Double Q-learning
Reinforcement Learning com Gymnasium em Python

Fouad Trad
Machine Learning Engineer
Q-learning
- Estima a função ótica de valor-ação
- Superestima Q ao atualizar pelo Q máximo
- Pode levar a uma política subótima

Double Q-learning
- Mantém duas tabelas Q
- Cada tabela é atualizada com base na outra
- Reduz o risco de superestimar Q
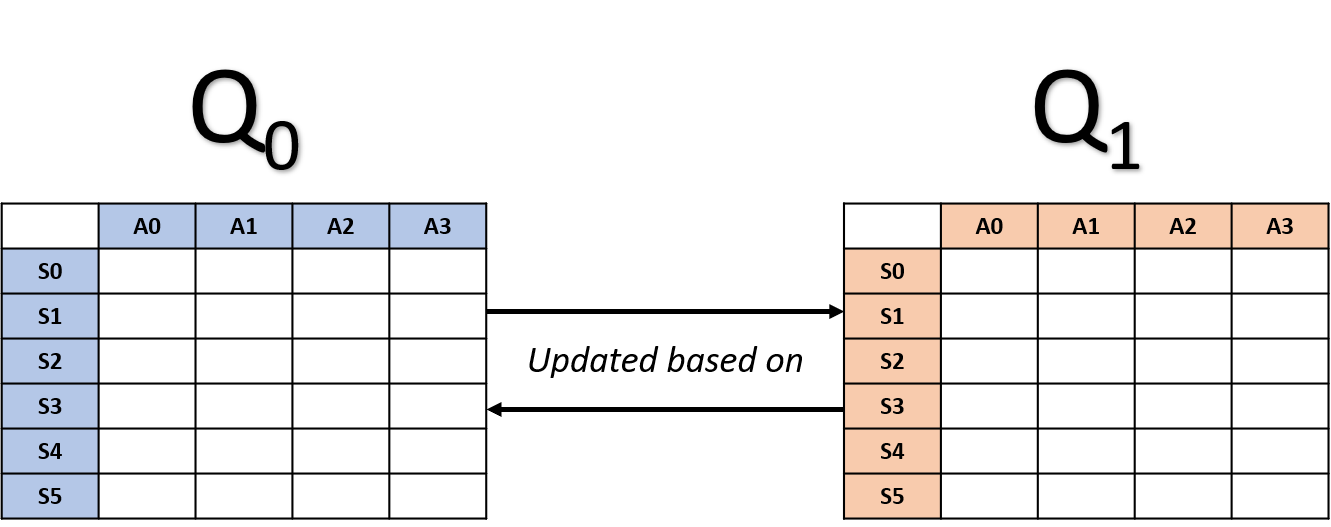
Atualizações no Double Q-learning
- Seleciona uma tabela aleatoriamente
Atualização de Q0
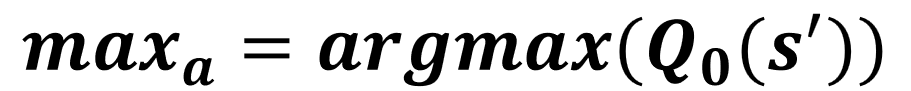
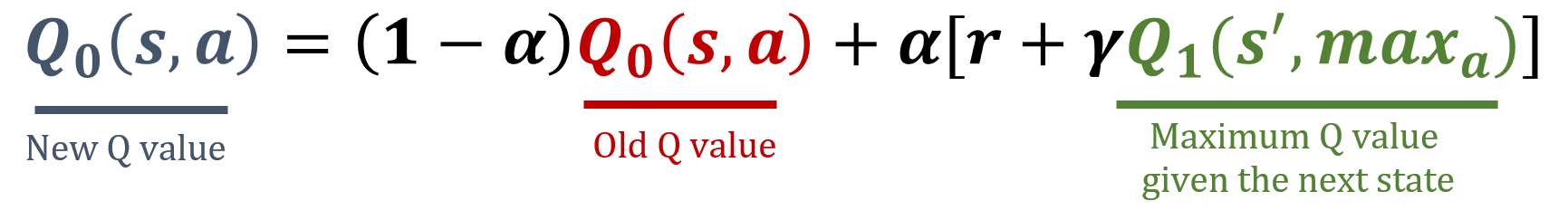
Atualização de Q1
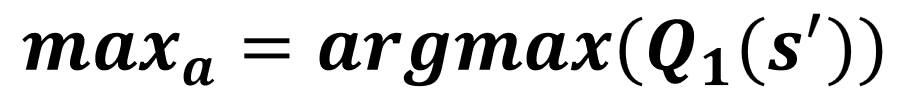
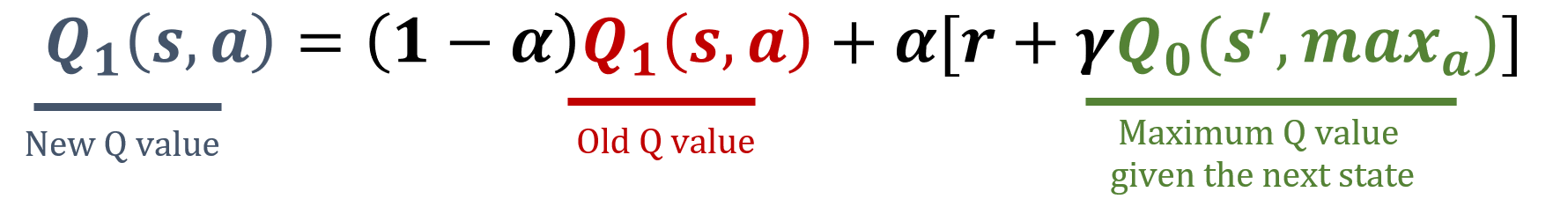
Double Q-learning
- Reduz viés de superestimação
- Alterna entre atualizações de Q0 e Q1
- As duas tabelas contribuem para o aprendizado
Implementação com Frozen Lake

Implementando update_q_tables()
def update_q_tables(state, action, reward, next_state): # Select a random Q-table index (0 or 1) i = np.random.randint(2)# Update the corresponding Q-table best_next_action = np.argmax(Q[i][next_state])Q[i][state, action] = (1 - alpha) * Q[i][state, action] + alpha * (reward + gamma * Q[1-i][next_state, best_next_action])
Política do agente