Engenharia e seleção de features
Machine Learning de ponta a ponta

Joshua Stapleton
Machine Learning Engineer
Engenharia de features
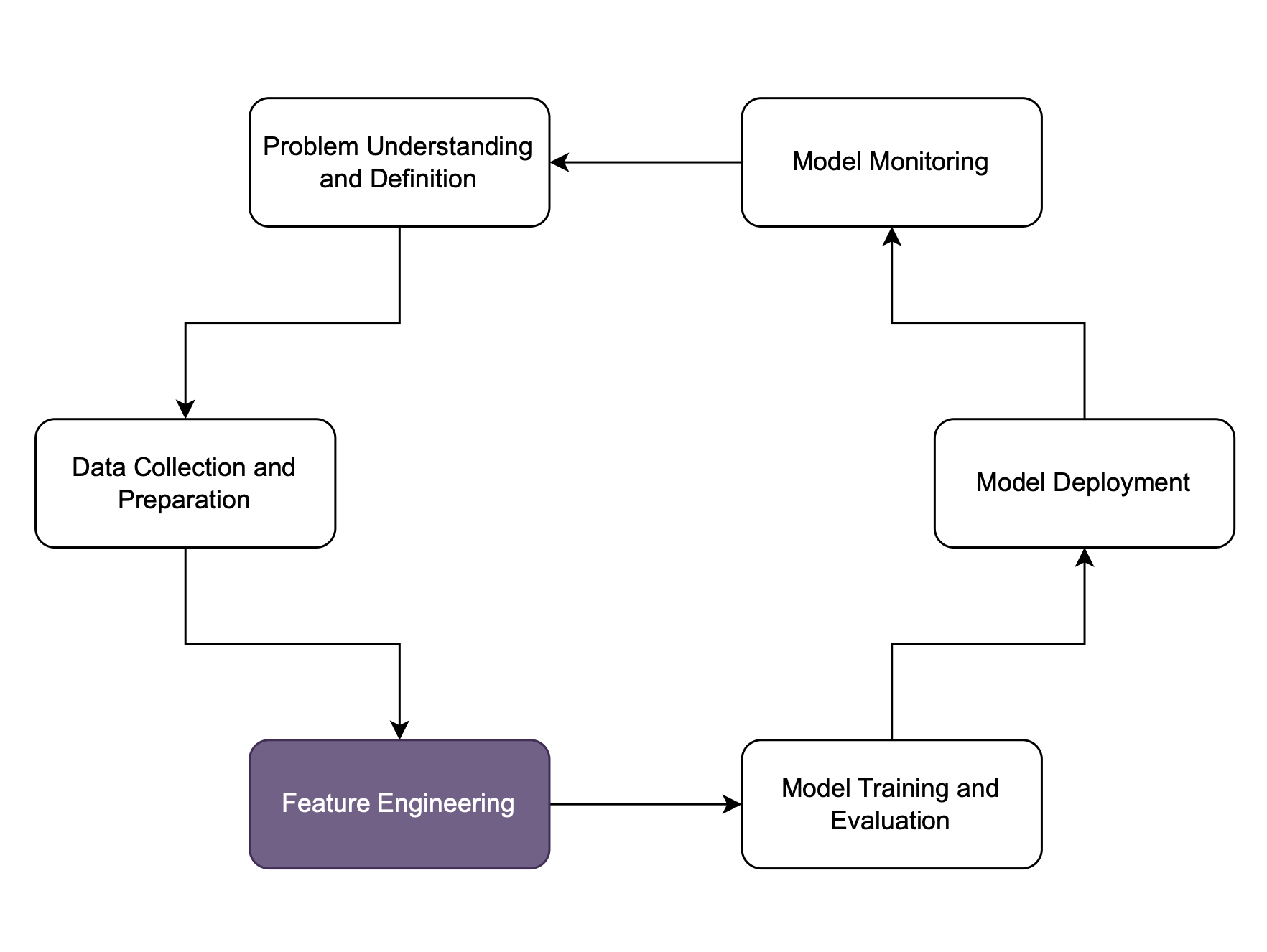
O que é uma boa feature?
- Use features relevantes
- O clima no dia da consulta não deve afetar o diagnóstico

- Use features distintas (ortogonais)
- Idade em meses e em anos não ajuda