Iteração de políticas e iteração de valores
Reinforcement Learning com Gymnasium em Python

Fouad Trad
Machine Learning Engineer
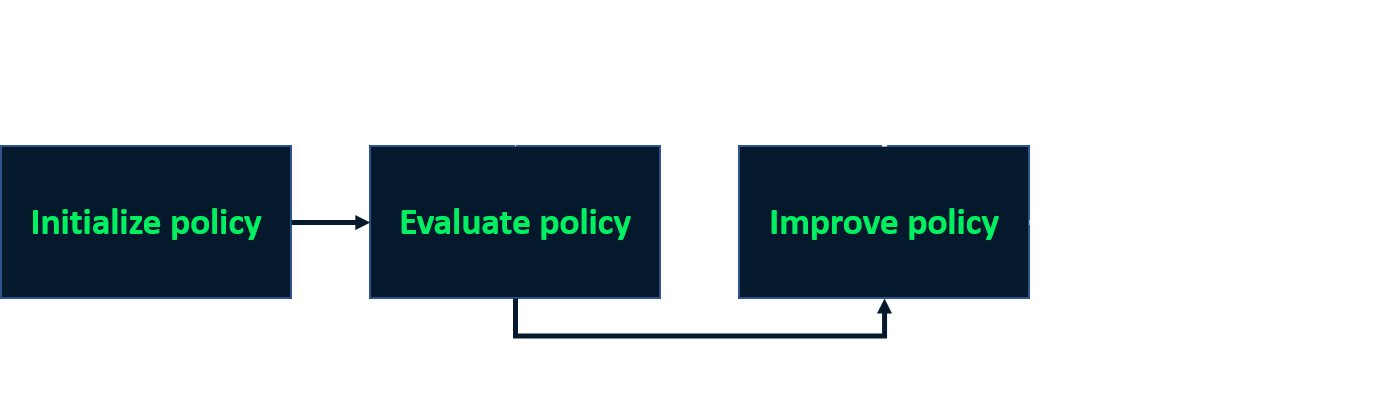
Iteração de políticas
- Processo iterativo para achar a política ideal

Iteração de políticas
- Processo iterativo para achar a política ideal

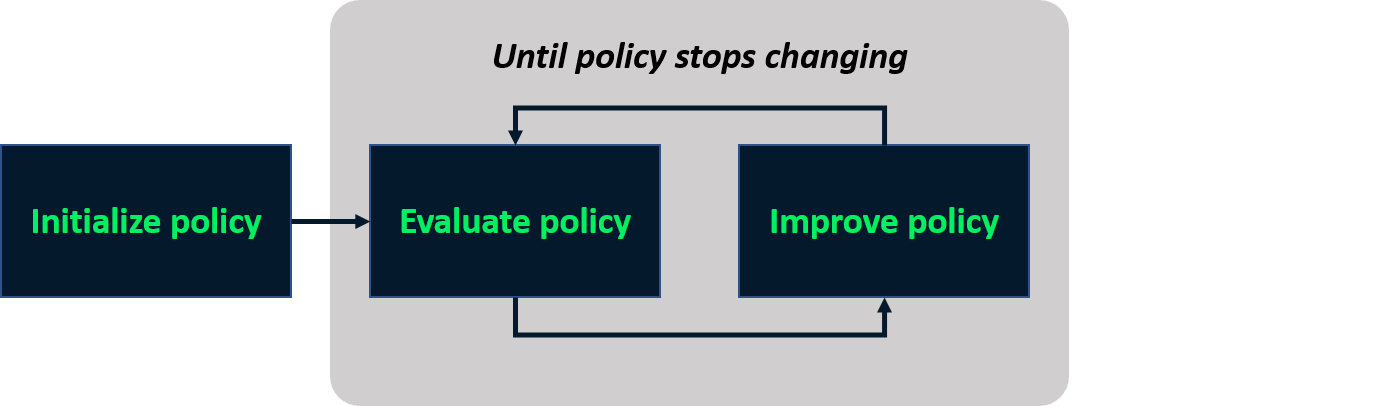
Iteração de políticas
- Processo iterativo para achar a política ideal
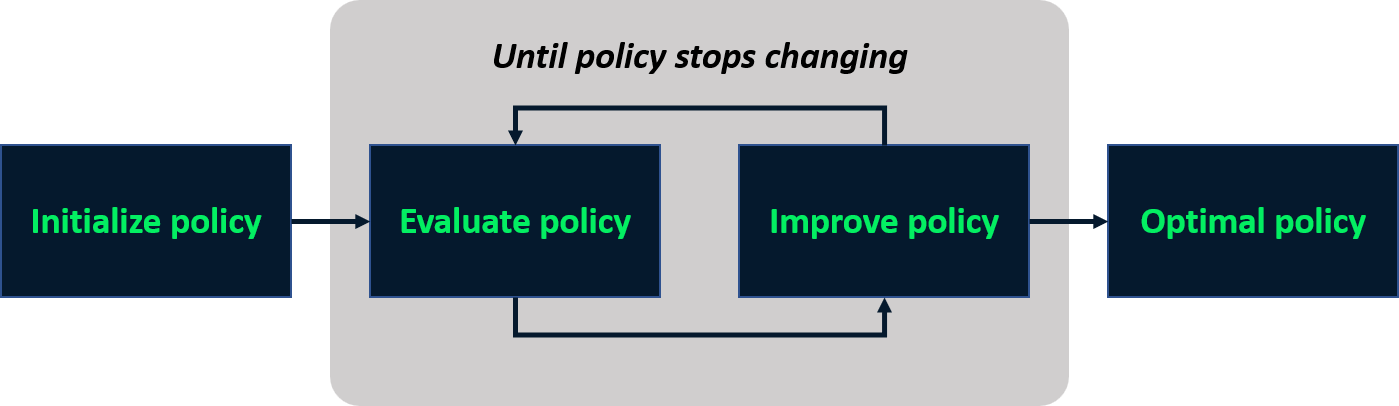
Iteração de políticas
- Processo iterativo para achar a política ideal
Iteração de políticas
- Processo iterativo para achar a política ideal
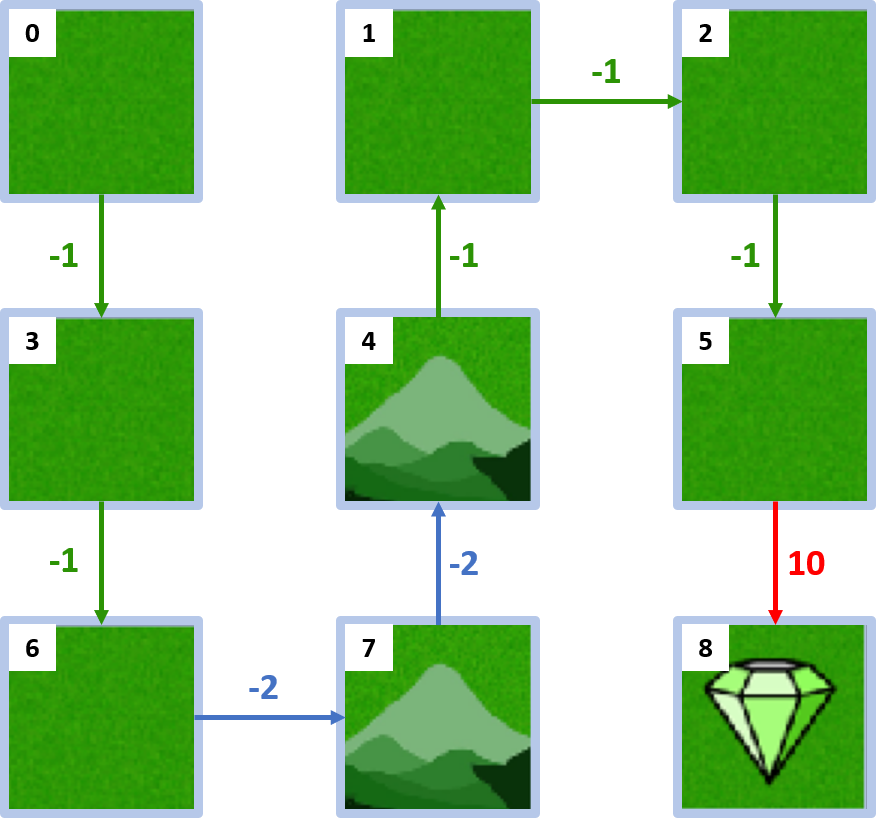
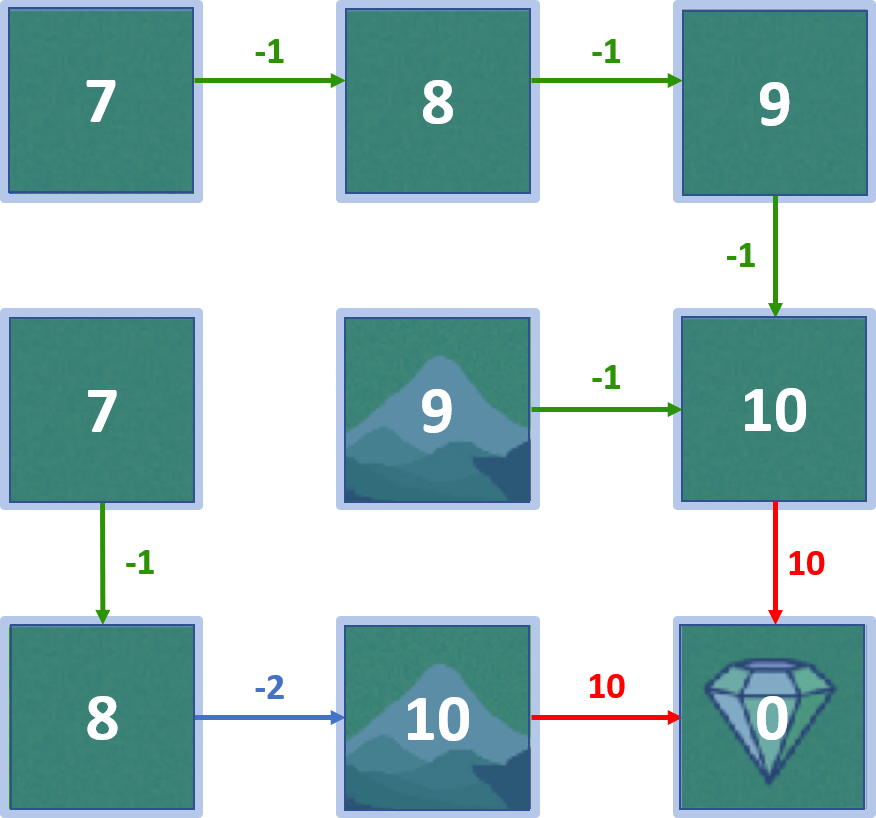
Mundo em grade
Política ótima
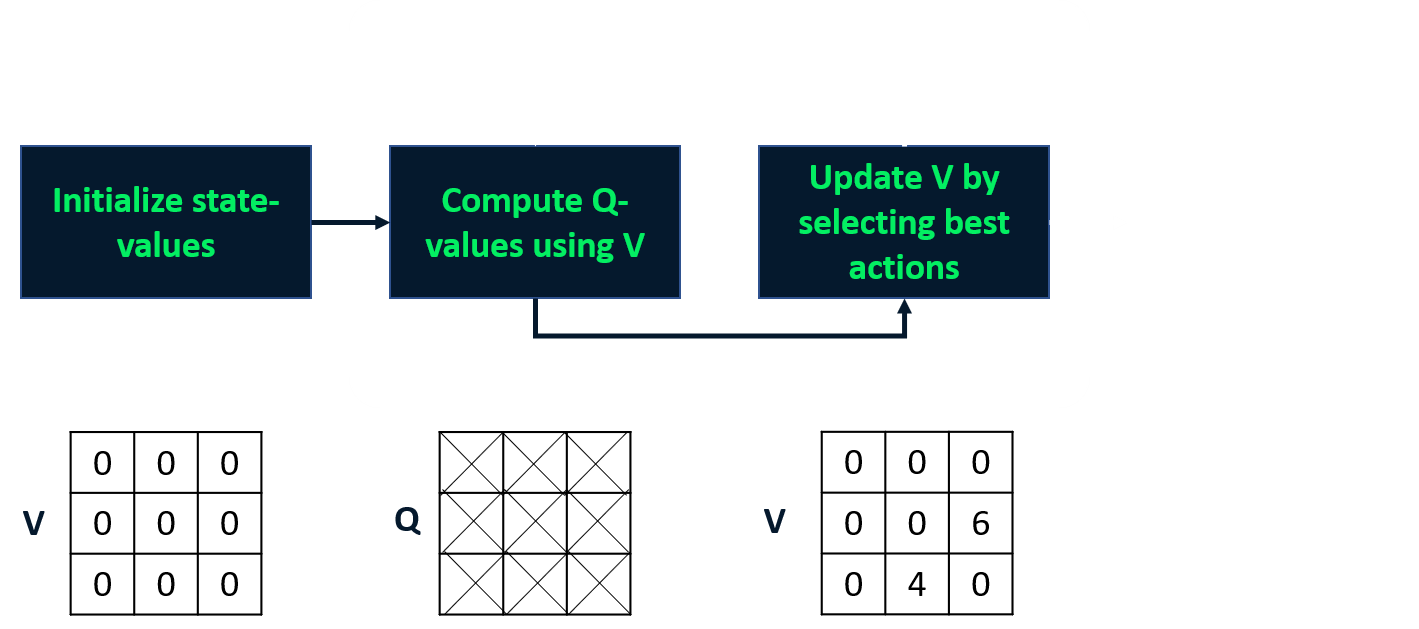
Iteração de valores
- Combina avaliação e melhoria da política em um passo
- Calcula a função de valor de estado ótima
- Deriva a política a partir dela

Iteração de valores
- Combina avaliação e melhoria da política em um passo.
- Calcula a função de valor de estado ótima
- Deriva a política a partir dela

Iteração de valores
- Combina avaliação e melhoria da política em um passo.
- Calcula a função de valor de estado ótima
- Deriva a política a partir dela
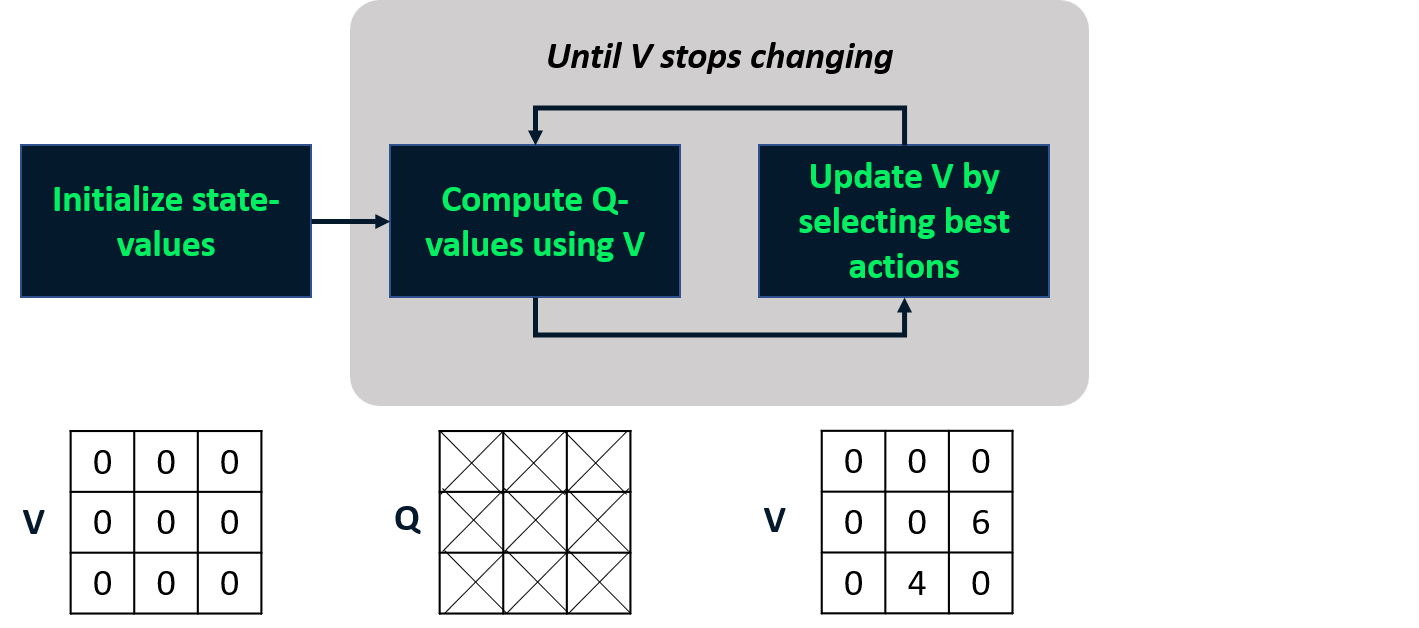
Iteração de valores
- Combina avaliação e melhoria da política em um passo.
- Calcula a função de valor de estado ótima
- Deriva a política a partir dela
Iteração de valores
- Combina avaliação e melhoria da política em um passo.
- Calcula a função de valor de estado ótima
- Deriva a política a partir dela
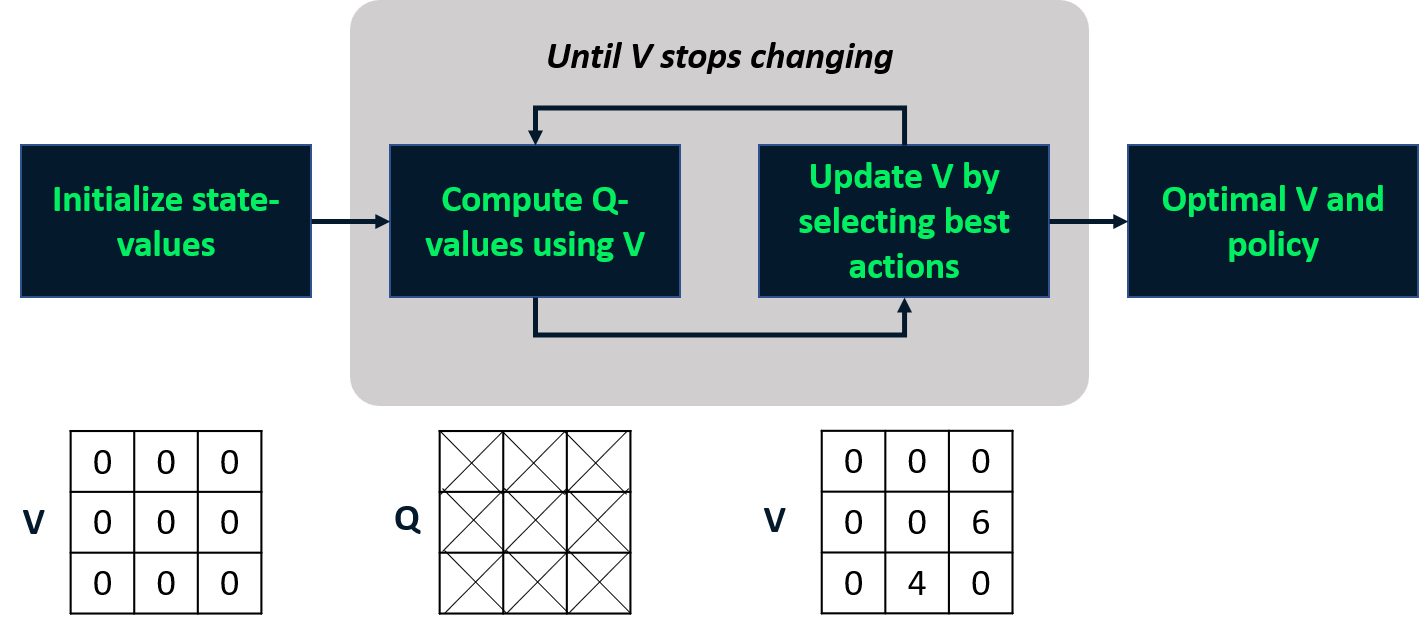
Política ótima

