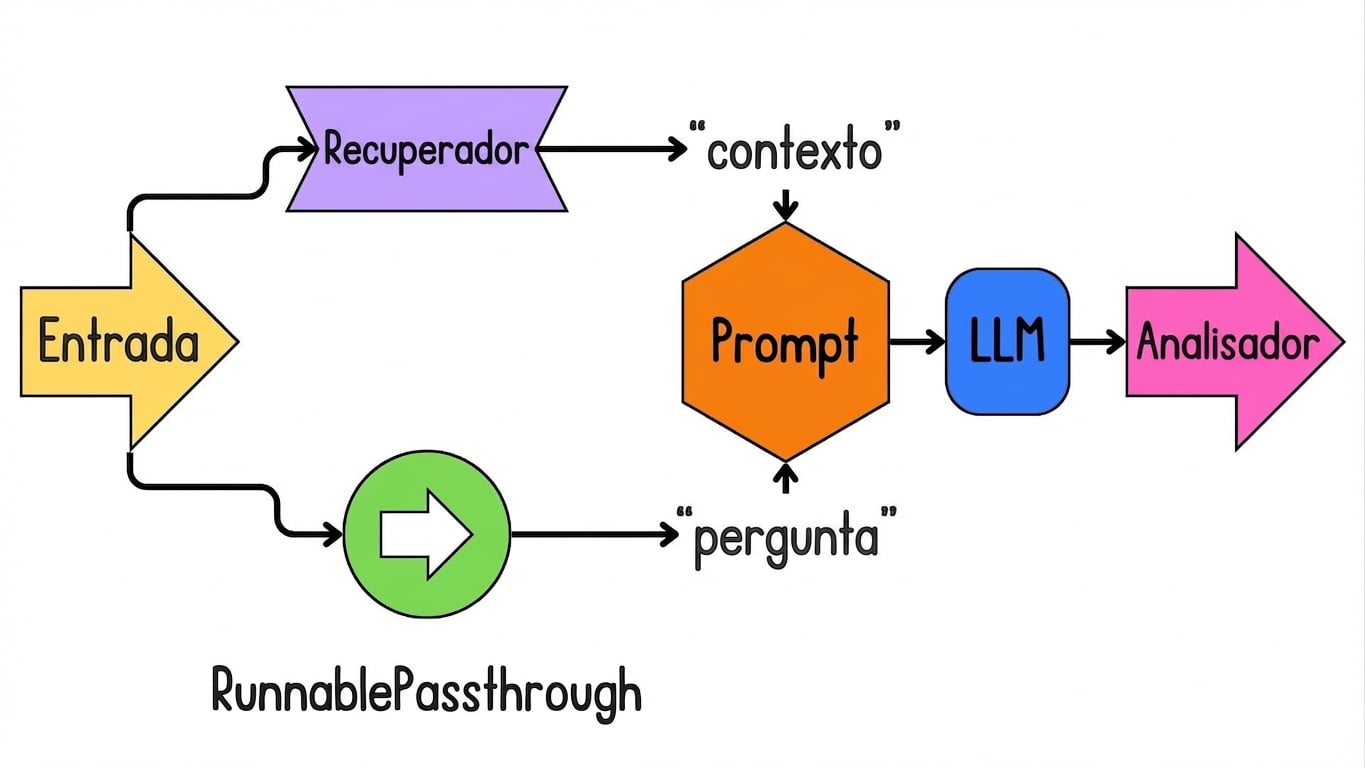
Criando uma cadeia de busca com LCEL
Retrieval Augmented Generation (RAG) com LangChain

Meri Nova
Machine Learning Engineer
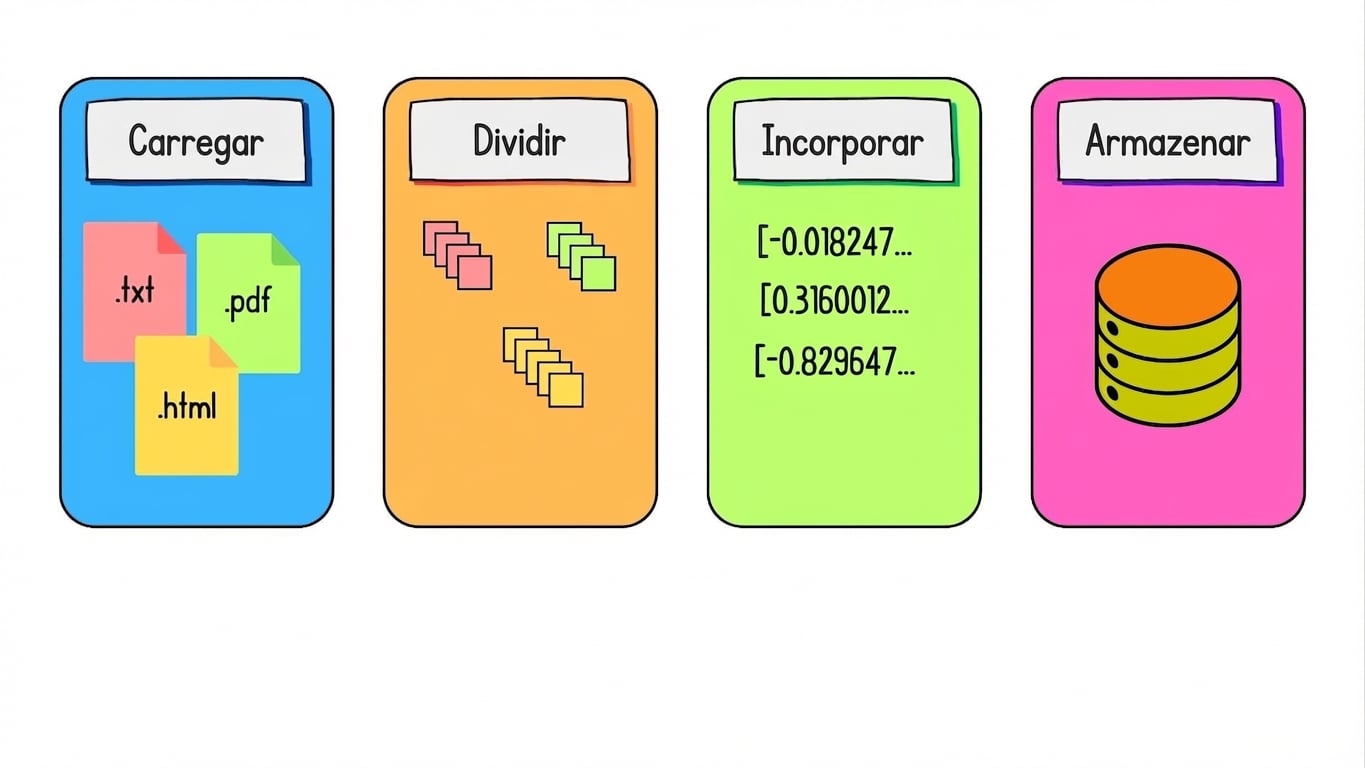
Preparando dados para recuperação
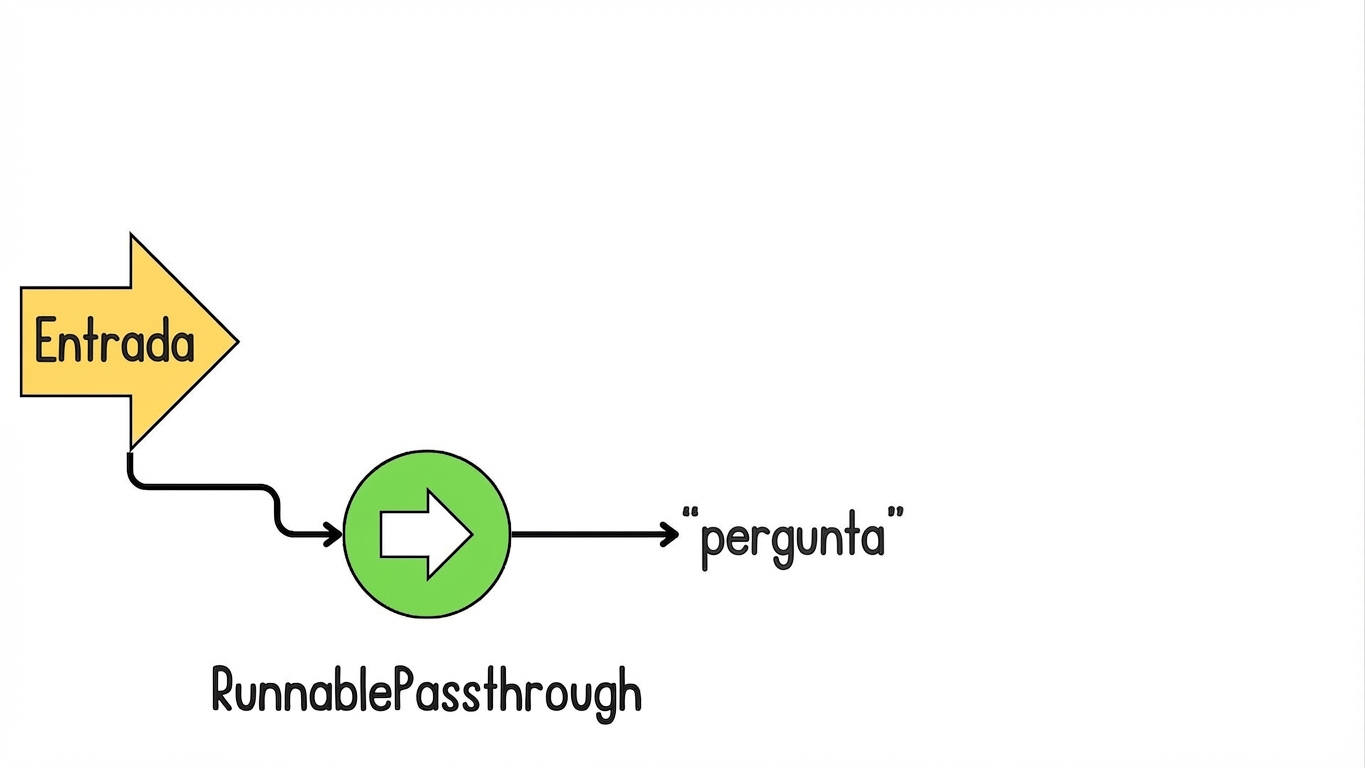
Introdução ao LCEL para RAG

Introdução ao LCEL para RAG
Introdução ao LCEL para RAG
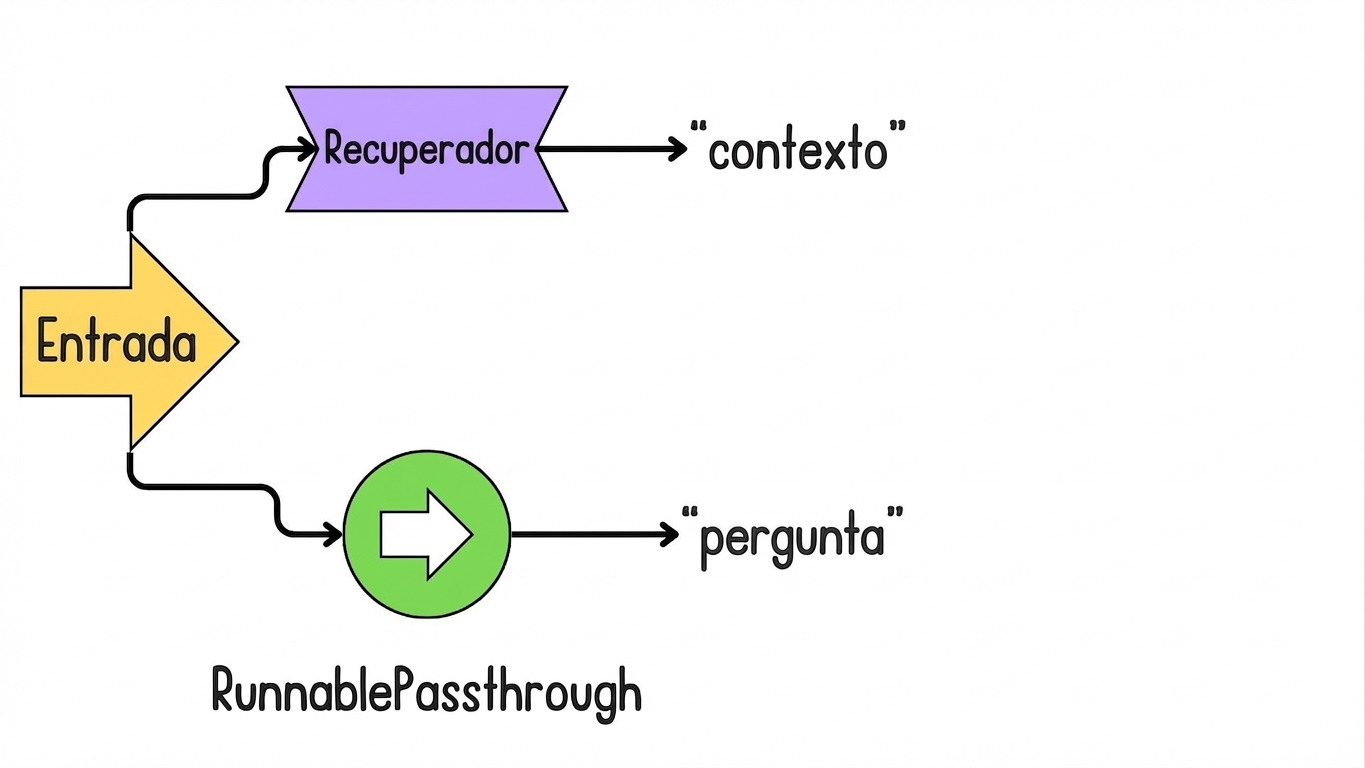
Introdução ao LCEL para RAG
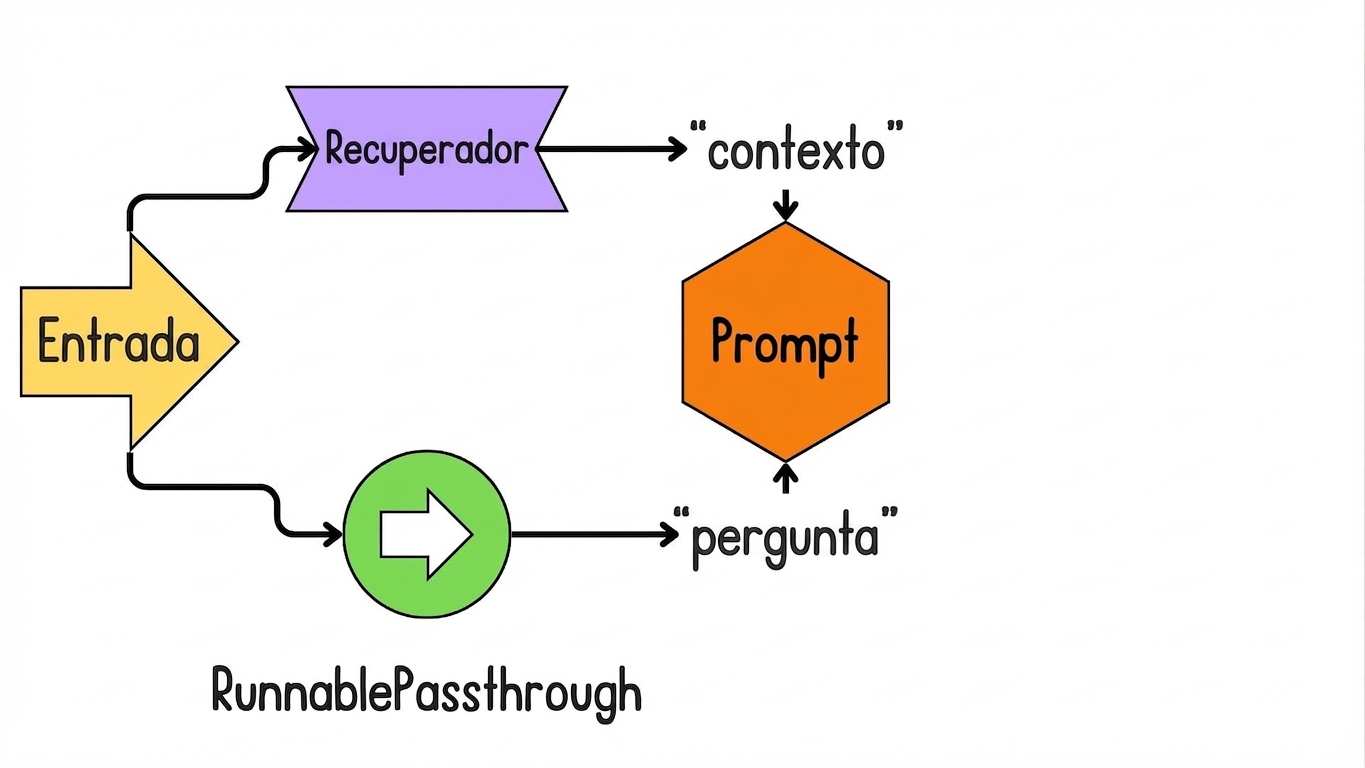
Introdução ao LCEL para RAG
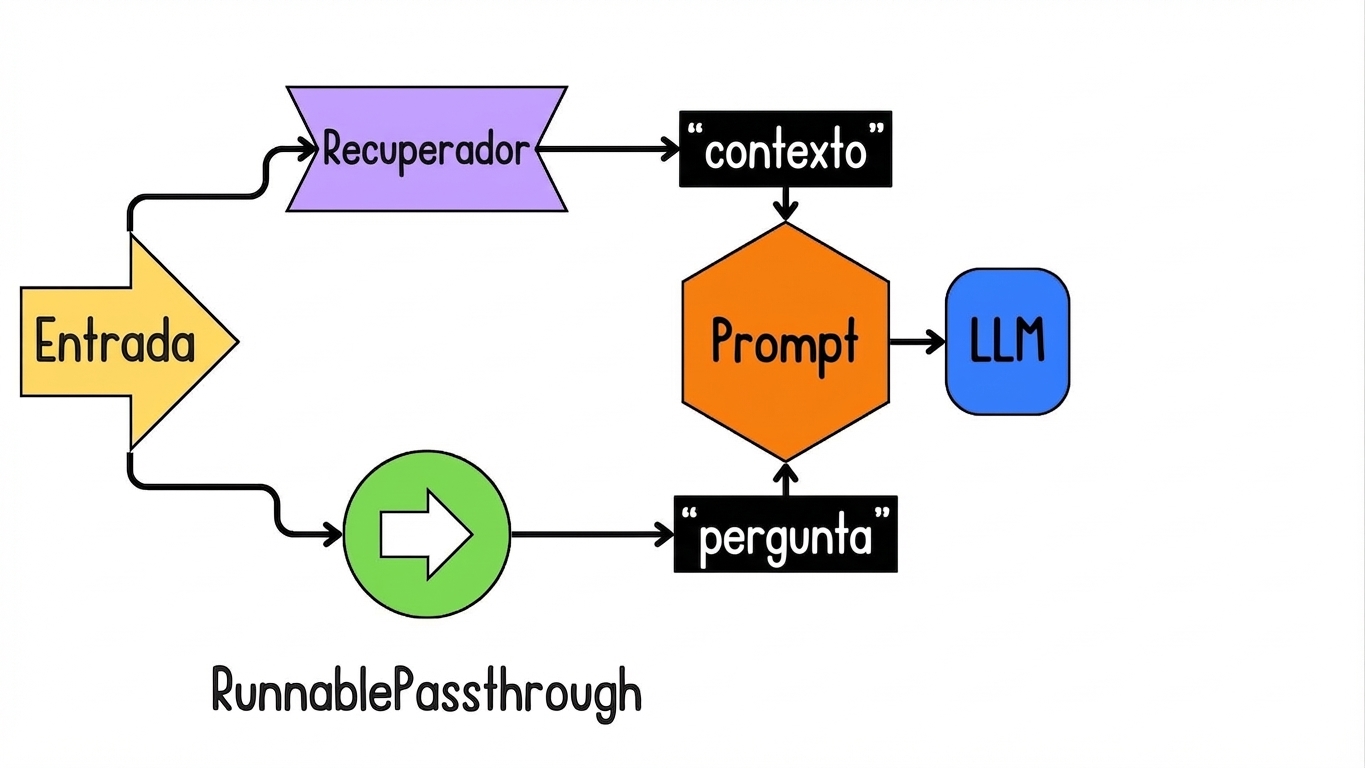
Introdução ao LCEL para RAG