Suréchantillonnage et interpolation avec .resample()
Manipuler des séries temporelles en Python

Stefan Jansen
Founder & Lead Data Scientist at Applied Artificial Intelligence
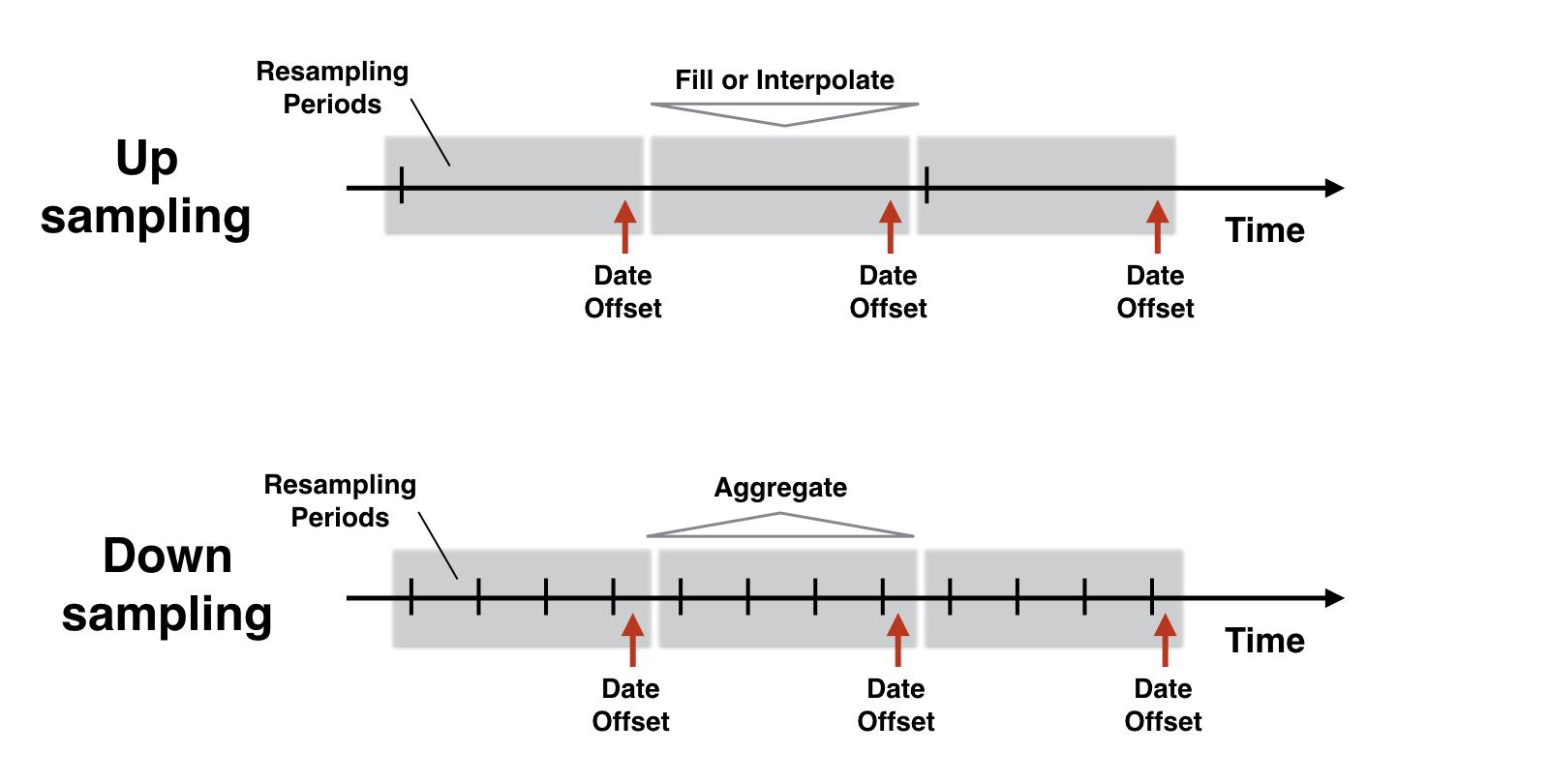
Logique du rééchantillonnage
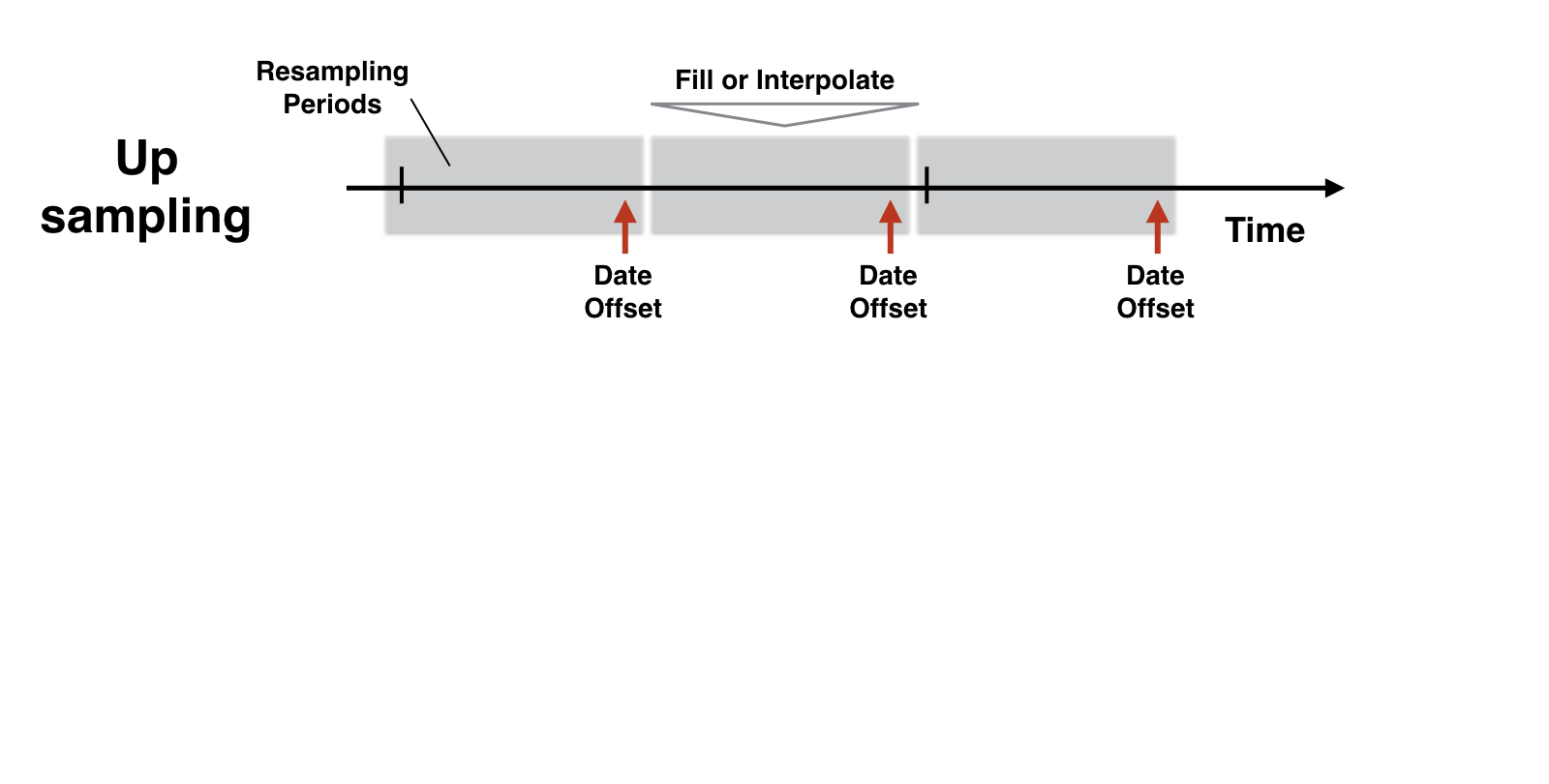
Logique du rééchantillonnage
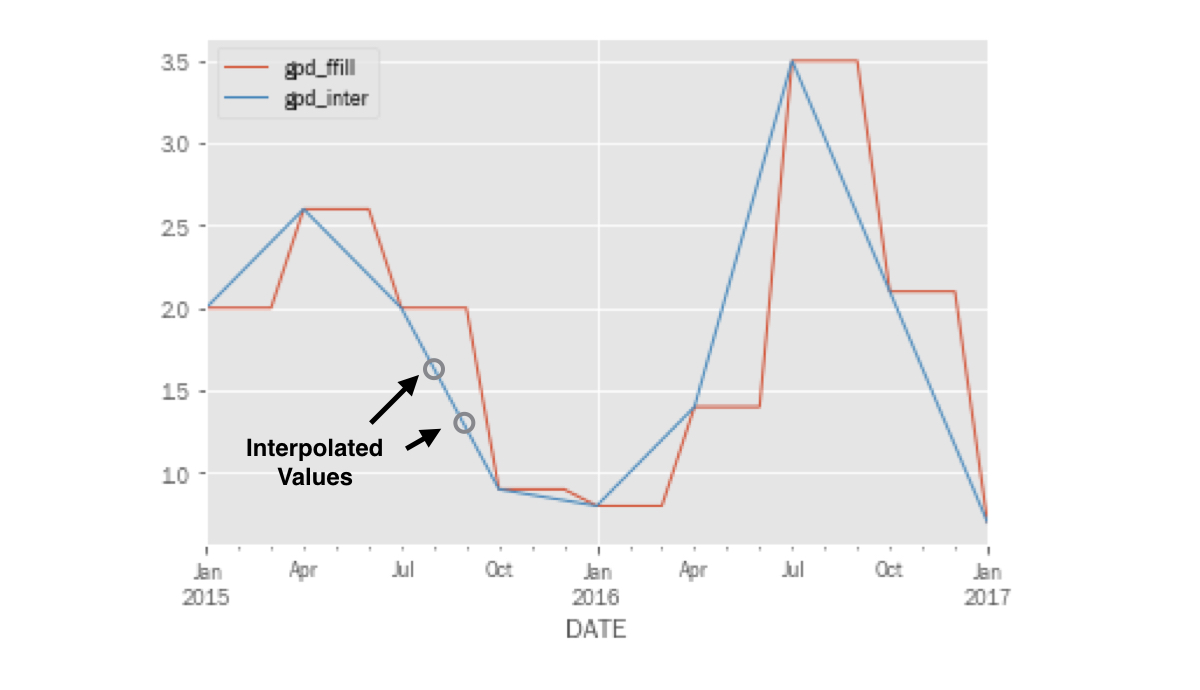
Tracer la croissance du PIB interpolée
pd.concat([gdp_1, gdp_2], axis=1).loc['2015':].plot()
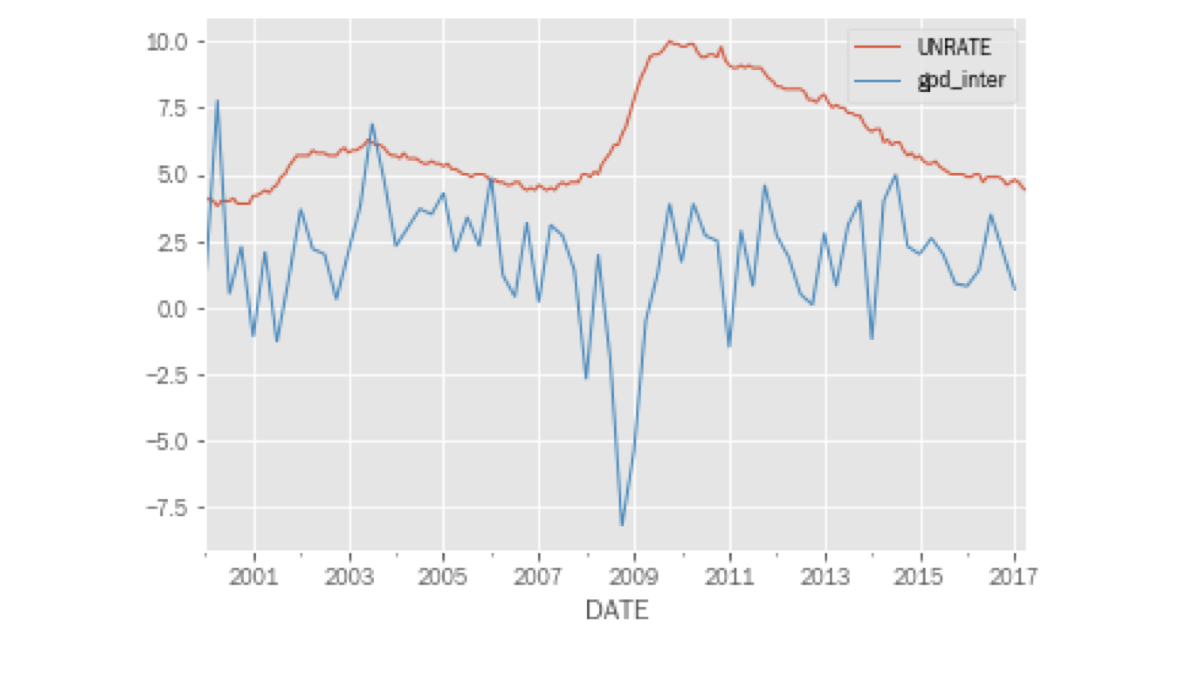
Combiner croissance du PIB et chômage
pd.concat([unrate, gdp_inter], axis=1).plot();