Otimizando a recuperação de documentos
Retrieval Augmented Generation (RAG) com LangChain

Meri Nova
Machine Learning Engineer
Colocando o R no RAG...
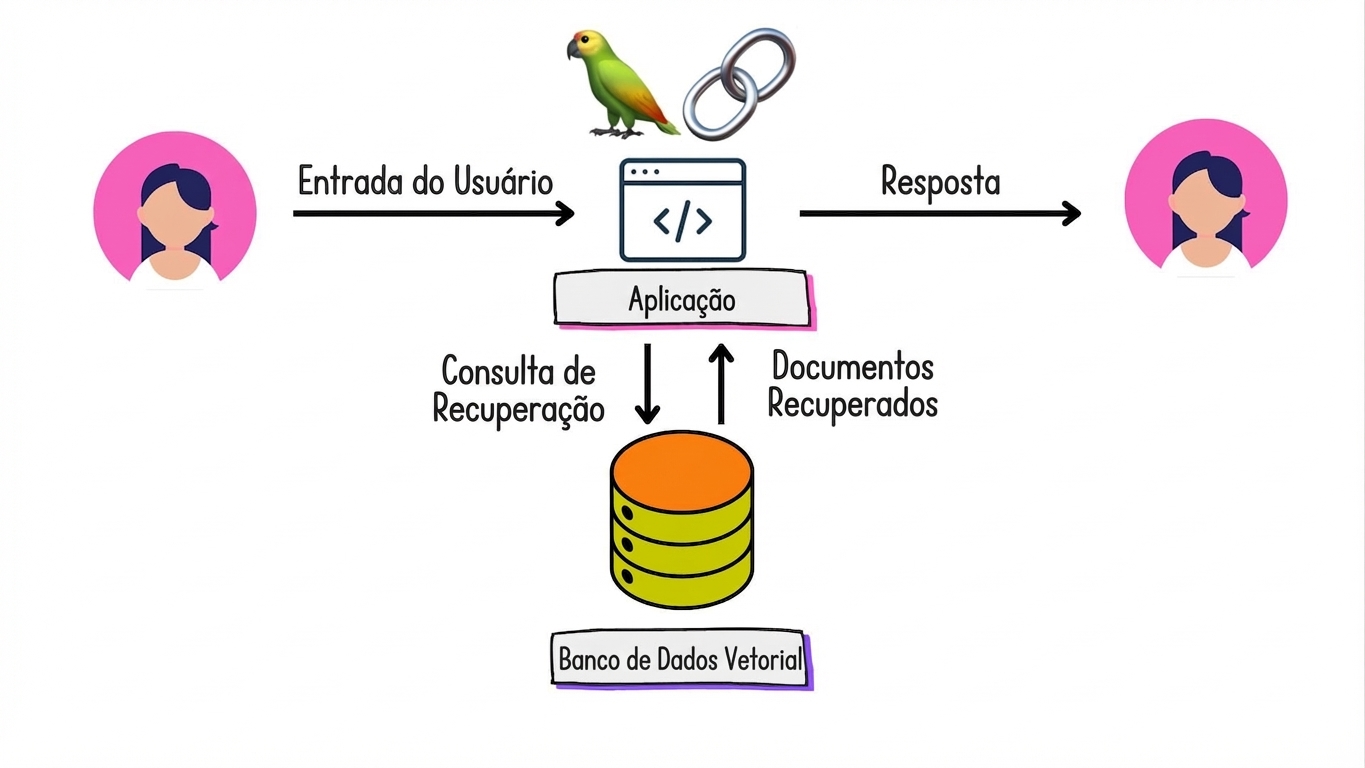
Denso
Codifica chunks como um único vetor com componentes não zero
- Prós: Captura o significado semântico
- Contras: Computacionalmente caro
Denso
Codifica chunks como um único vetor com componentes não zero
- Prós: Captura o significado semântico
- Contras: Computacionalmente caro
Esparso
Codifica por correspondência de palavras, com componentes majoritariamente zero
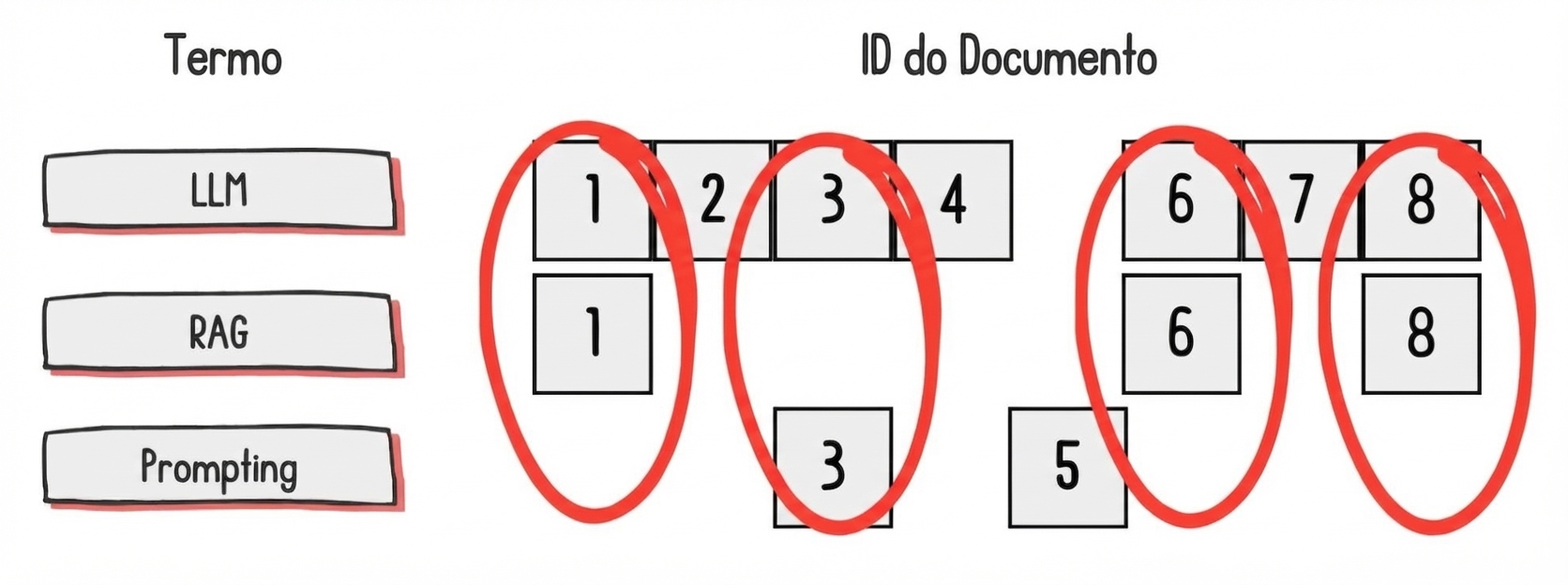
- Prós: Preciso, explicável, lida bem com palavras raras
- Contras: Generalização
Métodos de recuperação esparsa
TF-IDF: Codifica documentos usando as palavras que tornam o documento único
BM25: Reduz o efeito de palavras muito frequentes saturarem a codificação

