Métodos de Monte Carlo
Reinforcement Learning com Gymnasium em Python

Fouad Trad
Machine Learning Engineer
Recap: aprendizado com modelo
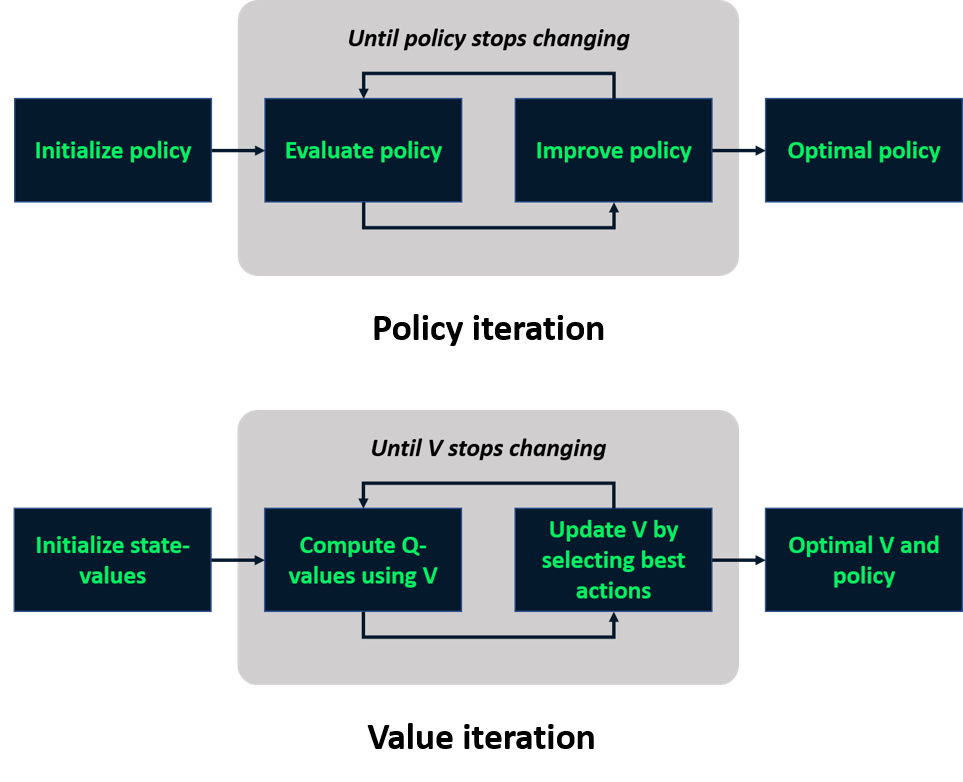
Aprendizado sem modelo

Métodos de Monte Carlo
- Técnicas sem modelo
- Estimam Q-values a partir de episódios
Métodos de Monte Carlo
- Técnicas sem modelo
- Estimam Q-values a partir de episódios

Métodos de Monte Carlo
- Técnicas sem modelo
- Estimam Q-values a partir de episódios

- Dois métodos: primeira-visita, toda-visita
Grid world customizado
Coletando dois episódios
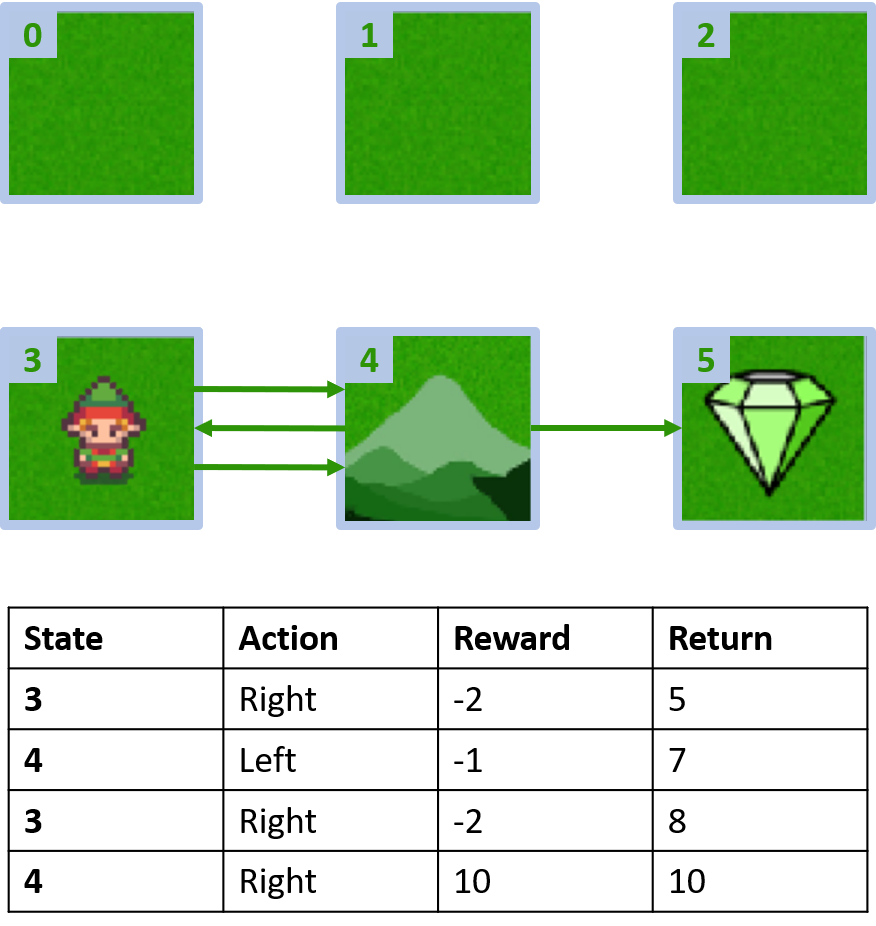
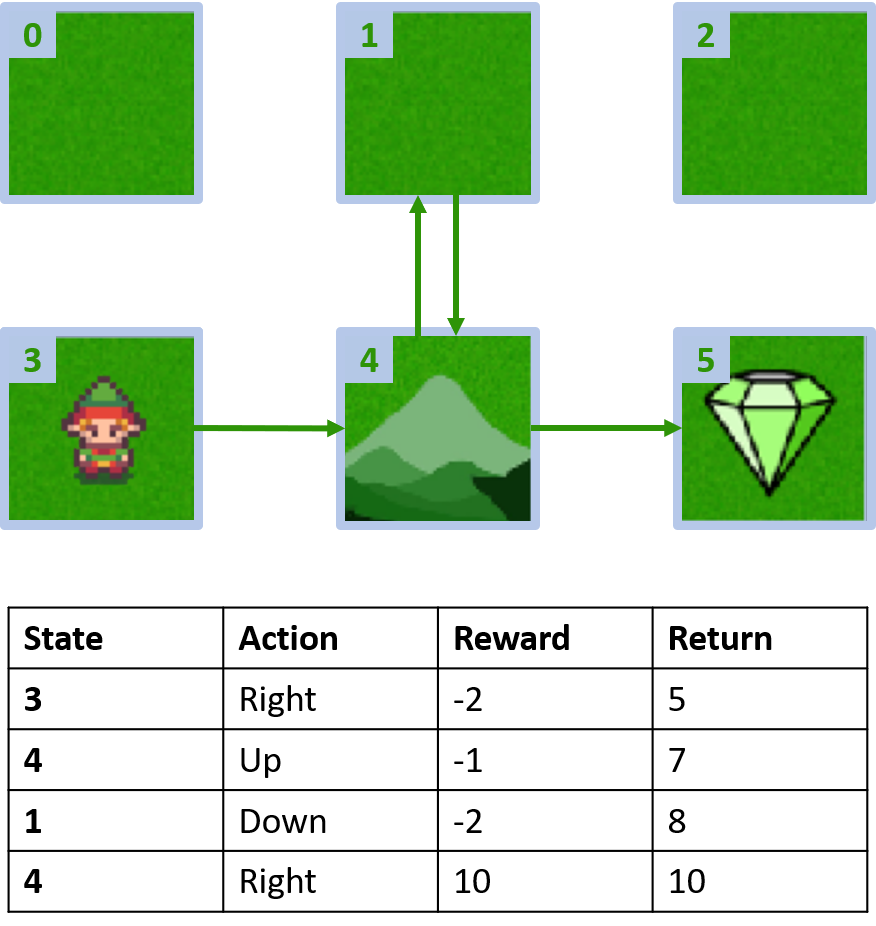
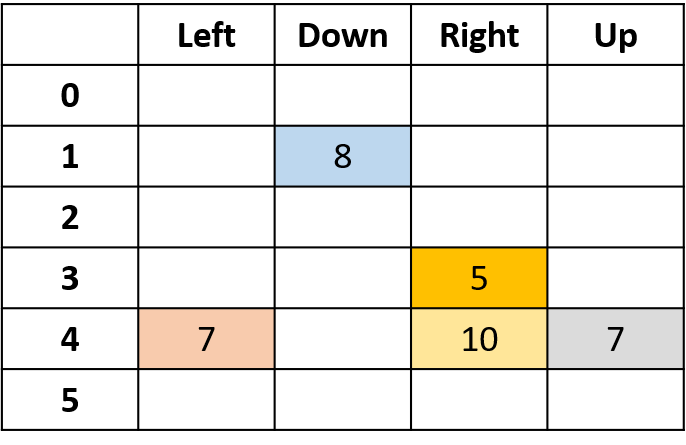
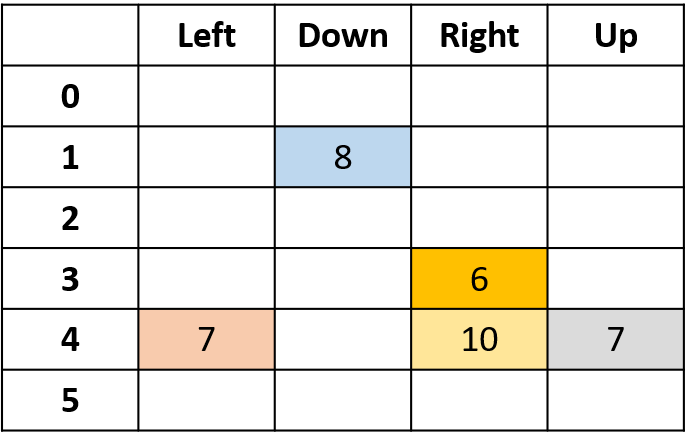
Estimando Q-values
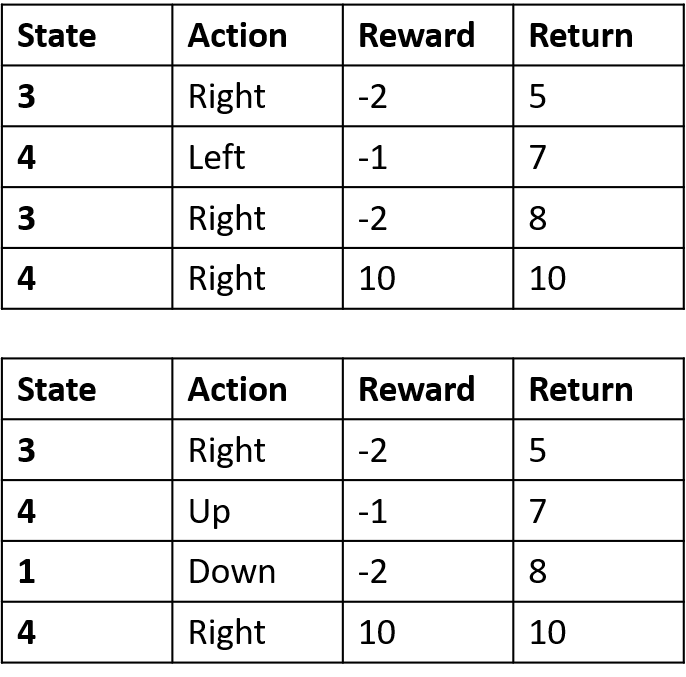
- Q-table: tabela de Q-values
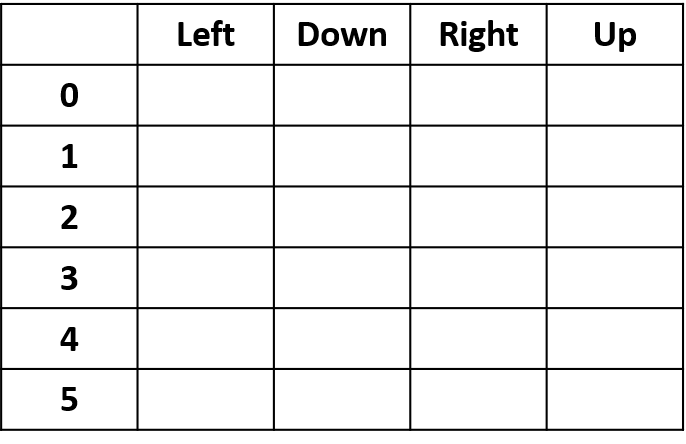
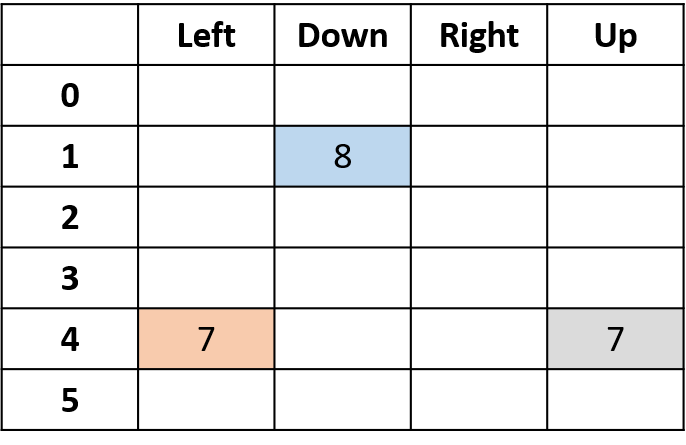
Q(4, esquerda), Q(4, cima) e Q(1, baixo)
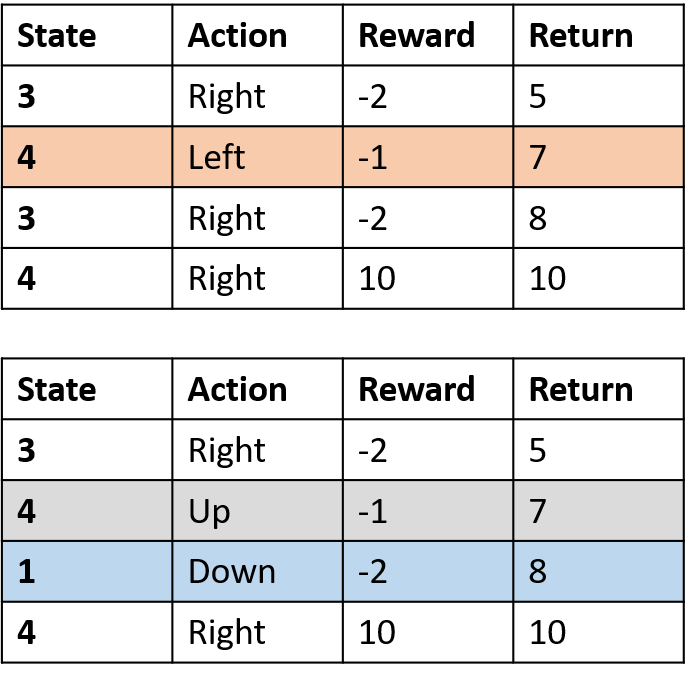
- (s,a) aparece uma vez -> preenche com o retorno
Q(4, direita)
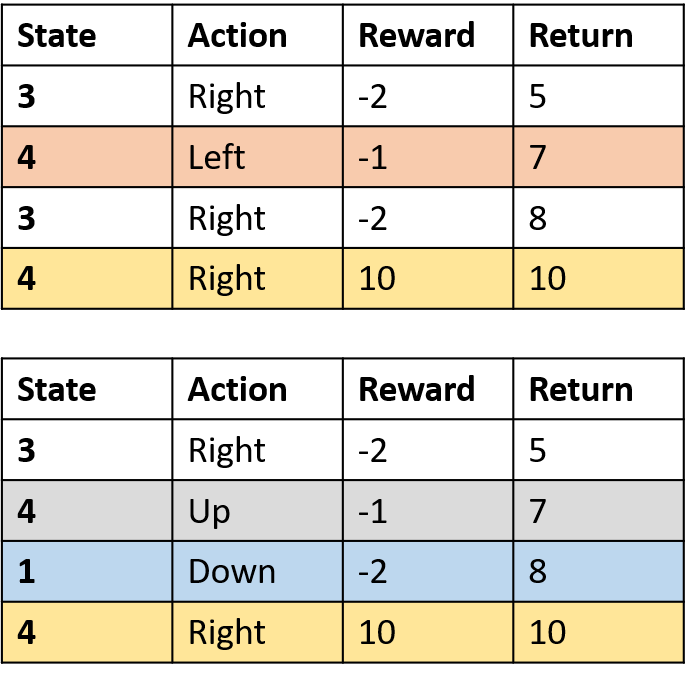
- (s,a) ocorre uma vez por episódio -> faça a média
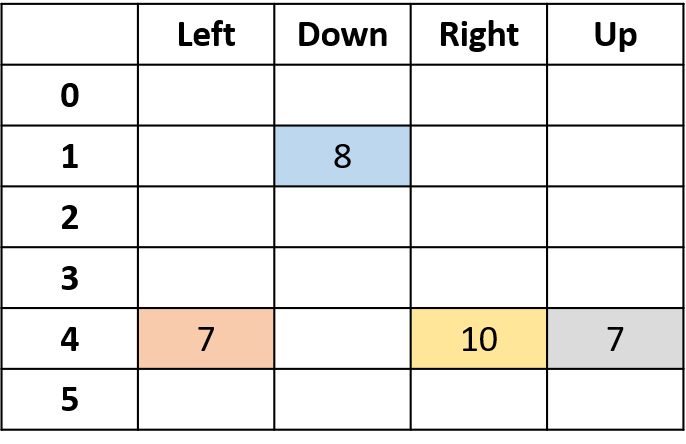
Q(3, direita) - Monte Carlo de primeira visita
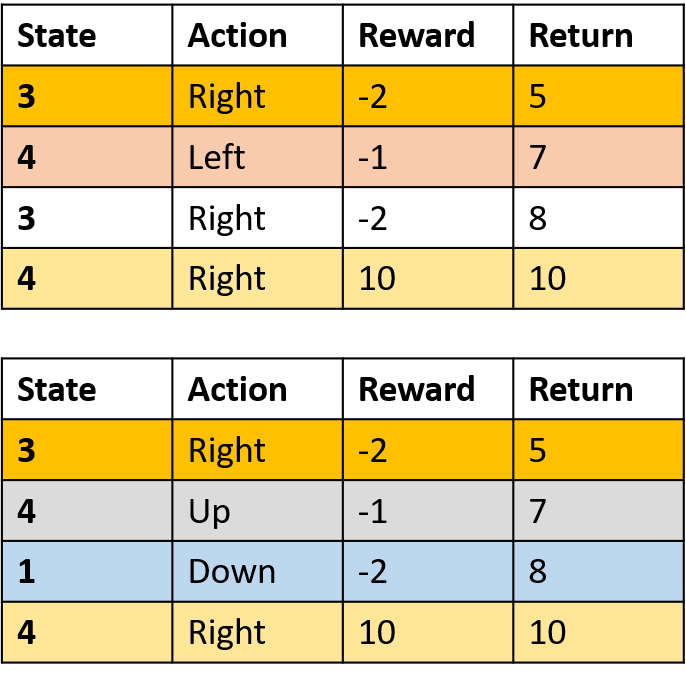
- Faça a média da primeira visita a (s,a) nos episódios
Q(3, direita) - Monte Carlo de toda visita
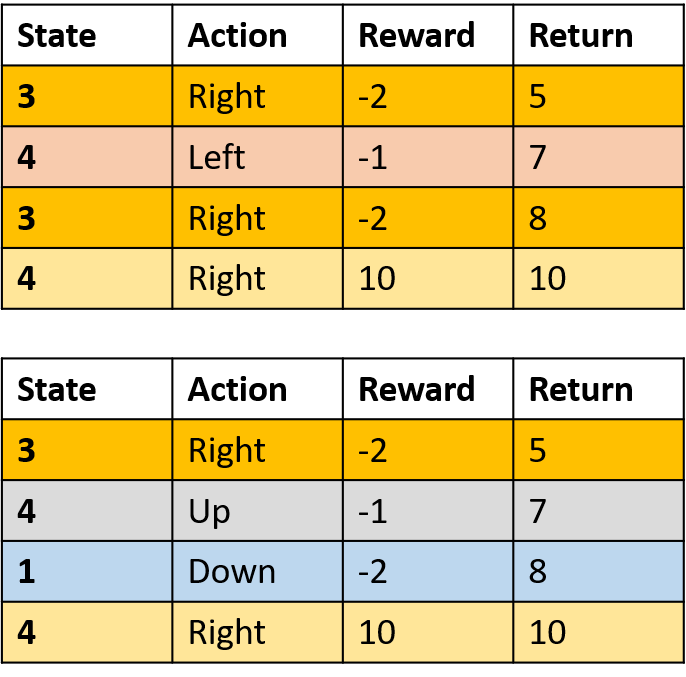
- Faça a média de todas as visitas a (s,a) nos episódios
Juntando tudo