Otimização de IA: velocidade, custo e qualidade
Codificação com IA para Desenvolvedores

Francesca Donadoni
AI Curriculum Manager, DataCamp
Métricas

Métricas

Métricas

Benchmarking de modelos
$$
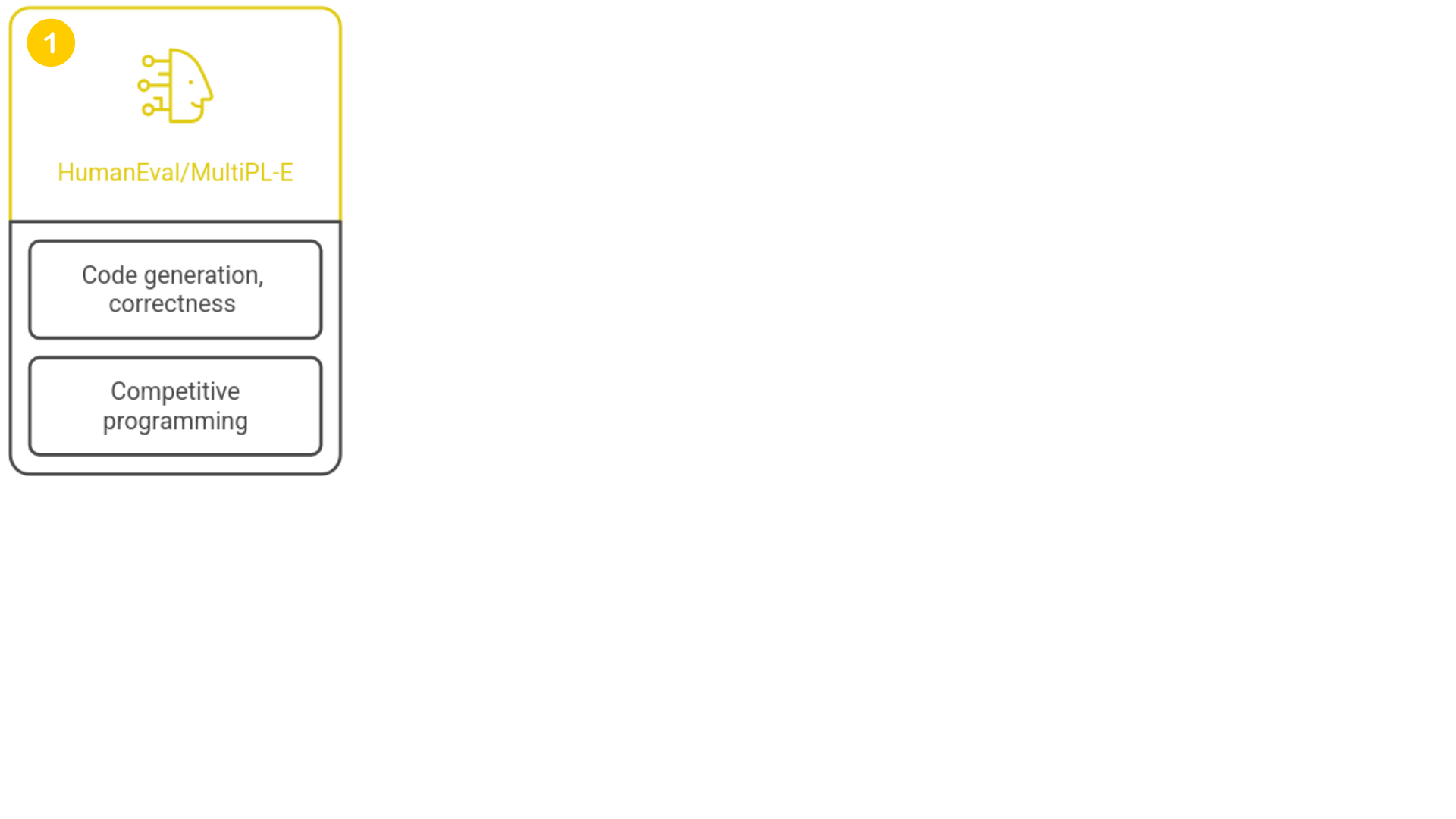
1 https://github.com/openai/human-eval
Benchmarking de modelos
$$
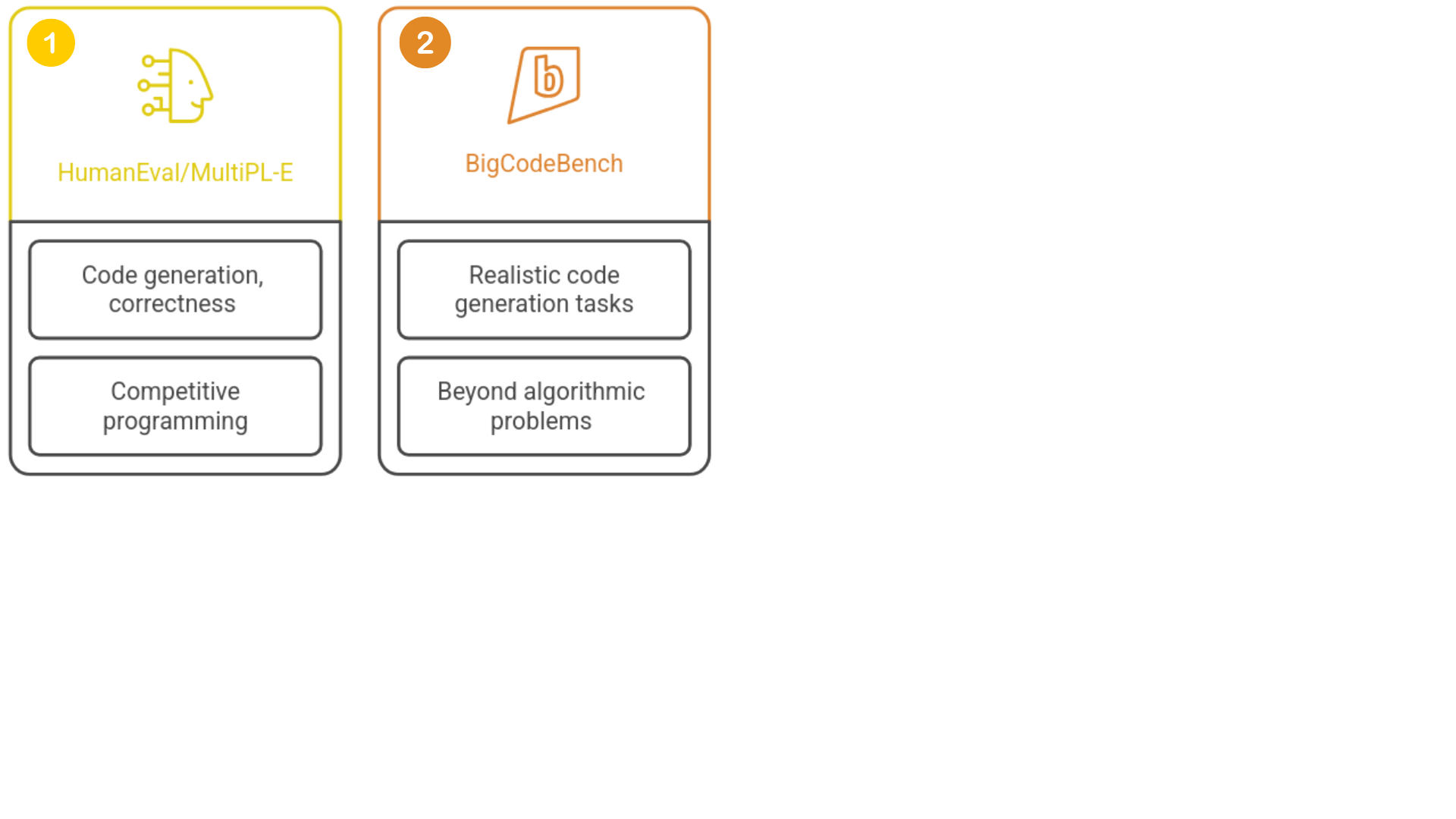
1 https://github.com/bigcode-project/bigcodebench
Benchmarking de modelos
$$
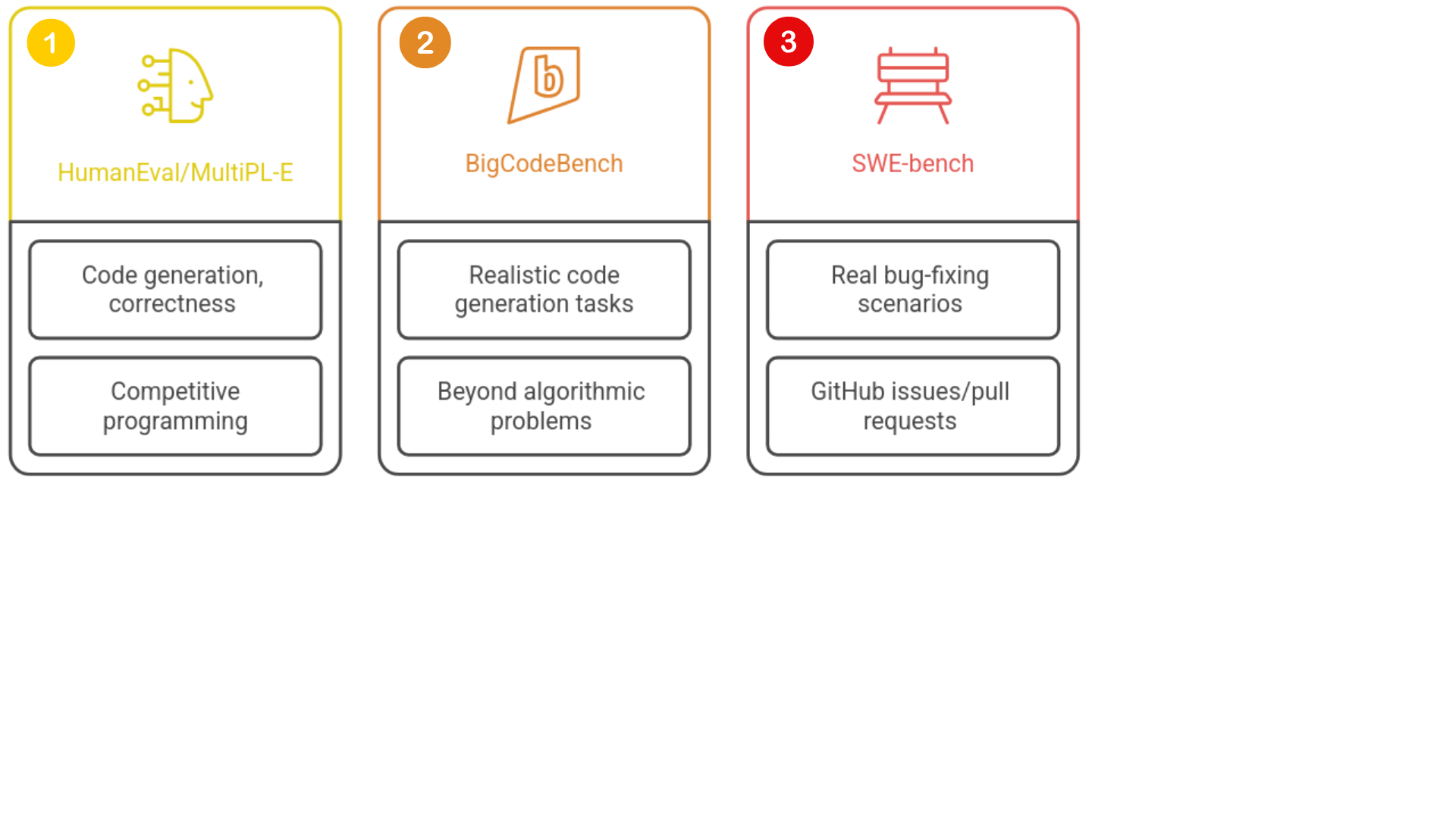
1 https://github.com/SWE-bench/SWE-bench
Benchmarking de modelos
$$
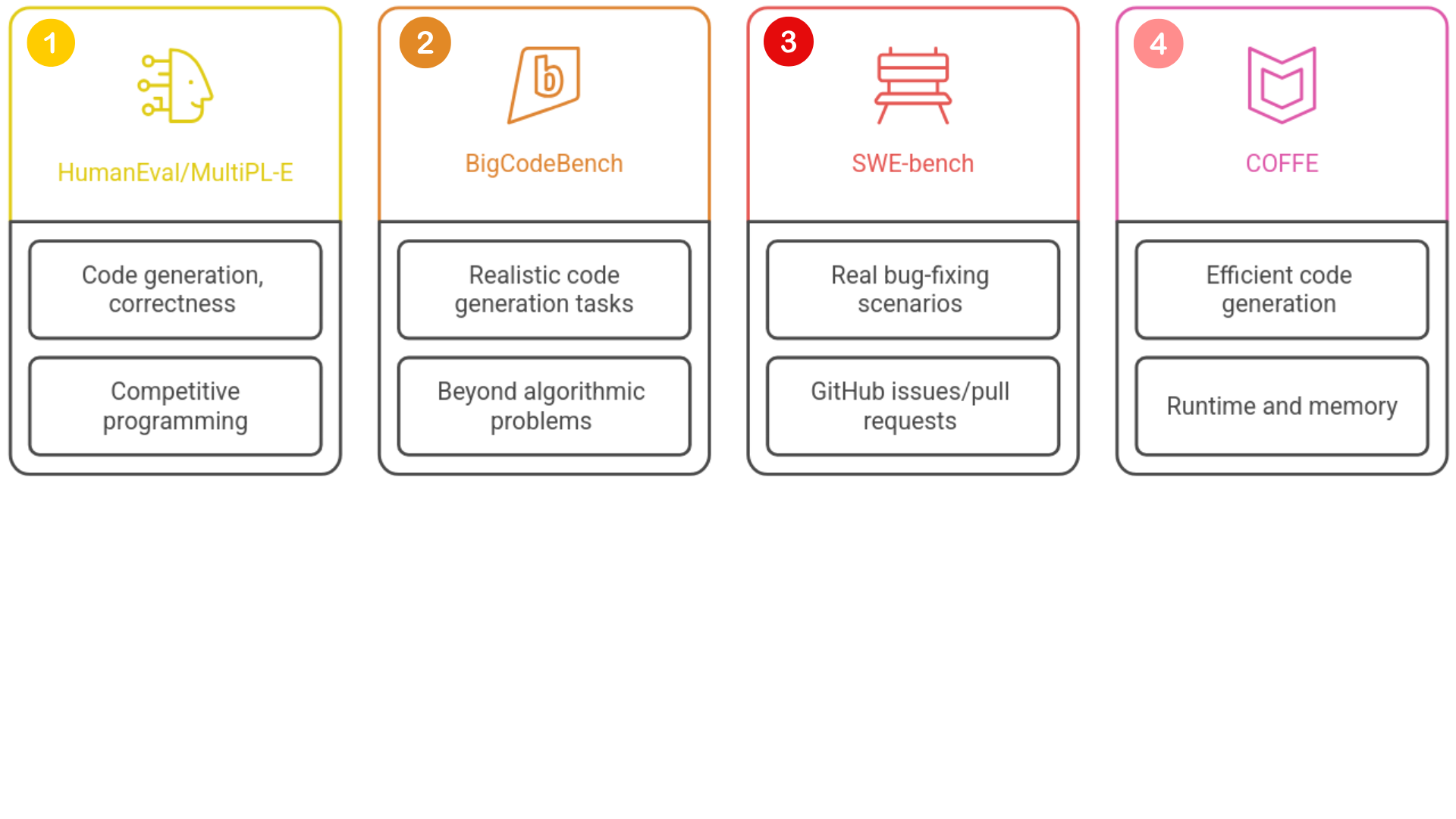
1 https://github.com/JohnnyPeng18/Coffe
Versionamento de prompts

Versionamento de prompts
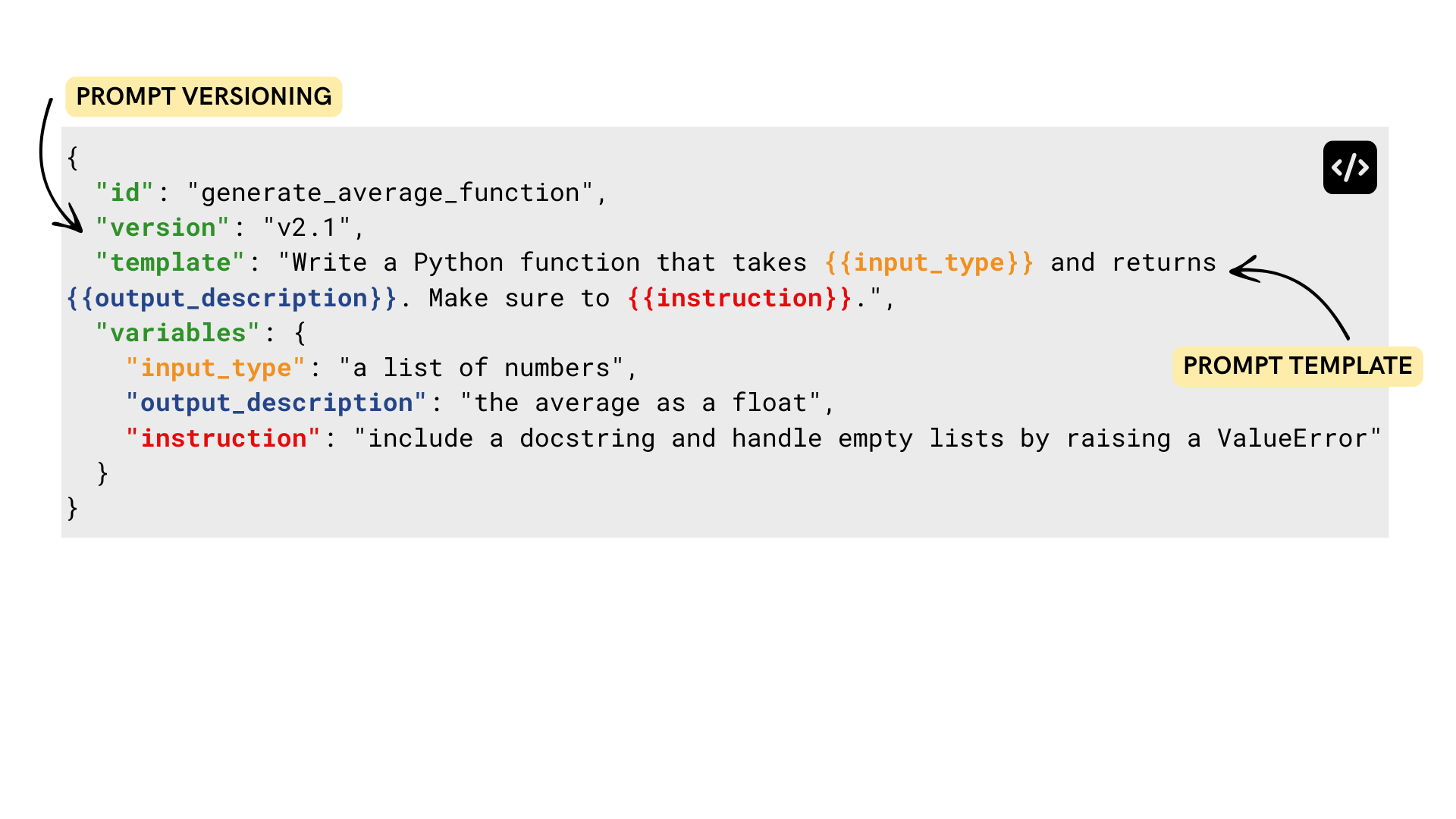
Versionamento de prompts

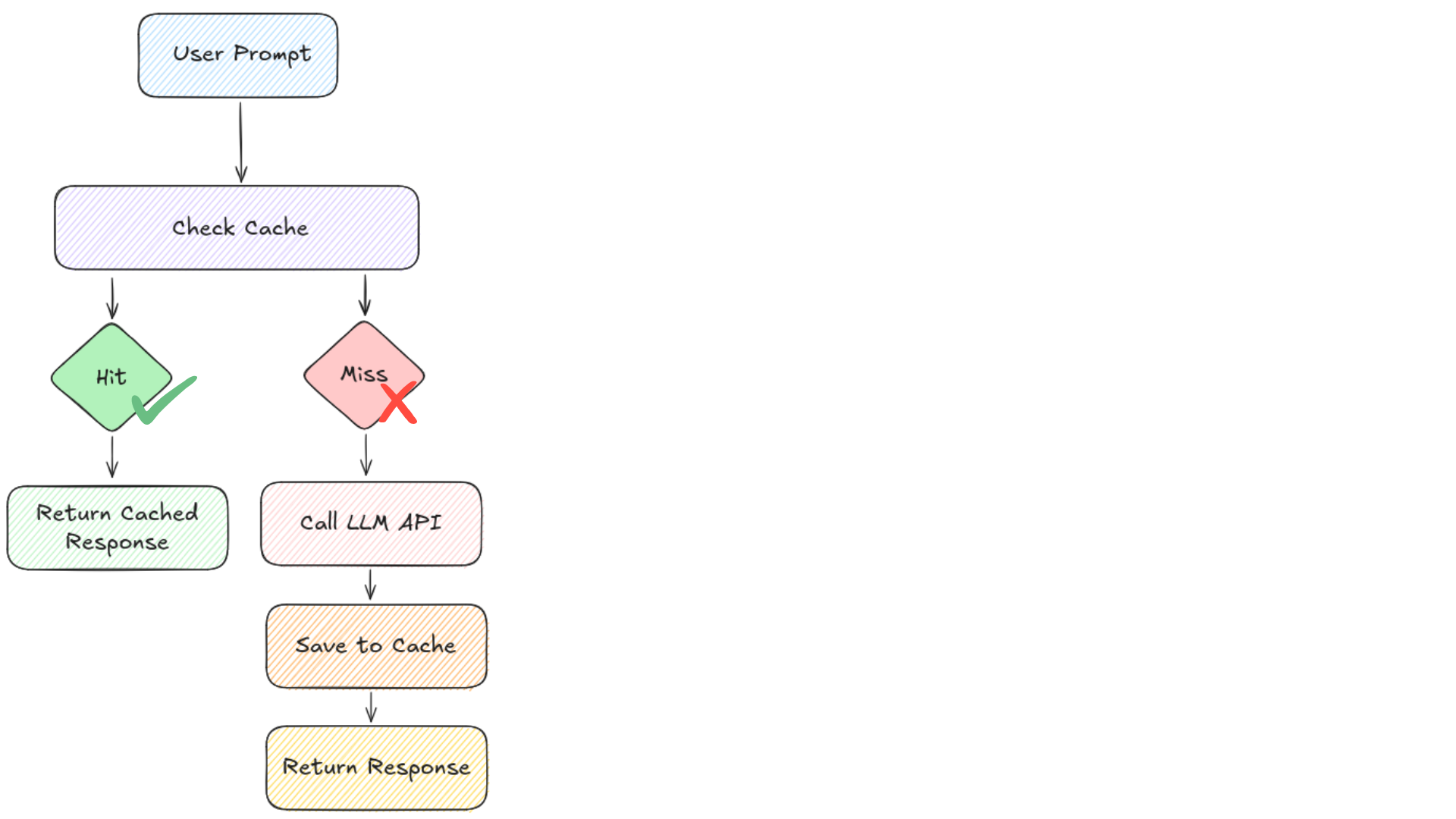
Cache de prompts