Handling the event lifecycle: retries, DLQs and destinations
Serverless Applications with AWS Lambda

Claudio Canales
Senior DevOps Engineer
The event lifecycle at a glance
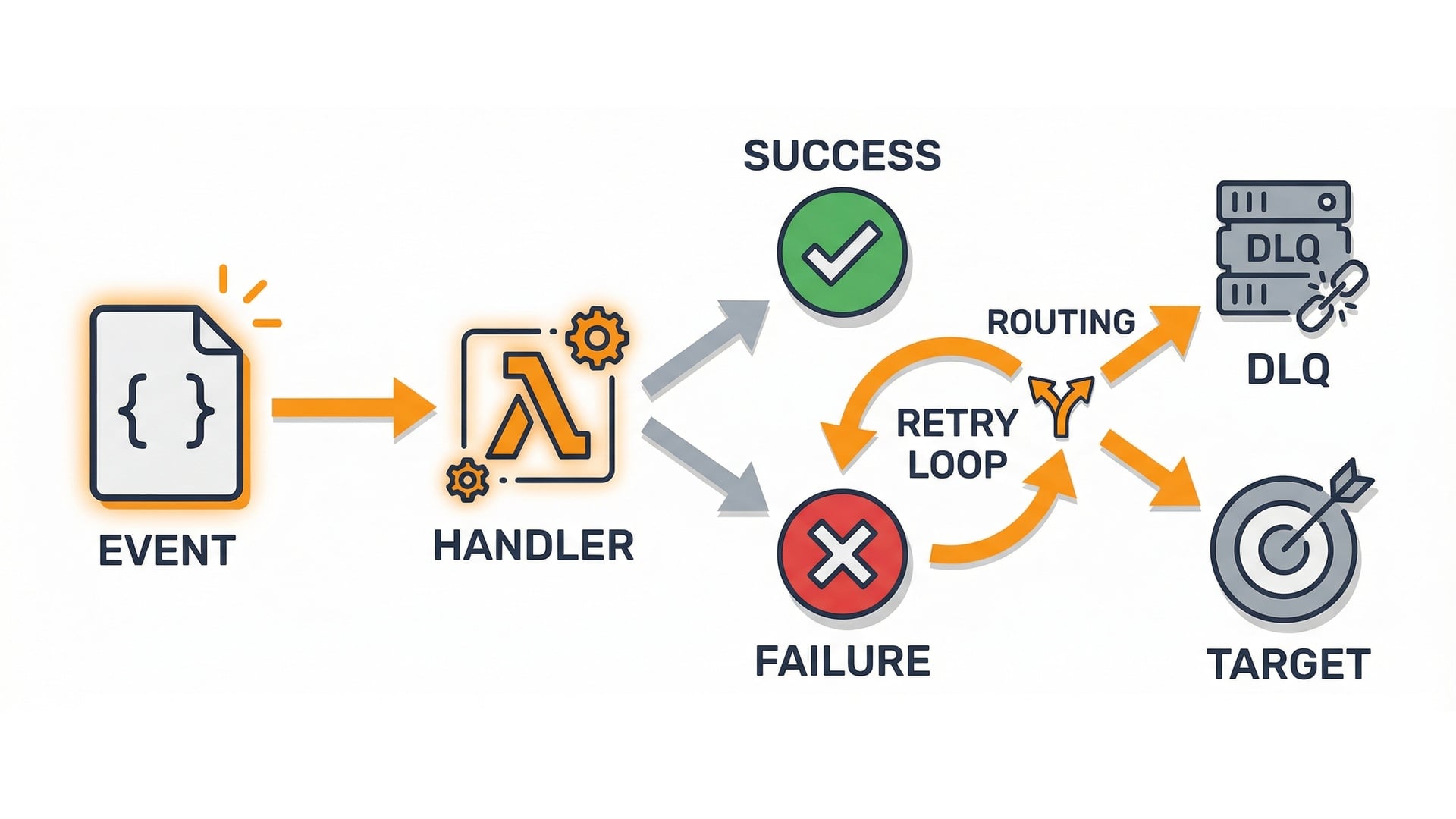
Two ways failures show up
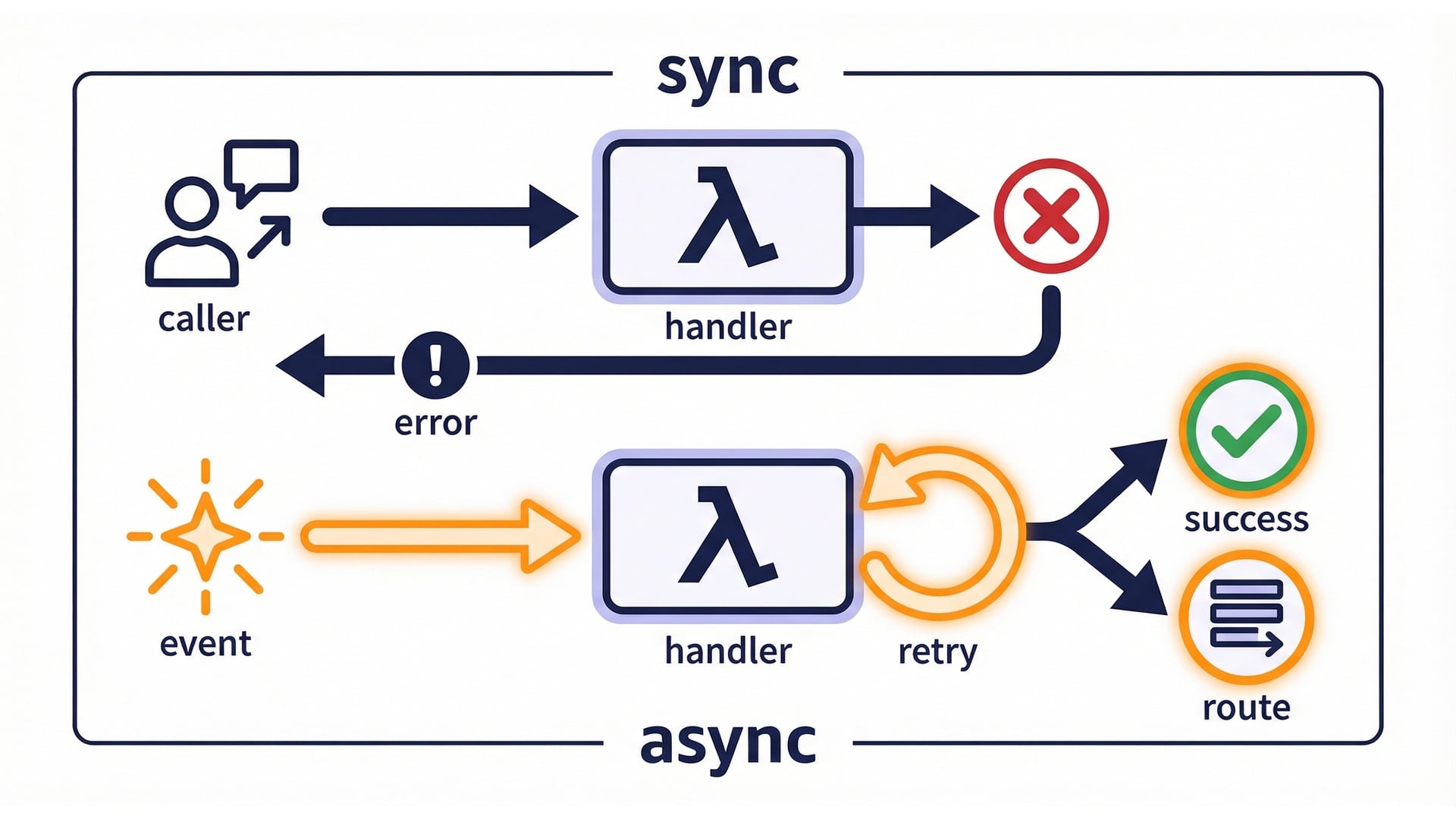
Retries are normal
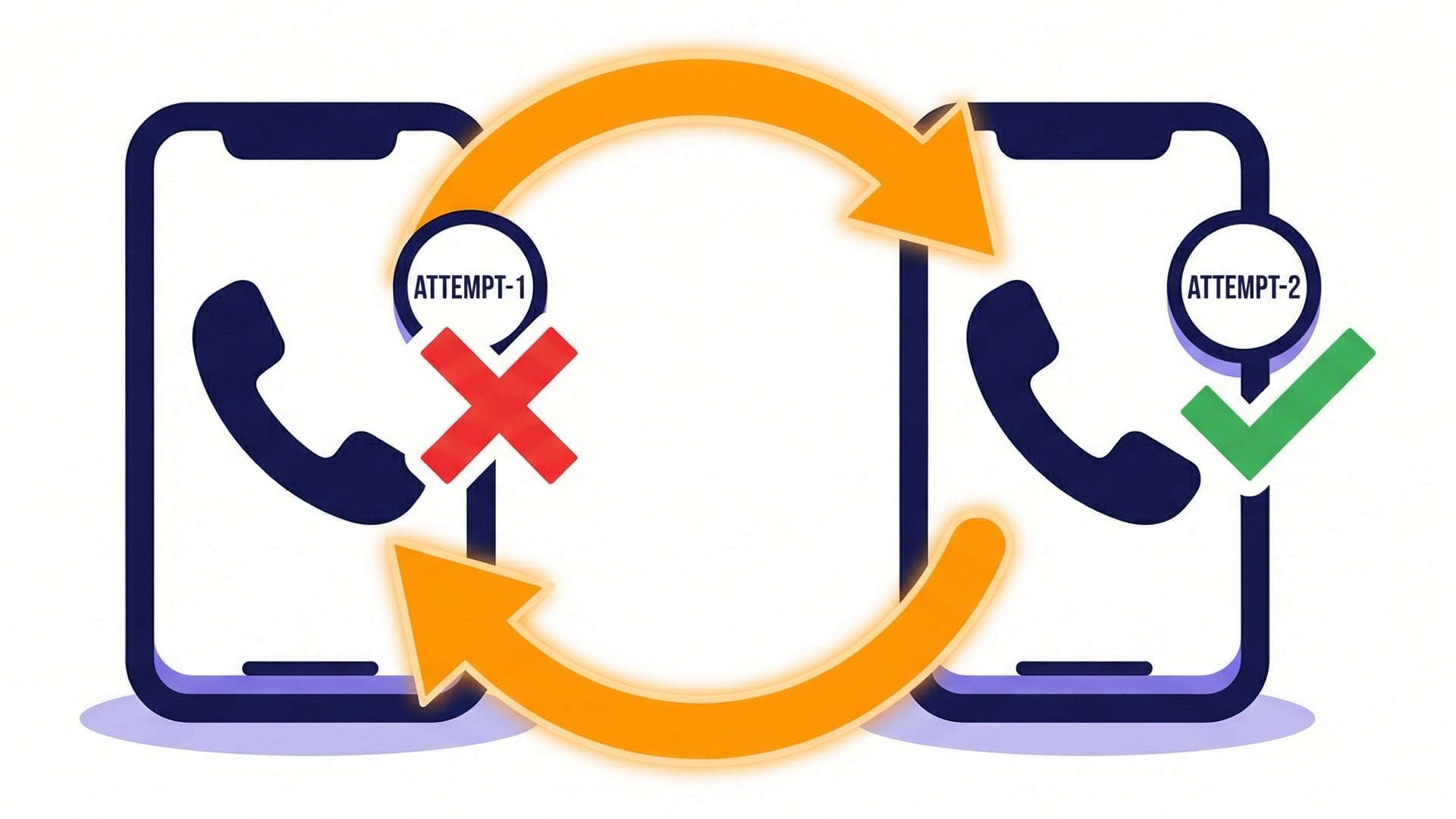
Retries over time
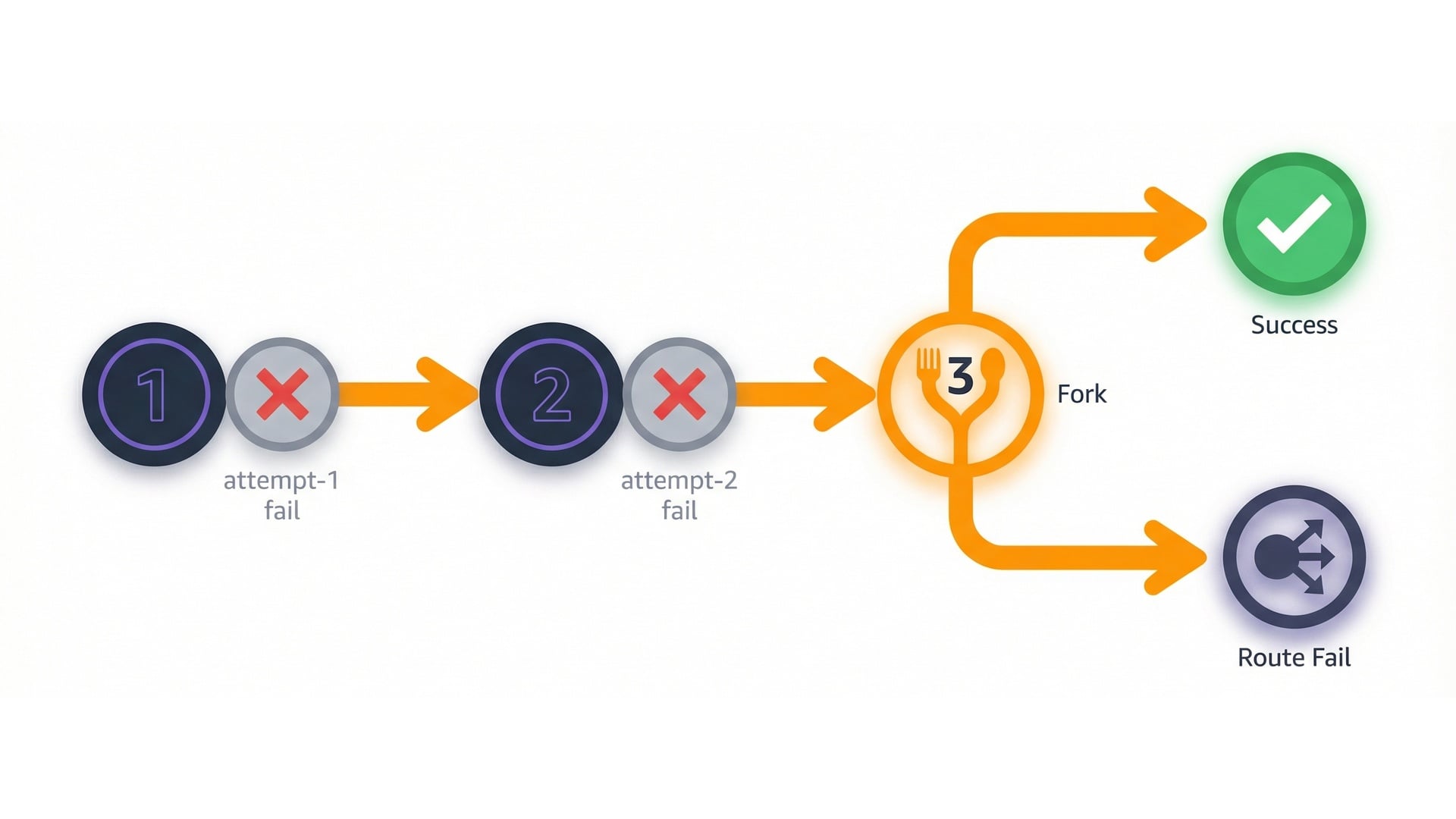
When retries are dangerous
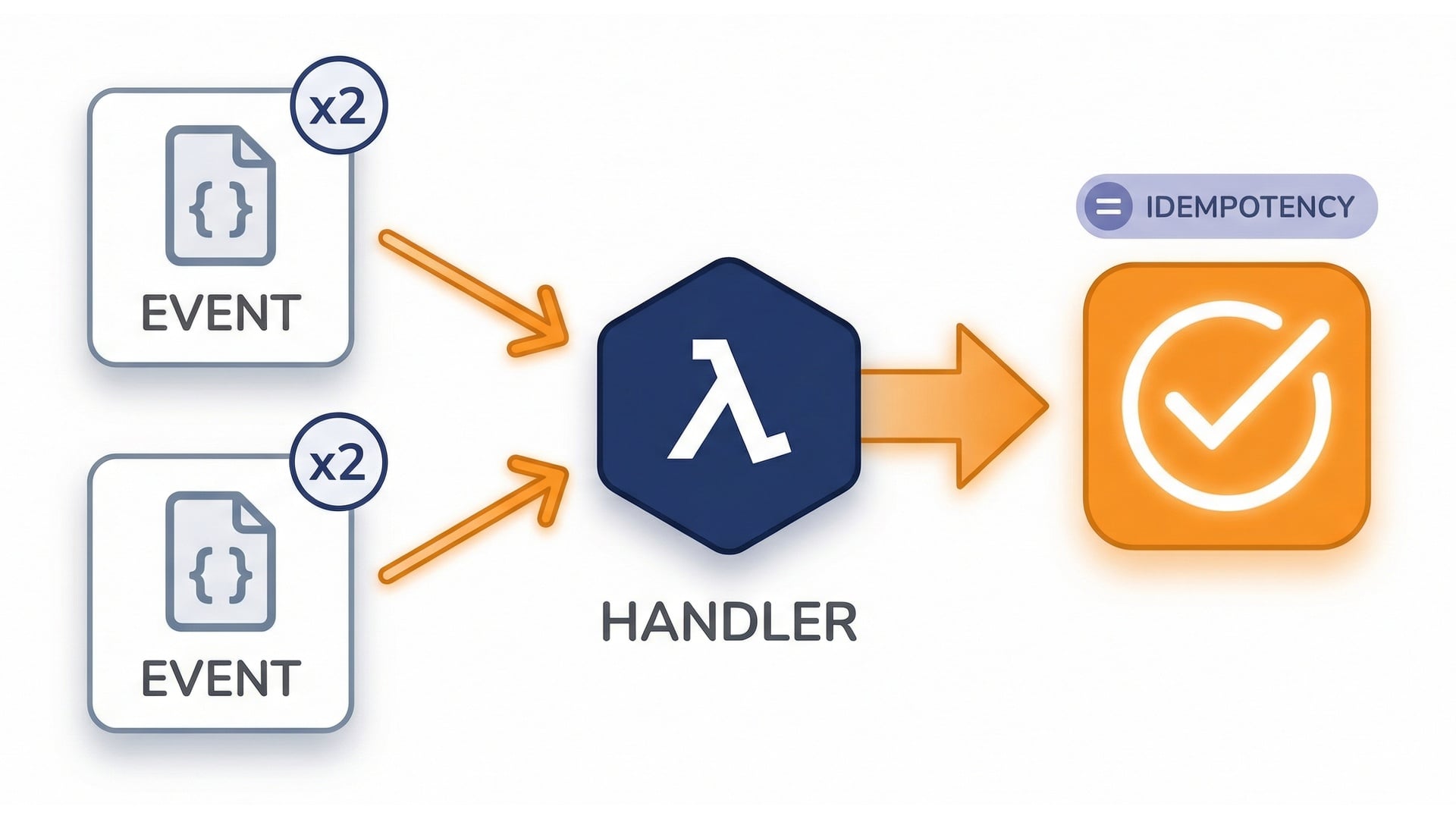
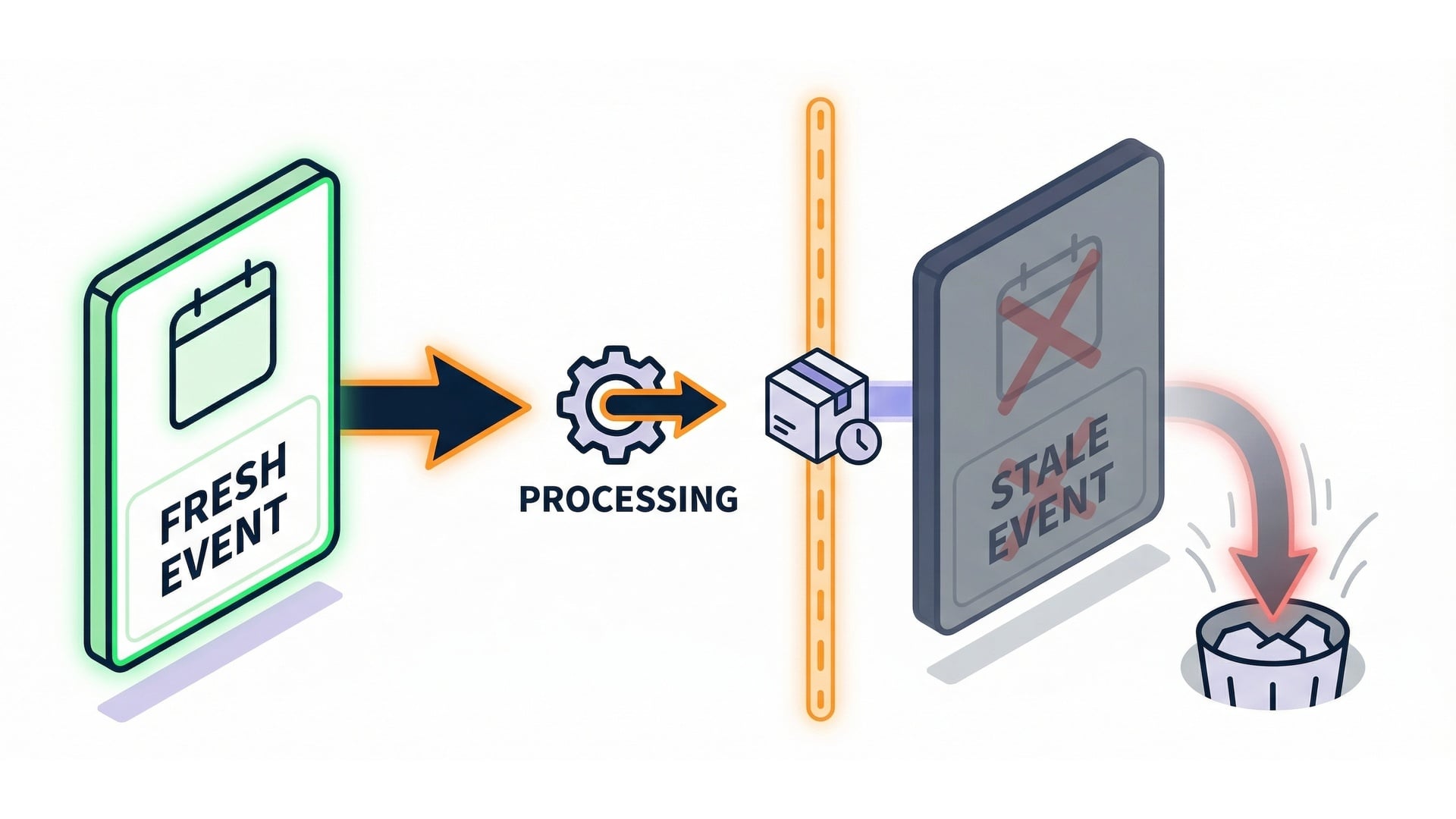
DLQ (Dead-Letter Queue)

DLQ vs destinations
- Captures failed events after retries.
- Use for investigation.
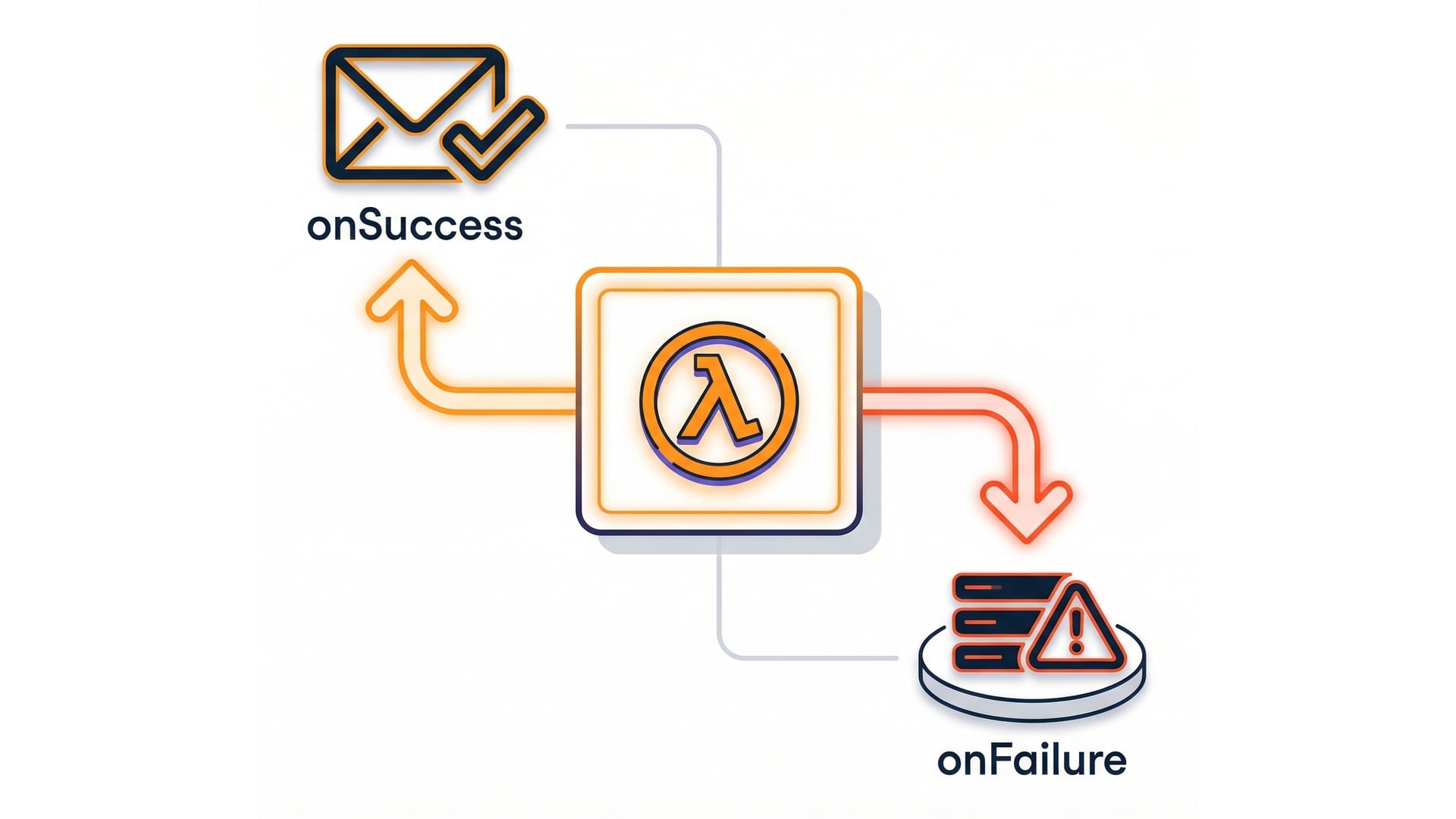
- Route outcomes on success or failure.
- Build explicit success and failure paths.
Destinations: success and failure routes
Tuning retry policy
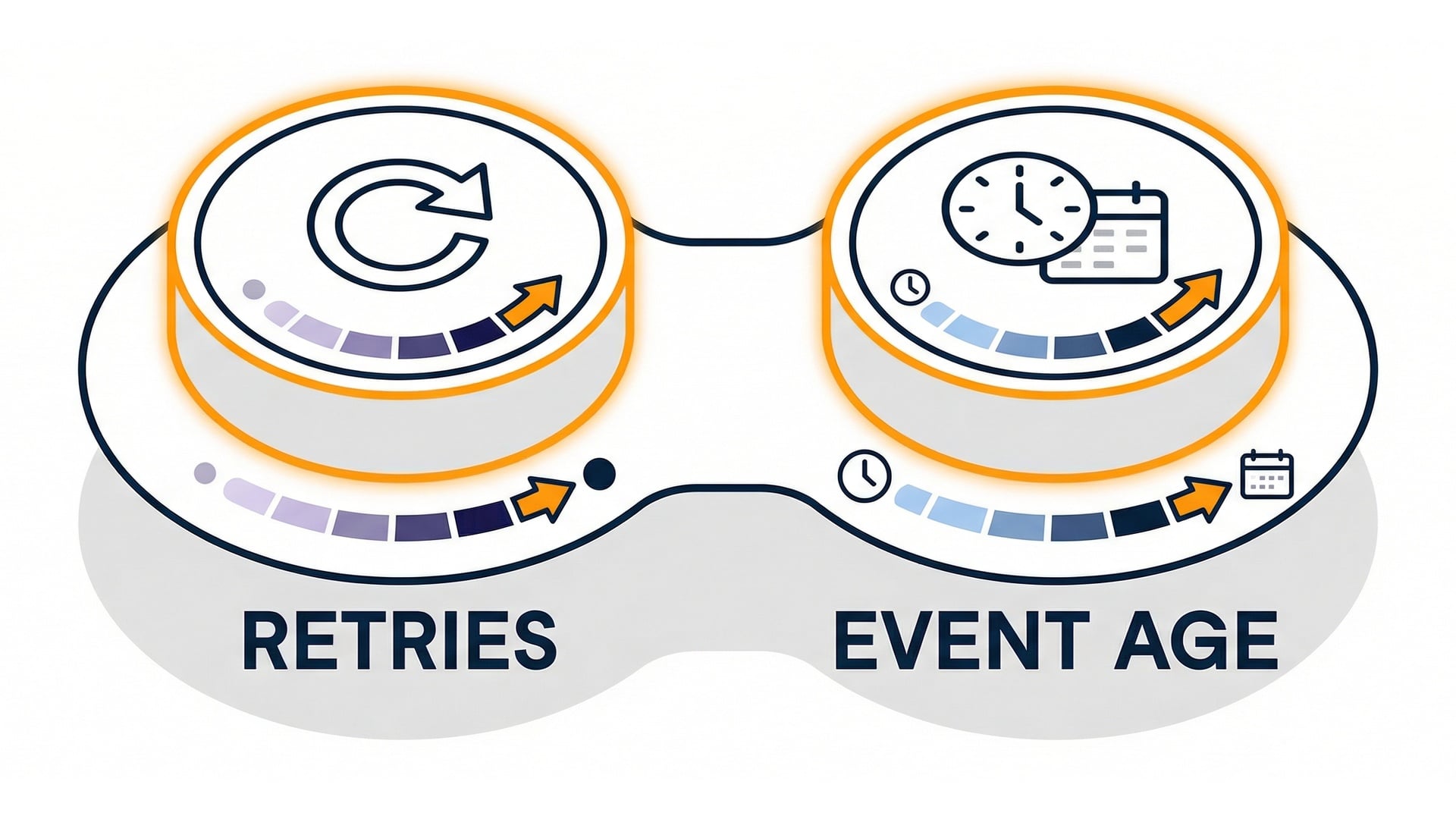
Maximum event age: an expiration date
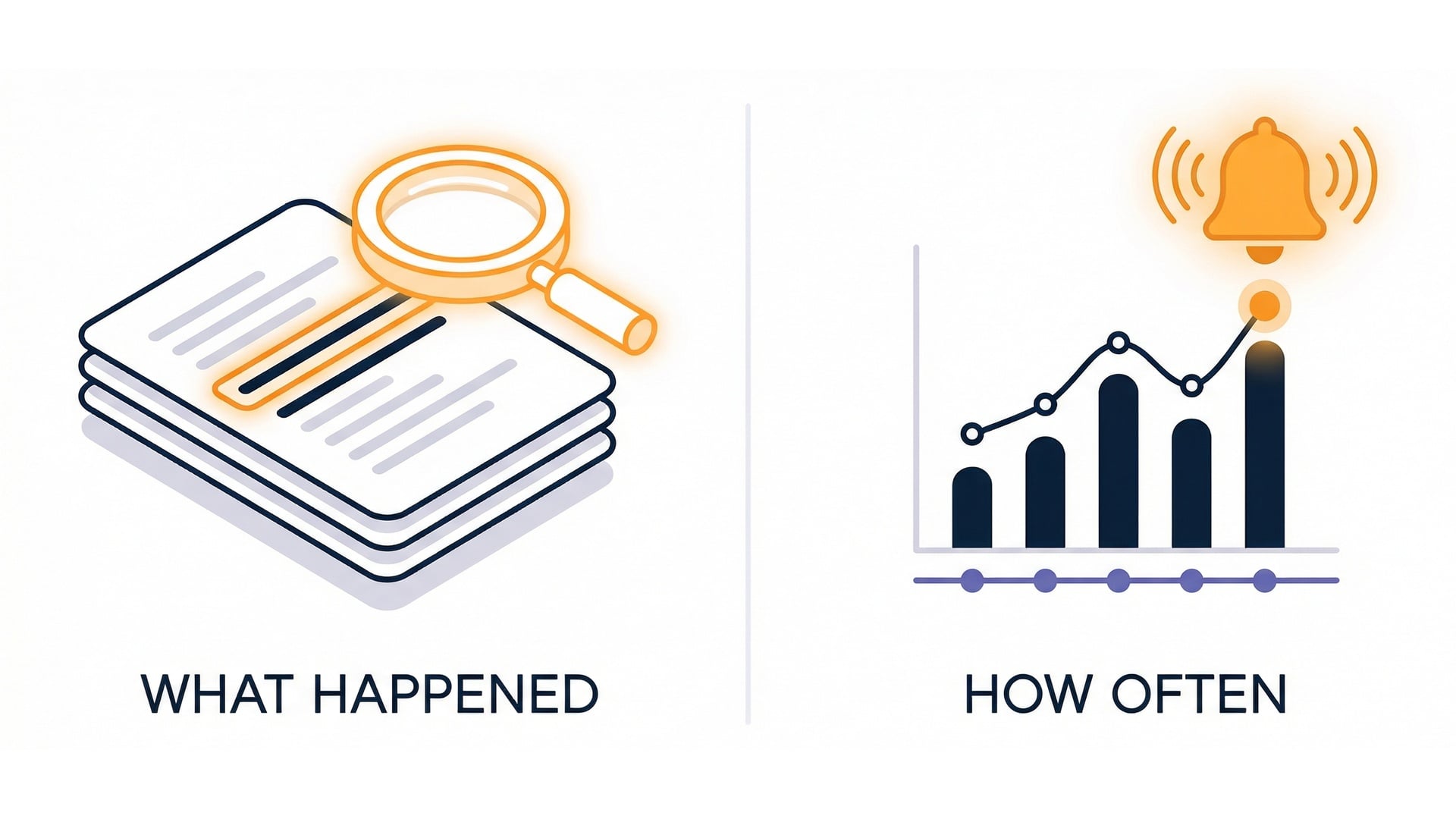
Observability: where to look
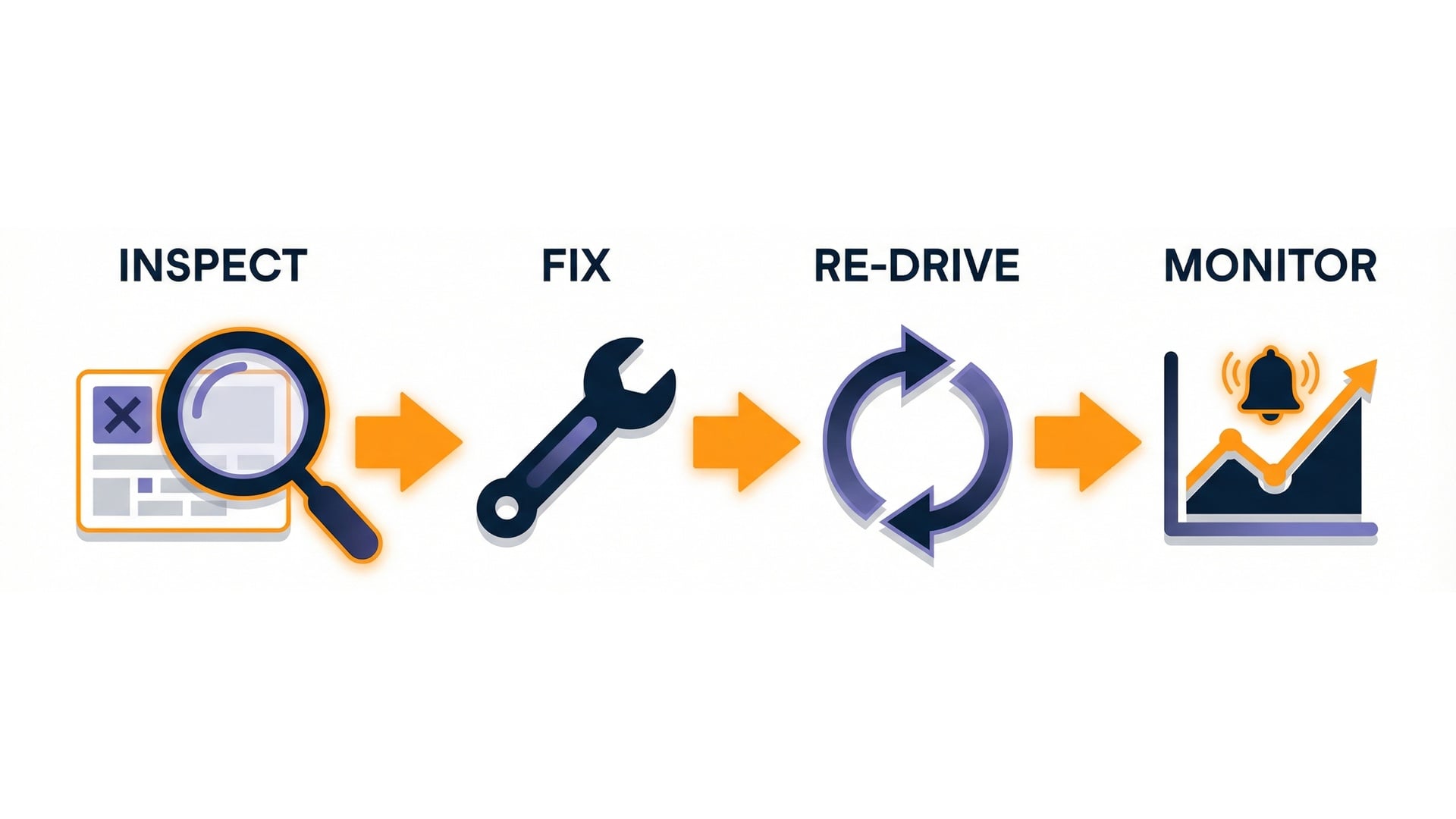
What to do with failed events
Key takeaways