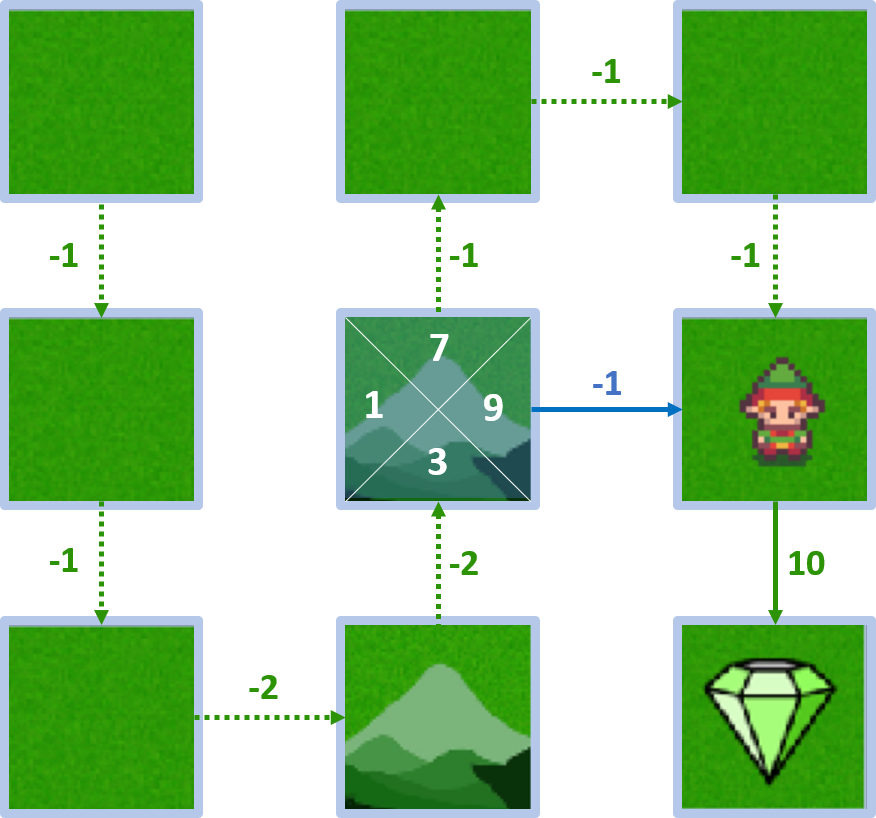
- $Q(4, \text{right}) = -1 + 1 \times 10 = 9$
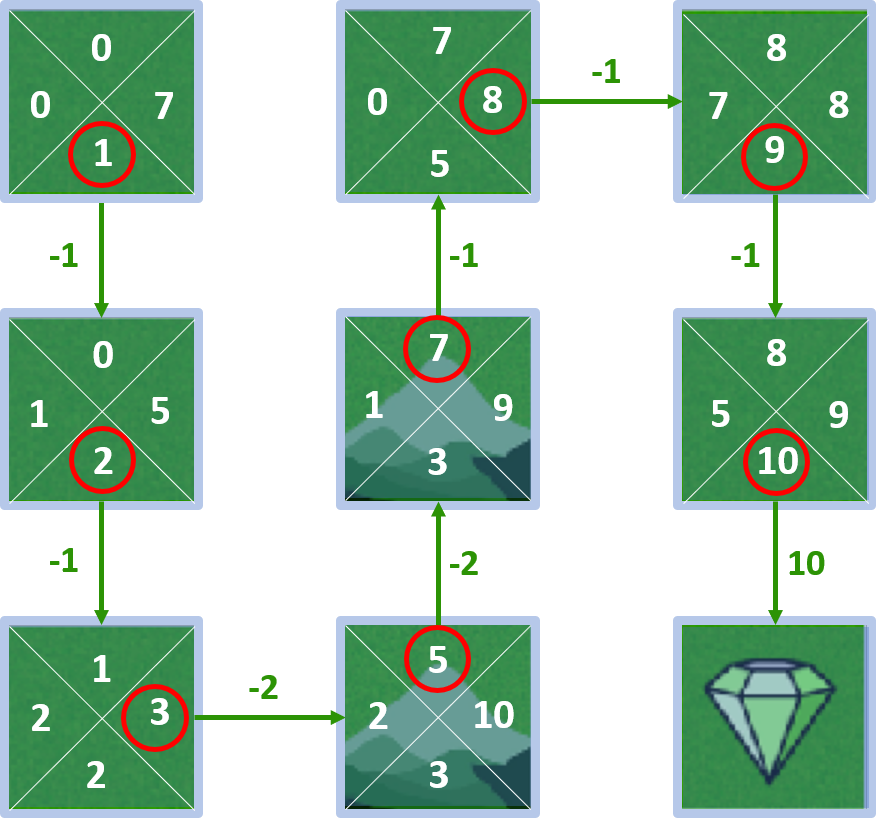
Todos los Q-valores
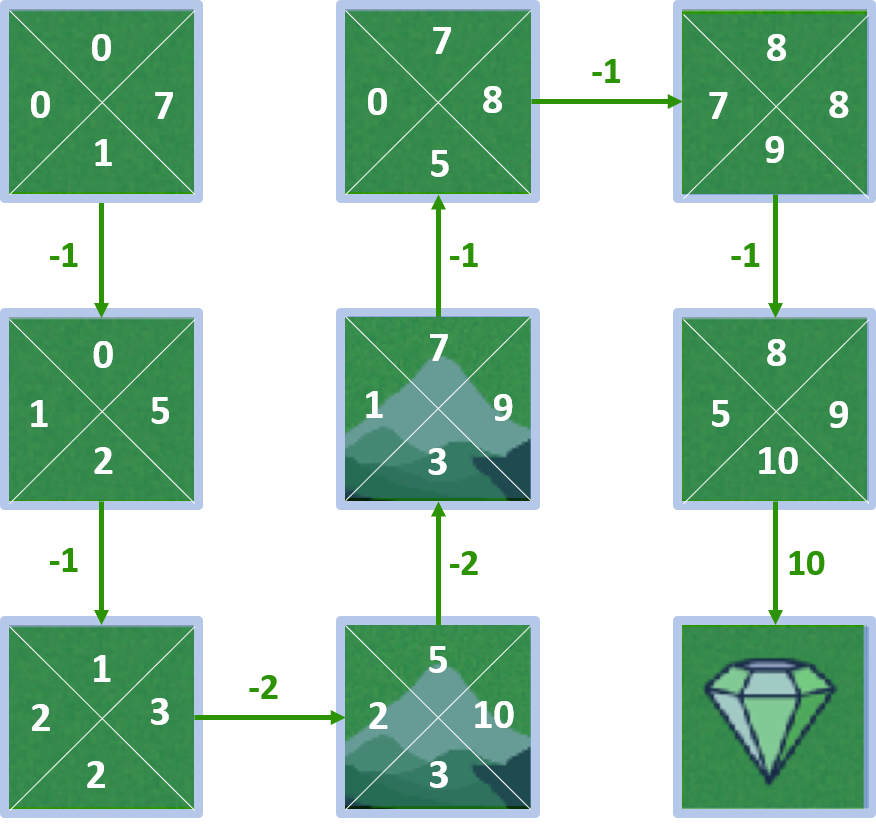
Cálculo de Q-valores
def compute_q_value(state, action):if state == terminal_state: return None_, next_state, reward, _ = env.unwrapped.P[state][action][0] return reward + gamma * compute_state_value(next_state)
Cálculo de Q-valores
Mejora de la política
Mejora de la política
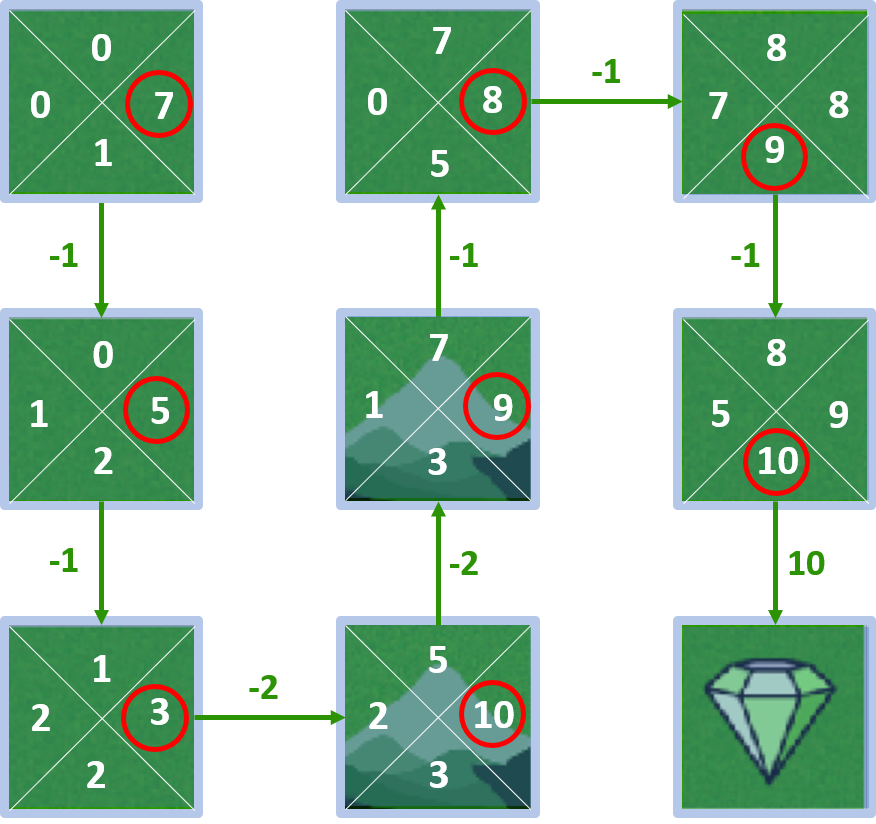
Mejora de la política
 Política antigua
Política antigua