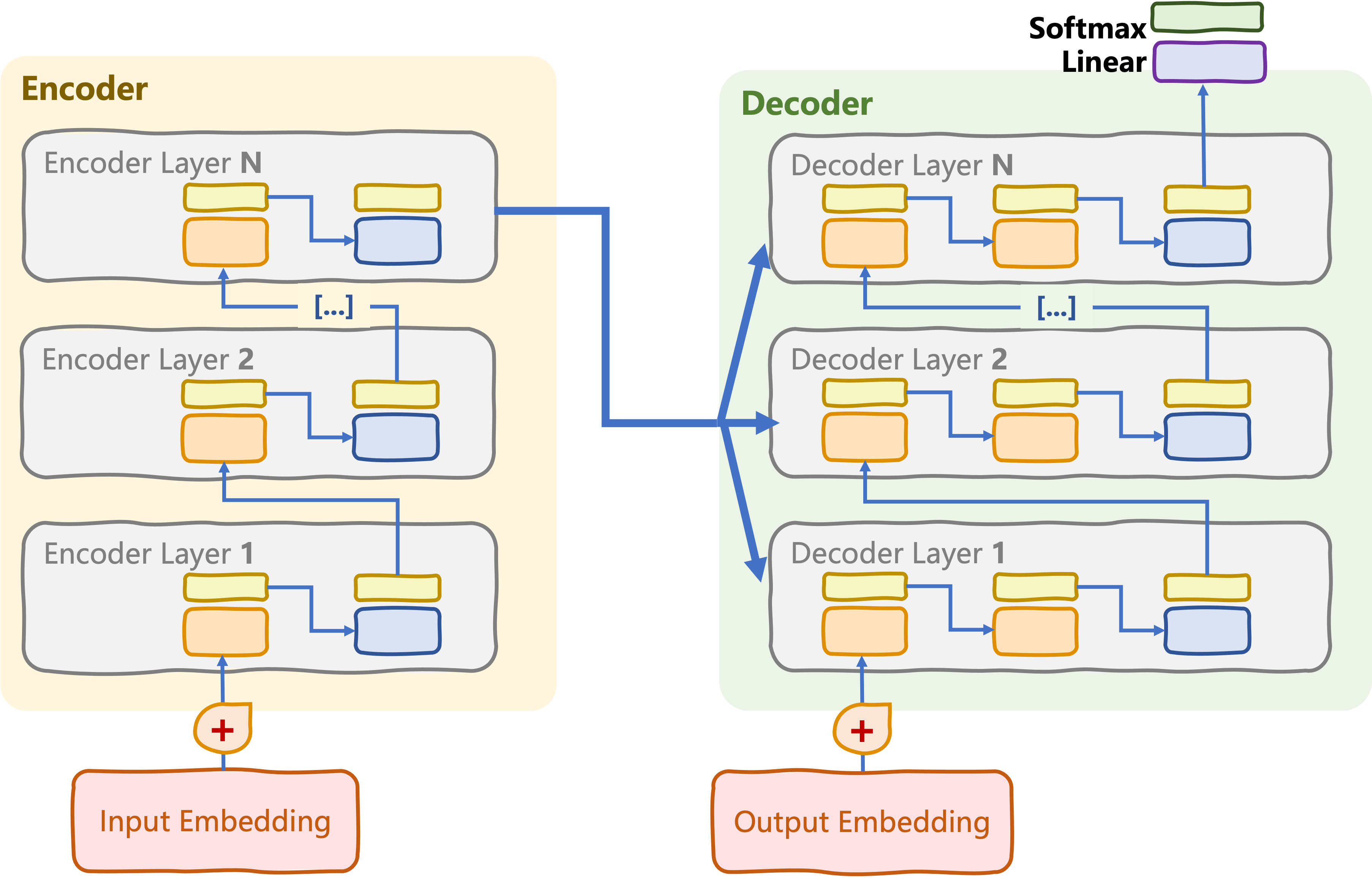
Encoder-decoder transformers
Modelli Transformer con PyTorch

James Chapman
Curriculum Manager, DataCamp
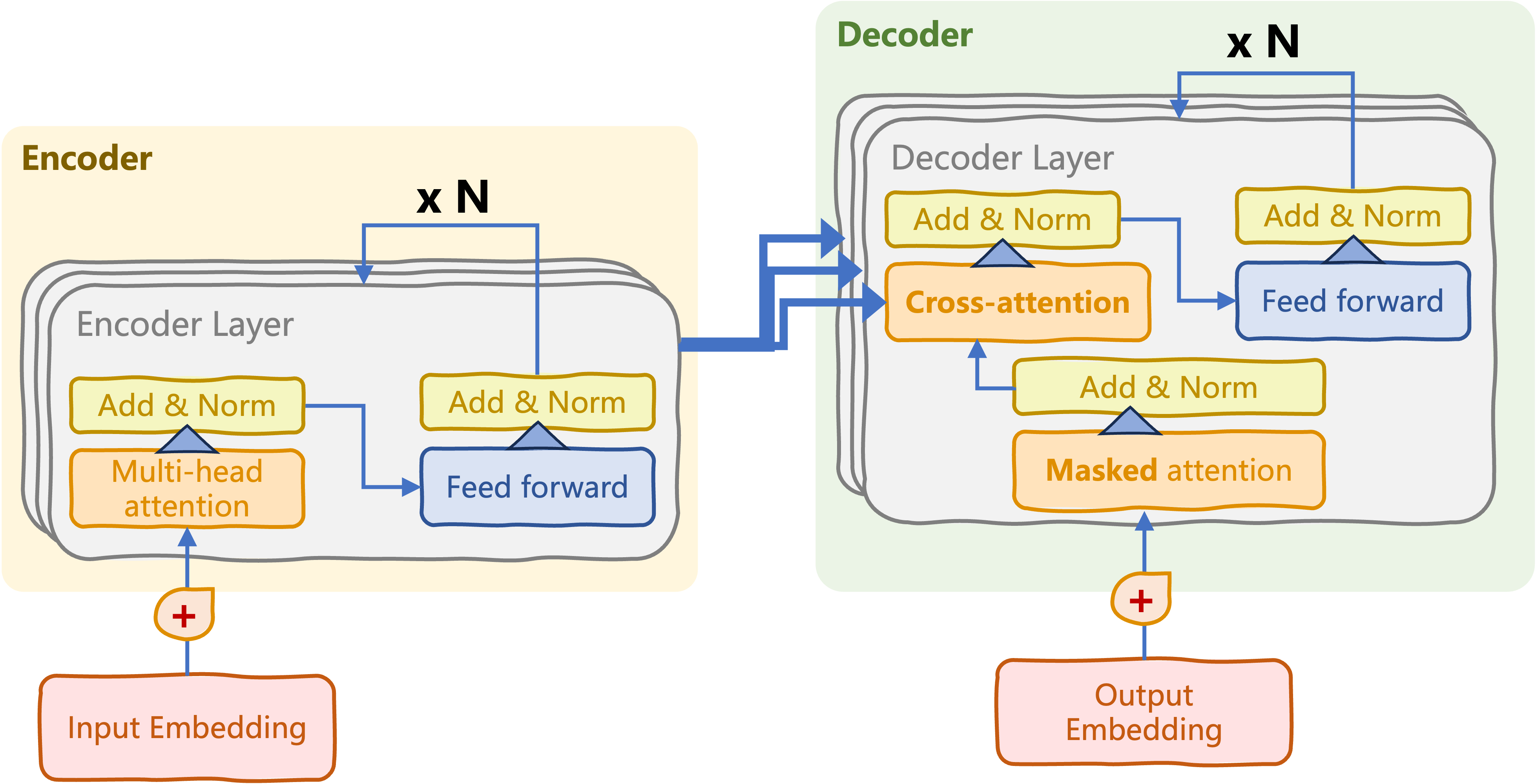
Encoder meets decoder
Encoder meets decoder
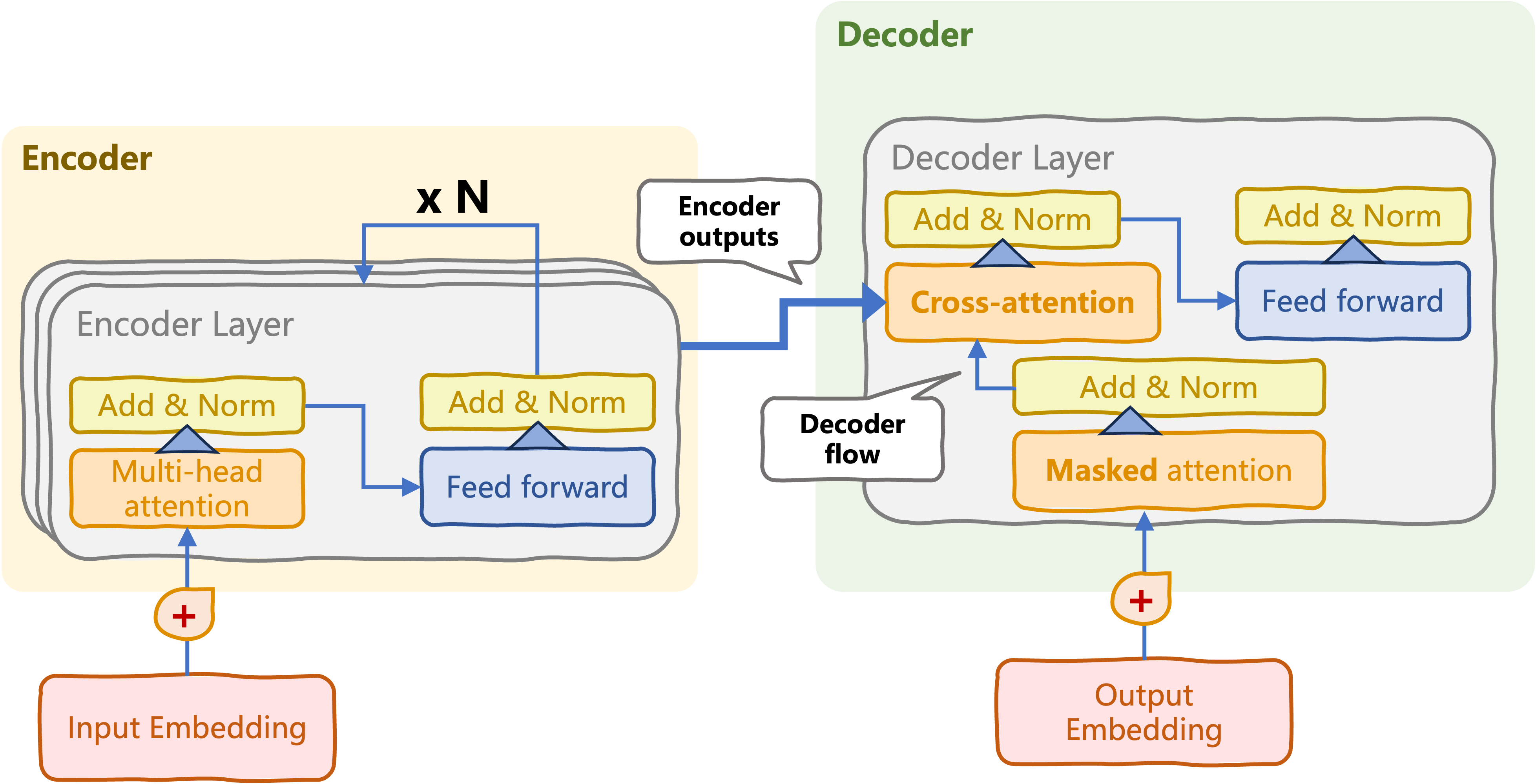
Cross-attention mechanism
- Information processed throughout decoder
- Final hidden states from encoder block
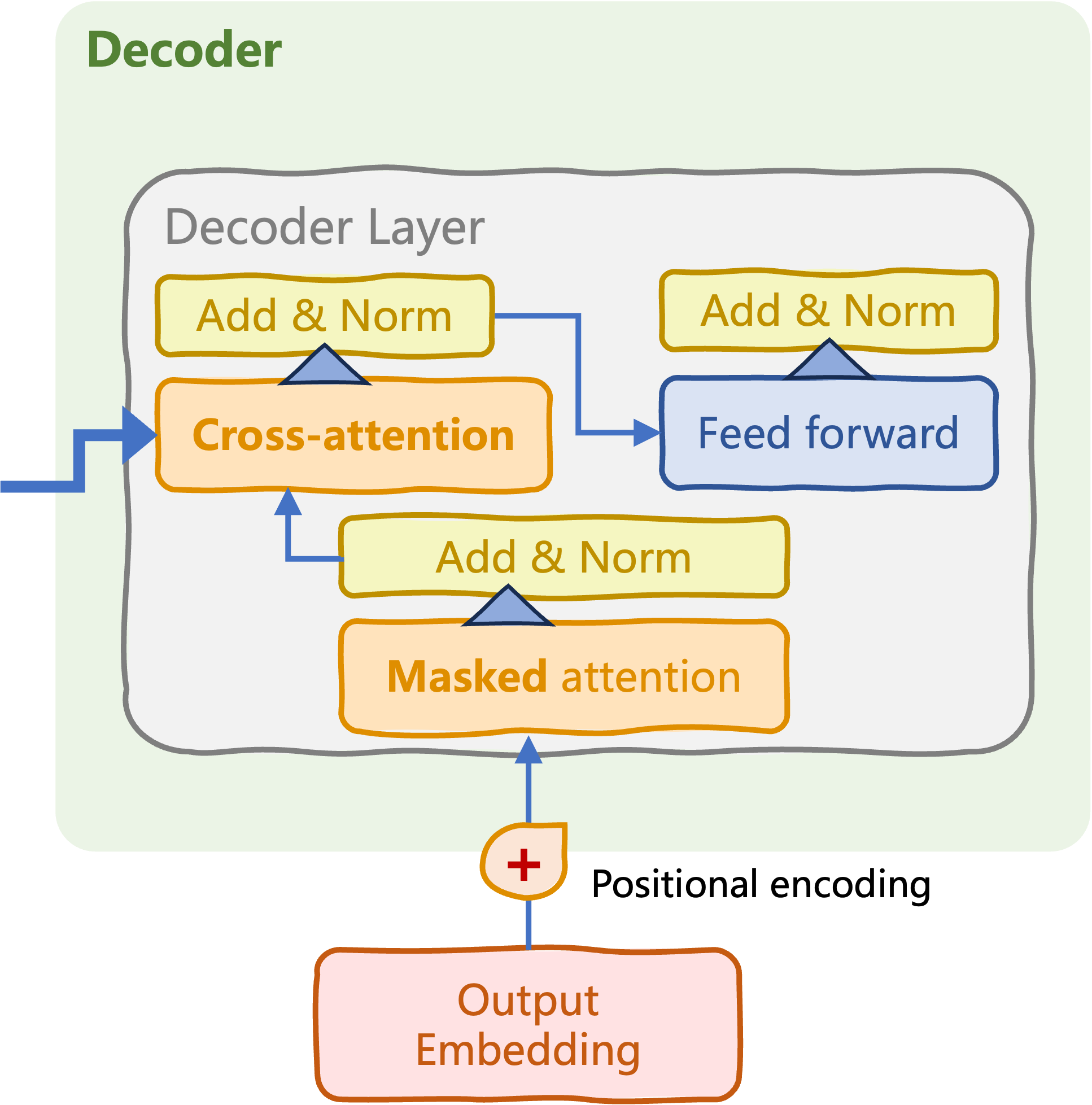
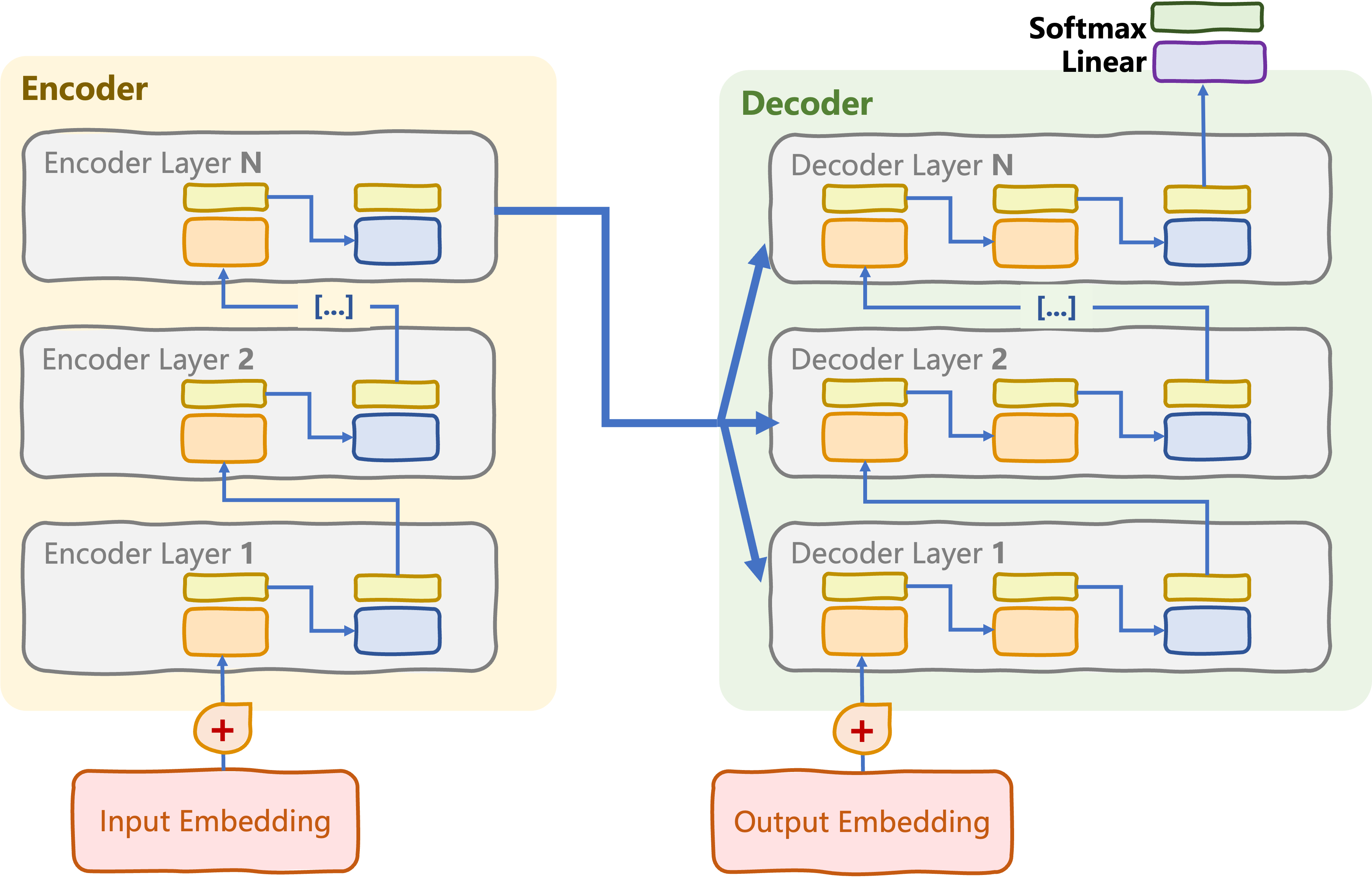
Encoder meets decoder
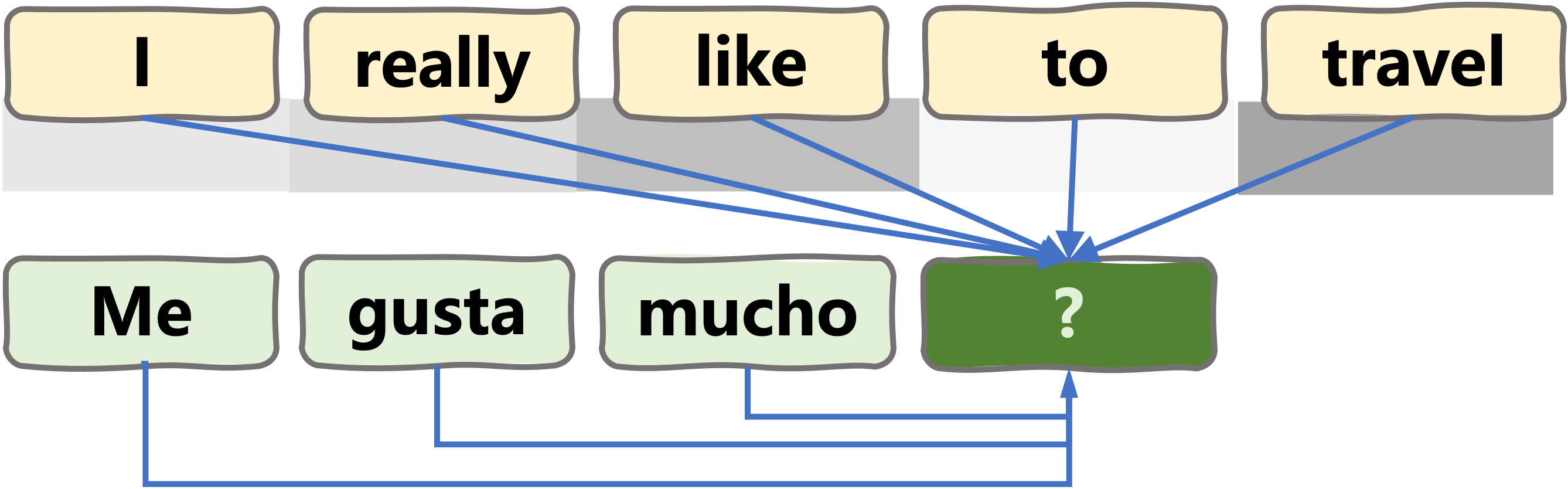
Transformer head
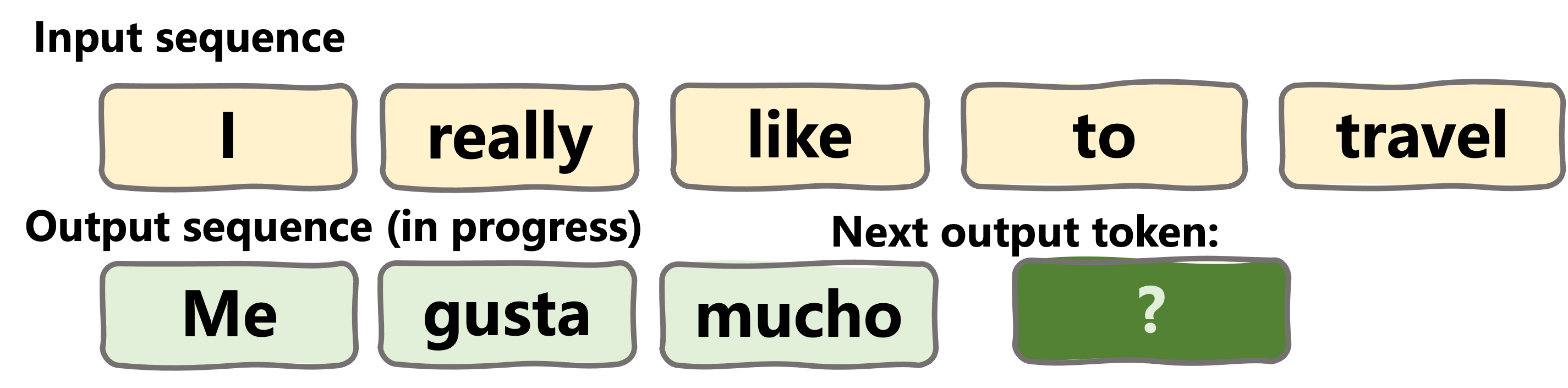
- jugar (to play): 0.03
- viajar (to travel): 0.96
- dormir (to sleep): 0.01
For other tasks, different activations may be required
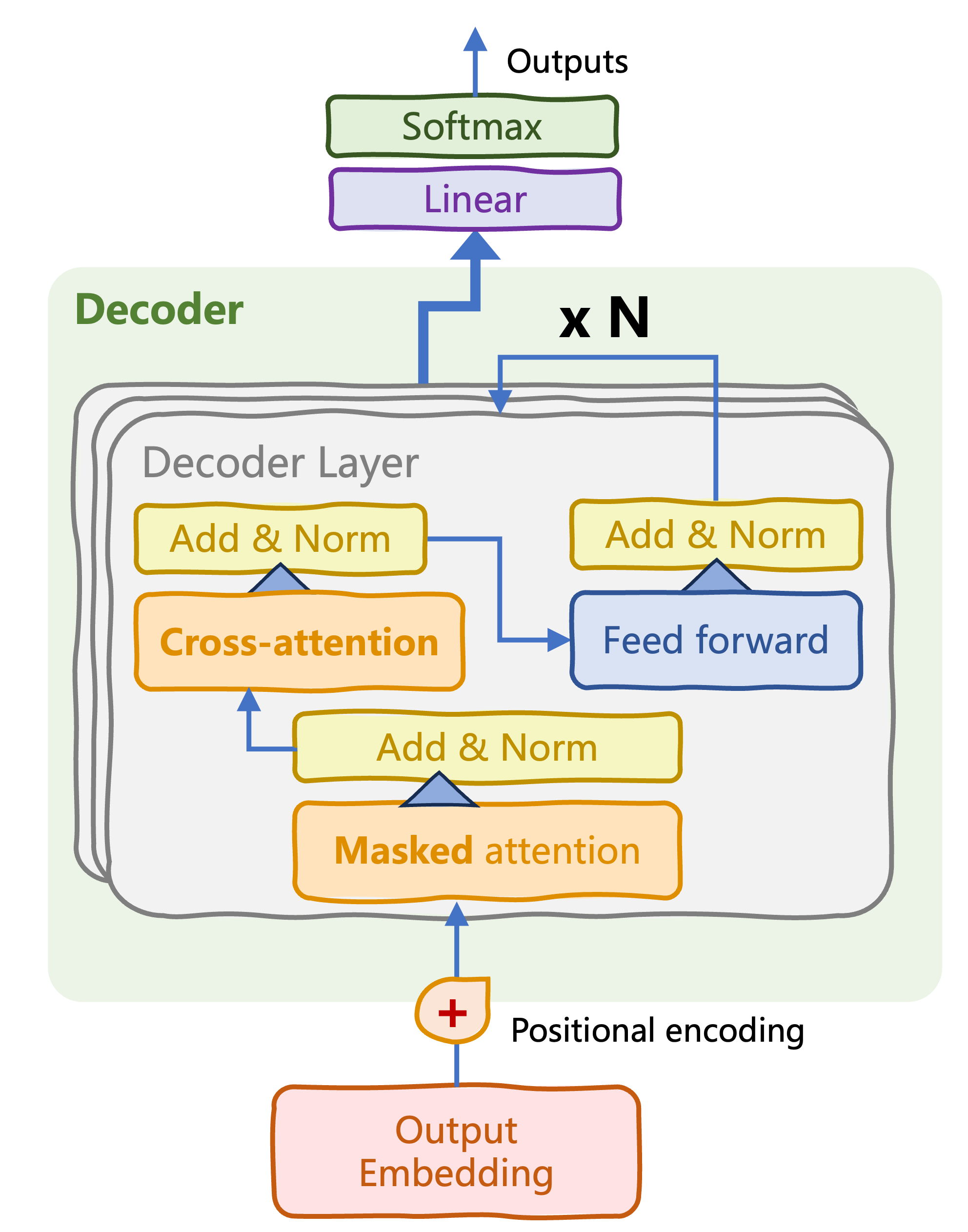
Everything brought together!