Analisi di cluster in Python
Shaumik Daityari
Business Analyst
Normalizzazione: riscalare i dati a una deviazione standard pari a 1
x_new = x / std_dev(x)
from scipy.cluster.vq import whiten
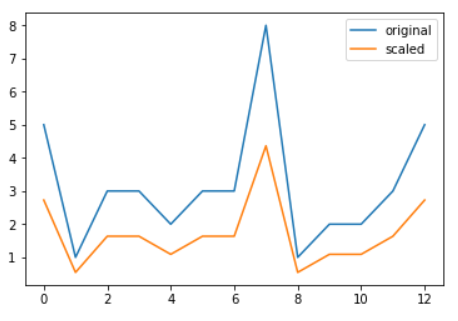
data = [5, 1, 3, 3, 2, 3, 3, 8, 1, 2, 2, 3, 5]
scaled_data = whiten(data) print(scaled_data)
[2.73, 0.55, 1.64, 1.64, 1.09, 1.64, 1.64, 4.36, 0.55, 1.09, 1.09, 1.64, 2.73]
# Import plotting library from matplotlib import pyplot as plt # Initialize original, scaled data plt.plot(data, label="original") plt.plot(scaled_data, label="scaled")
# Show legend and display plot plt.legend() plt.show()