Avaliação e visualização de modelos
Machine Learning de ponta a ponta

Joshua Stapleton
Machine Learning Engineer
Acurácia
- Métricas corretas de acurácia são vitais para avaliar bem o modelo
- Resultados podem ser mal interpretados ou mascarados
Acurácia padrão:
- Acurácia = nº de acertos / nº de previsões
- Pode ser pouco útil
Exemplo:
# alcança ~99% de acurácia num dataset desbalanceado com 99 positivos e 1 negativo
for patient_datapoint in heart_disease_dataset:
model.prediction(patient_datapoint) = 'positive'
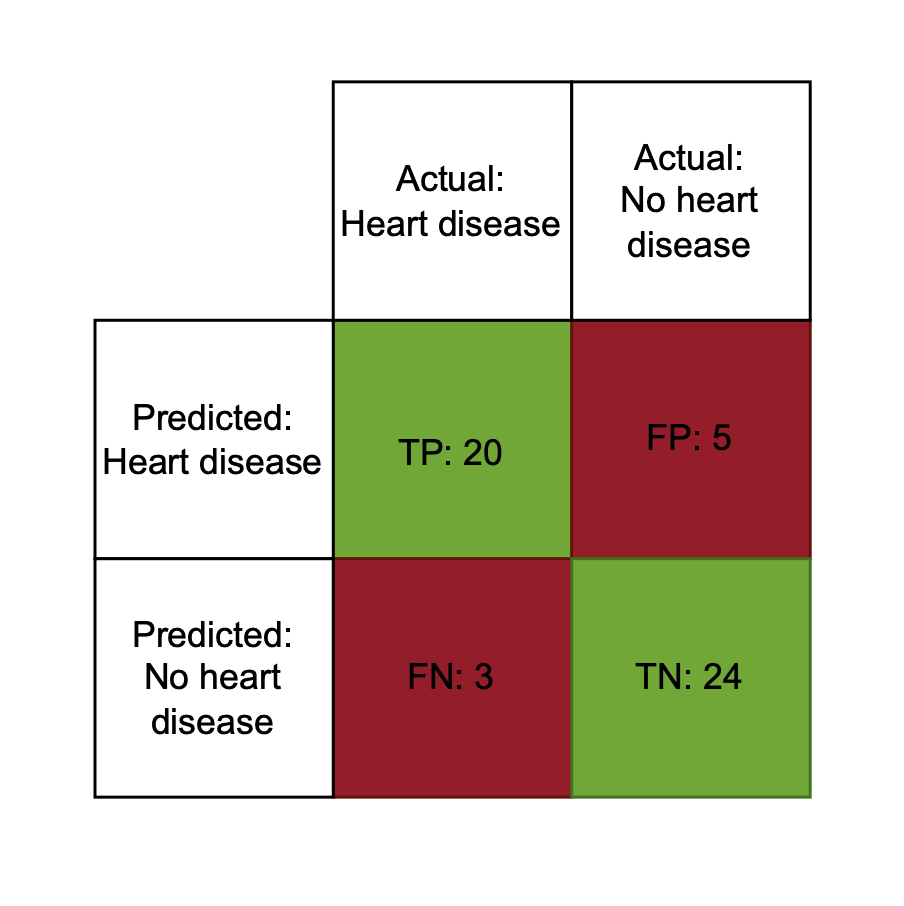
Matriz de confusão
Verdadeiros positivos (TP)
- Previsão do modelo = classe real = positivo
- O modelo previu doença cardíaca e o paciente tinha
Falsos positivos (FP)
- Previsão = positivo, classe real = negativo
- O modelo previu doença cardíaca e o paciente não tinha
Falsos negativos (FN)
- Previsão = negativo, classe real = positivo
- O modelo previu sem doença cardíaca e o paciente tinha
Verdadeiros negativos (TN)
- Previsão do modelo = classe real = negativo
- O modelo previu sem doença cardíaca e o paciente não tinha
Balanced accuracy
- Melhor que a acurácia simples para a maioria dos binários
- Faz média ponderada entre as classes
- Balanced accuracy = (TP + TN) / 2
from sklearn.metrics import balanced_accuracy_score
# Assuma que y_test são os rótulos reais e y_pred as previsões
y_pred = model.predict(X_test)
bal_accuracy = balanced_accuracy_score(y_test, y_pred)
print(f"Balanced Accuracy: {bal_accuracy:.2f}")
Balanced Accuracy: 0.85
Uso da matriz de confusão
Validação cruzada
Validação cruzada
- Procedimento de reamostragem
- Garante resultados robustos
k-fold cross-validation
- Parâmetro 'k' = nº de divisões do dataset
- Reamostra novo split treino/teste a cada execução
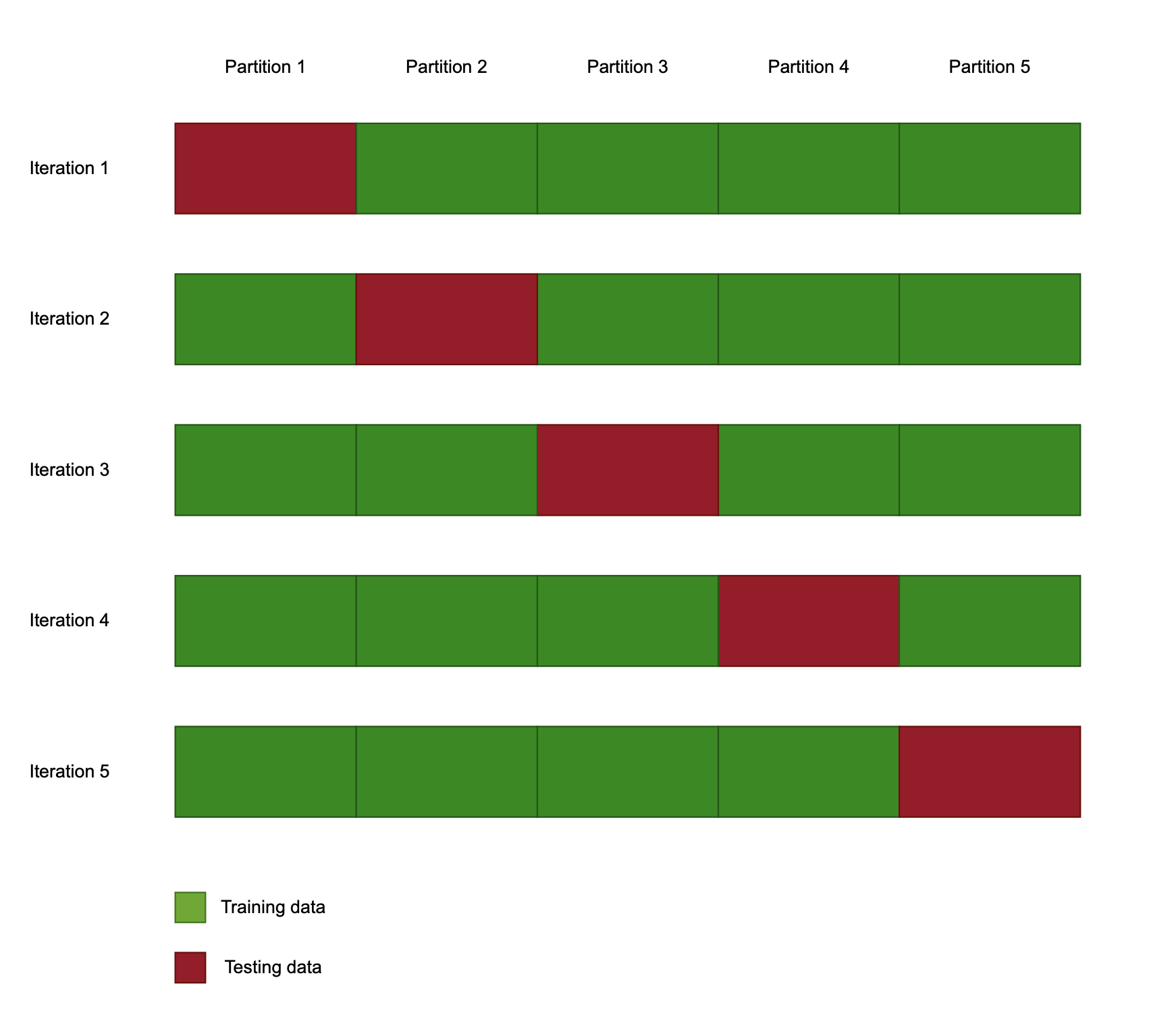
Uso da validação cruzada
- Implementação simples de k-fold com sklearn
- Métrica independente do modelo
Uso:
from sklearn.model_selection import cross_val_score, KFold # divide os dados em 10 partes iguais kfold = KFold(n_splits=5, shuffle=True, random_state=42)# obtém a acurácia da validação cruzada para um modelo cv_results = cross_val_score(model, heart_disease_X, heart_disease_y, cv=kfold, scoring='balanced_accuracy')
Ajuste de hiperparâmetros
Hiperparâmetro:
- Parâmetro global do modelo (não muda no treino)
- Ajuste para melhorar o desempenho
# Hyperparameters to test
C_values = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
# Manually iterate over the hyperparameters
for C in C_values:
model = LogisticRegression(max_iter=200, C=C)
model.fit(X_train, y_train)
accuracy = cross_val_score(model, X, y, cv=kfold, scoring='balanced_accuracy')
print(f"C = {C}: Bal Acc: {accuracy.mean():.4f} (+/- {accuracy.std():.4f})")
Exemplo de ajuste de hiperparâmetros
Exemplo de saída do ajuste de hiperparâmetros:
C = 0.001: Bal Acc: 0.6200 (+/- 0.0215)
C = 0.01: Bal Acc: 0.7325 (+/- 0.0234)
C = 0.1: Bal Acc: 0.7923 (+/- 0.0202)
C = 1: Bal Acc: 0.8050 (+/- 0.0191)
C = 10: Bal Acc: 0.8034 (+/- 0.0185)
C = 100: Bal Acc: 0.8021 (+/- 0.0187)
C = 1000: Bal Acc: 0.8017 (+/- 0.0188)
Vamos praticar!
Machine Learning de ponta a ponta

