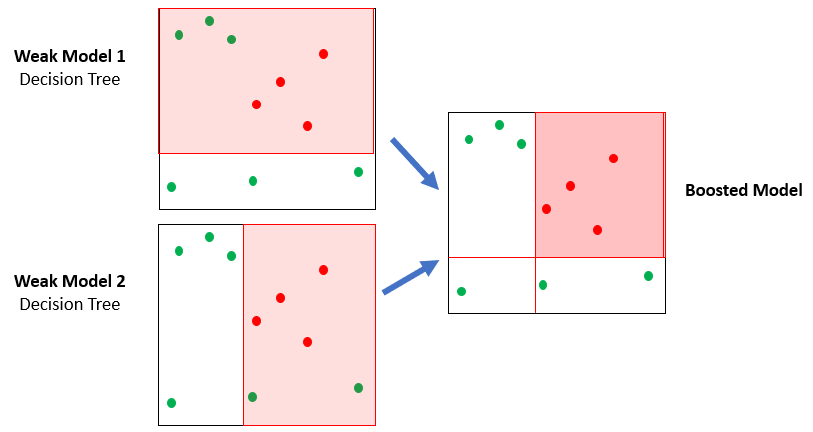
Alberi potenziati (XGBoost)
Credit Risk Modeling in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Alberi decisionali
- Crea previsioni simili alla regressione logistica
- Non è strutturato come una regressione
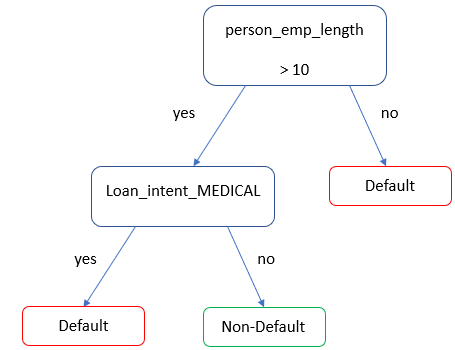
Alberi decisionali per loan status
- Albero decisionale semplice per prevedere la probabilità di default di
loan_status
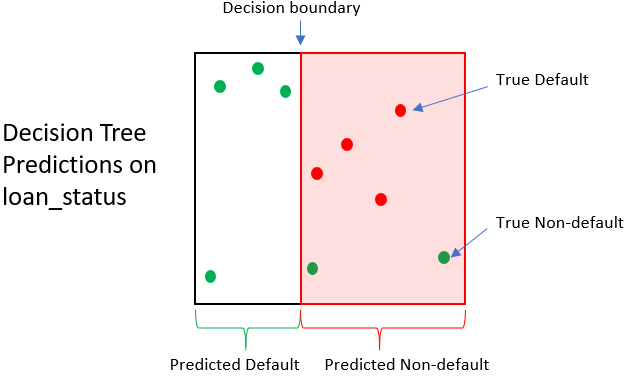
Impatto dell’albero decisionale
| Prestito | Loan status reale | Loan status pred. | Valore rimborso | Valore di vendita | Guadagno/Perdita |
|---|---|---|---|---|---|
| 1 | 0 | 1 | $1,500 | $250 | -$1,250 |
| 2 | 0 | 1 | $1,200 | $250 | -$950 |
Una foresta di alberi
- XGBoost usa molti alberi semplici (ensemble)
- Ogni albero è leggermente meglio del lancio di una moneta