Iteración de políticas y de valores
Reinforcement Learning con Gymnasium en Python

Fouad Trad
Machine Learning Engineer
Iteración de políticas
- Proceso iterativo para encontrar la política óptima

Iteración de políticas
- Proceso iterativo para encontrar la política óptima

Iteración de políticas
- Proceso iterativo para encontrar la política óptima
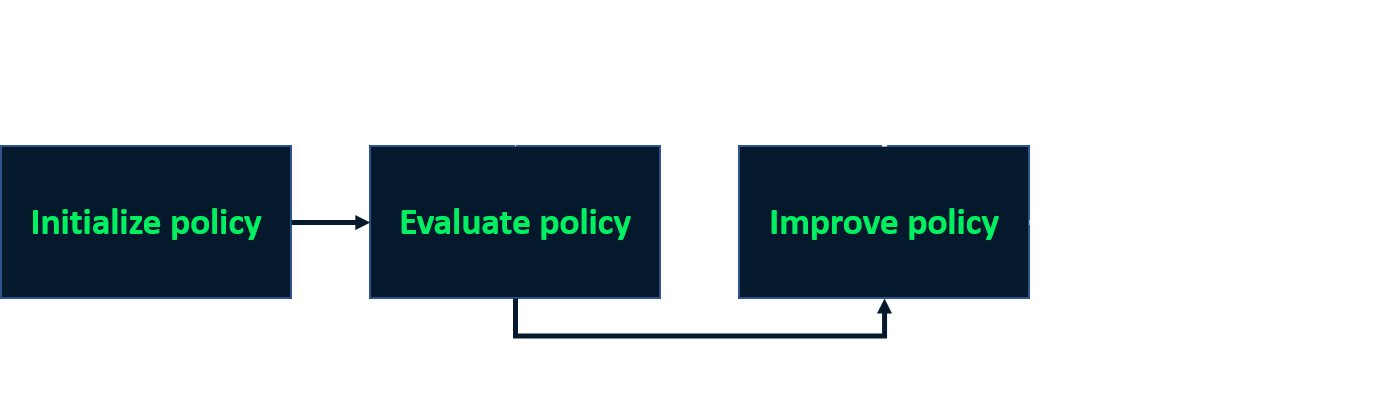
Iteración de políticas
- Proceso iterativo para encontrar la política óptima
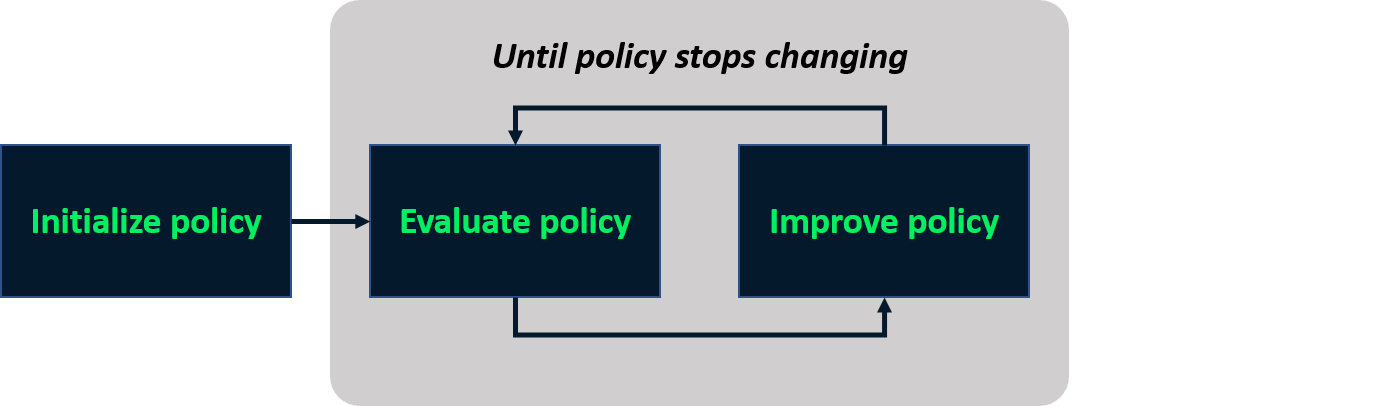
Iteración de políticas
- Proceso iterativo para encontrar la política óptima
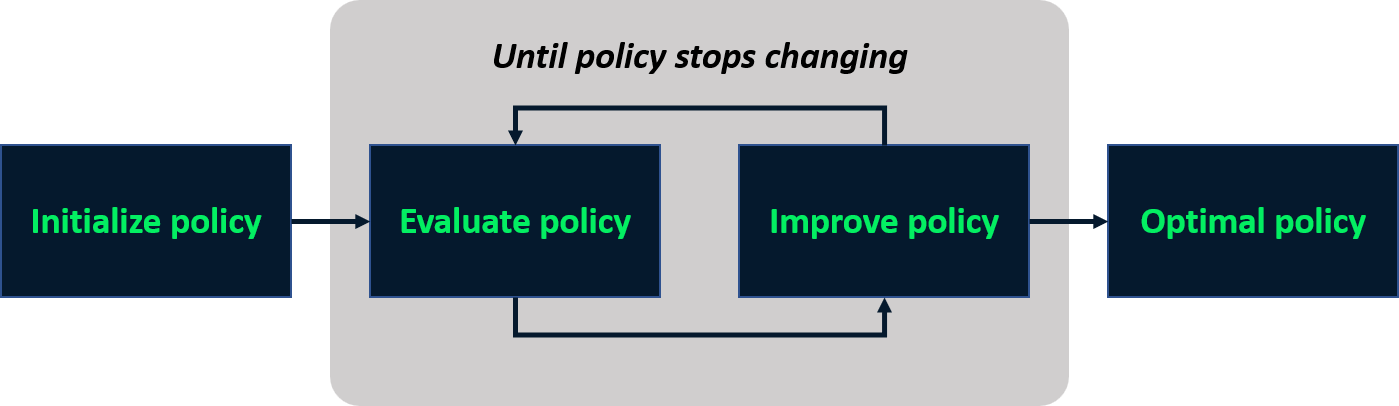
Mundo en rejilla
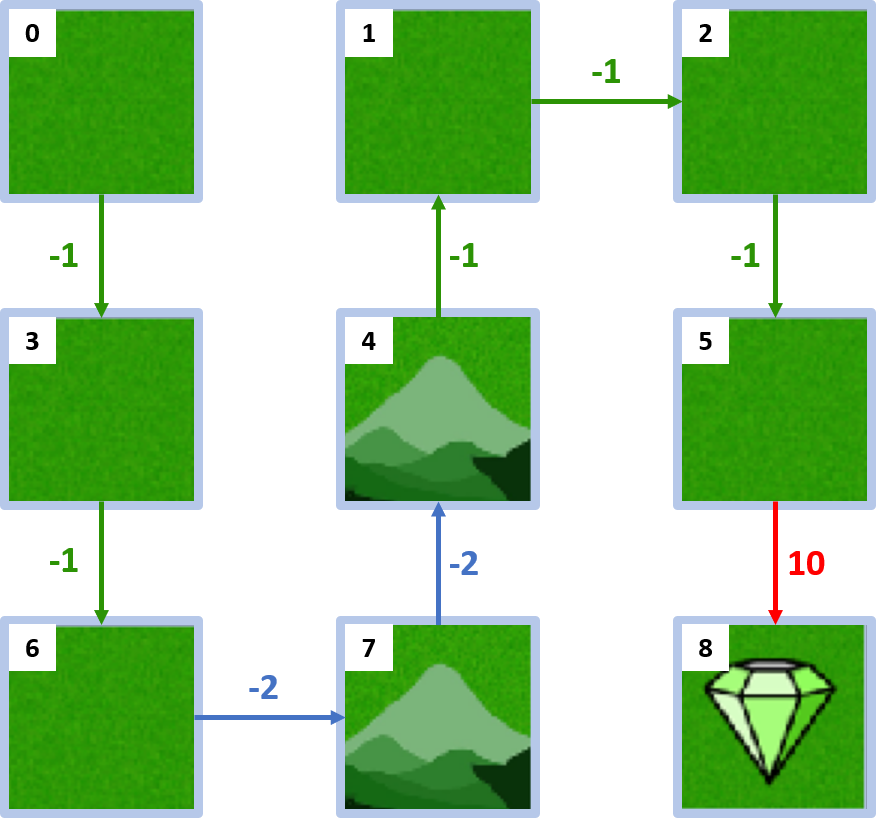
Política óptima
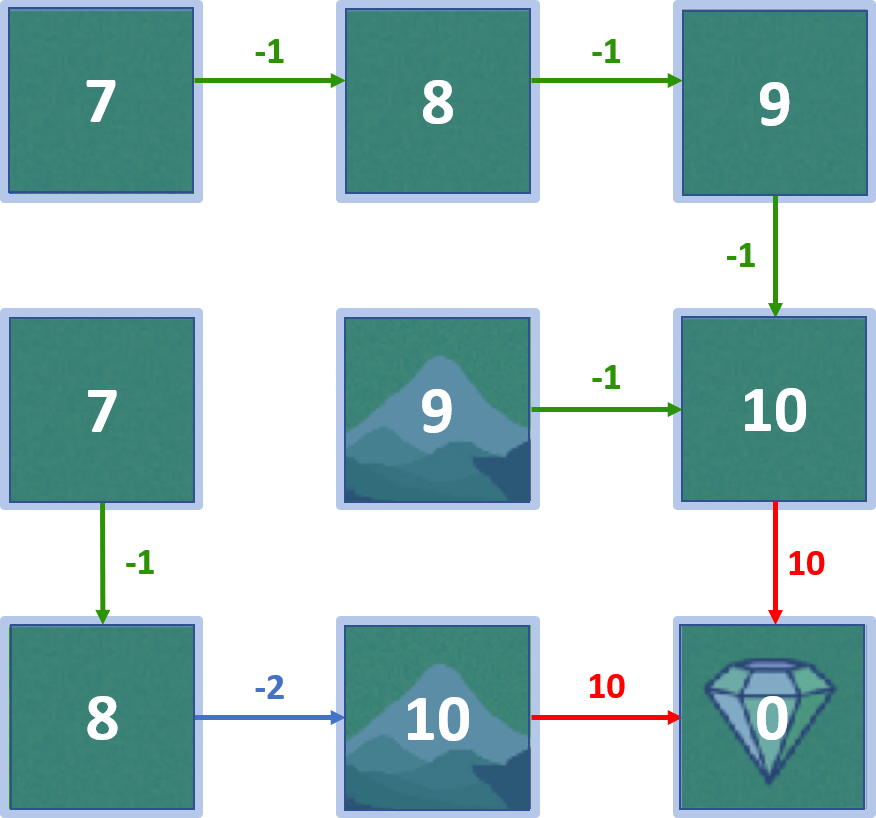
Iteración de valores
- Combina evaluación y mejora de la política en un solo paso
- Calcula la función de valor de estado óptima
- Deriva la política a partir de ella

Iteración de valores
- Combina evaluación y mejora de la política en un solo paso.
- Calcula la función de valor de estado óptima
- Deriva la política a partir de ella

Iteración de valores
- Combina evaluación y mejora de la política en un solo paso.
- Calcula la función de valor de estado óptima
- Deriva la política a partir de ella
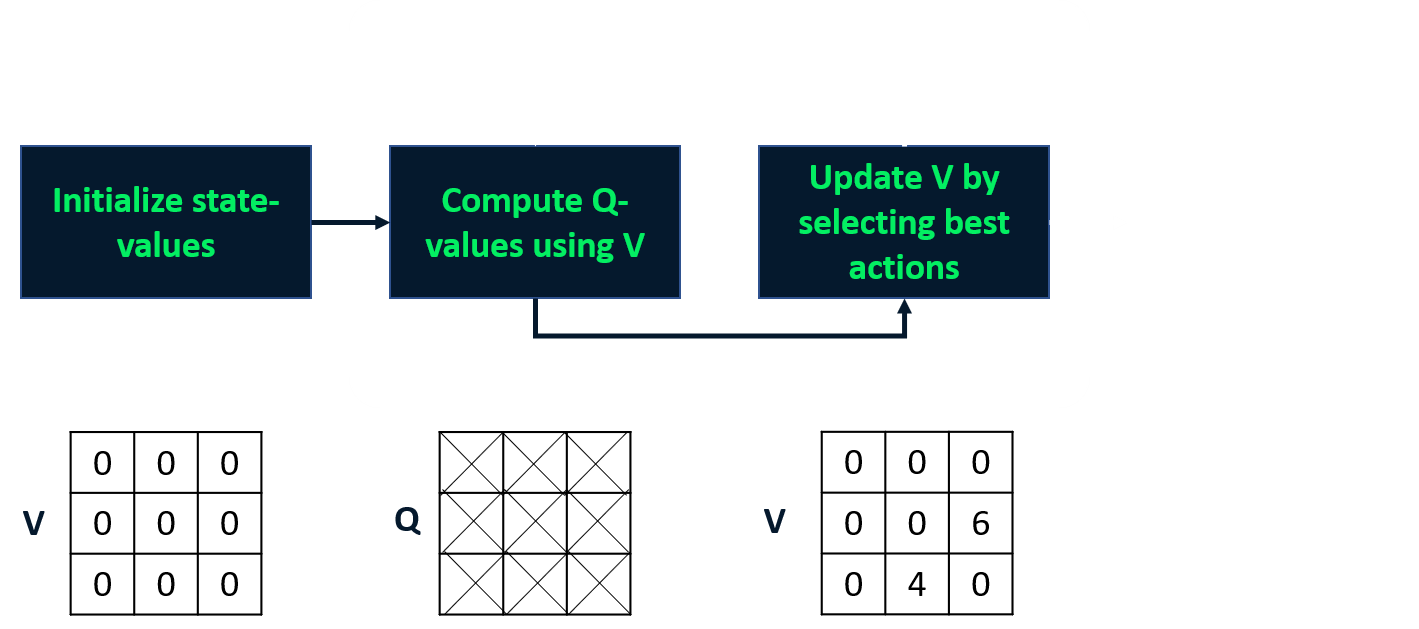
Iteración de valores
- Combina evaluación y mejora de la política en un solo paso.
- Calcula la función de valor de estado óptima
- Deriva la política a partir de ella
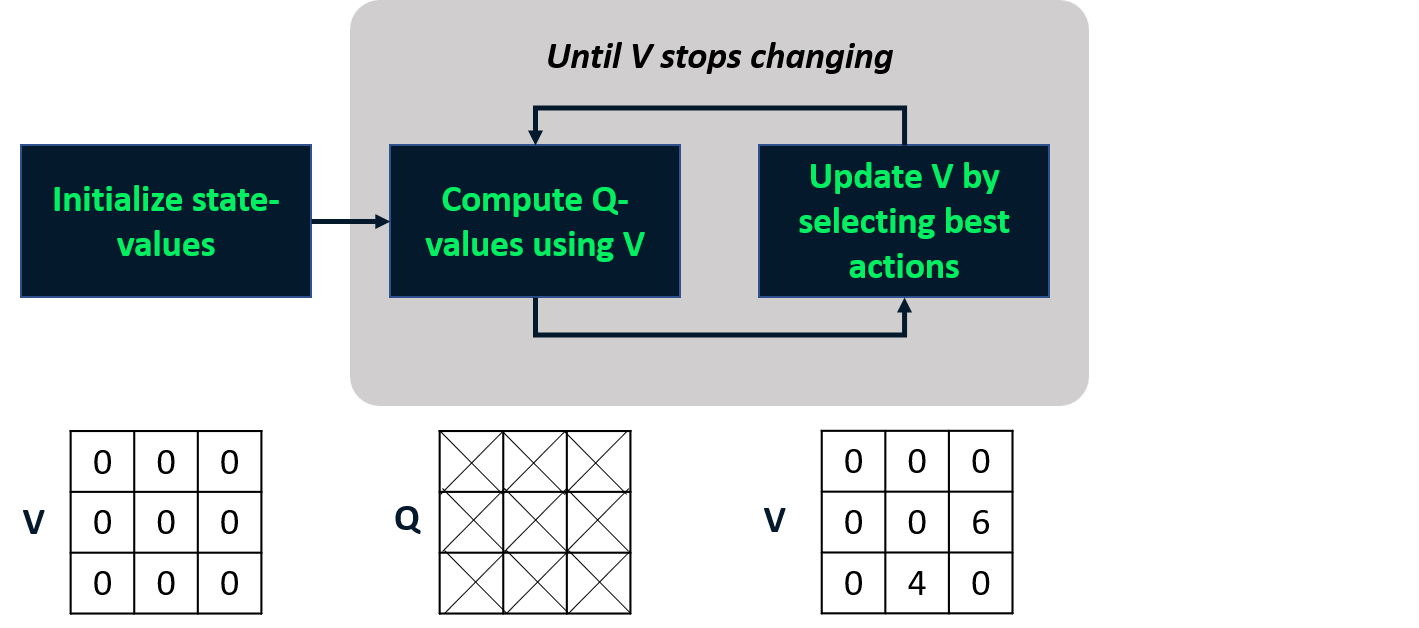
Iteración de valores
- Combina evaluación y mejora de la política en un solo paso.
- Calcula la función de valor de estado óptima
- Deriva la política a partir de ella
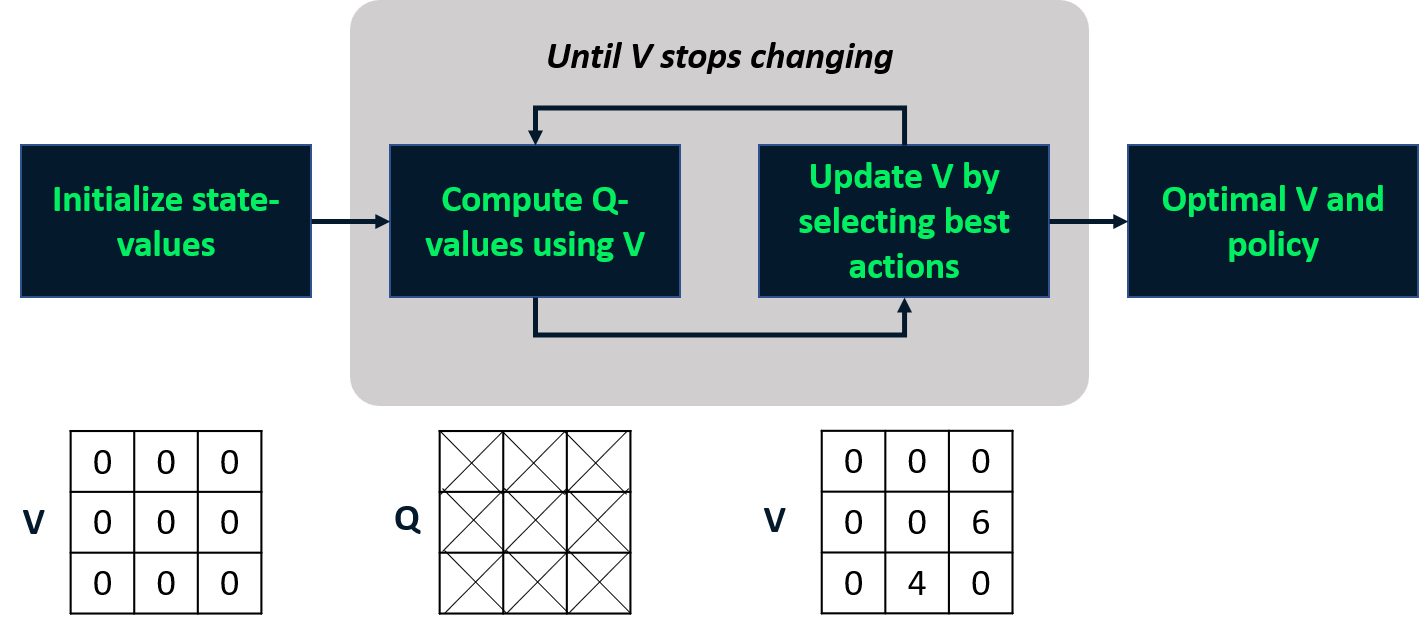
Política óptima

