Squilibrio di classi nei dati sui prestiti
Credit Risk Modeling in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Funzione di perdita del modello
- I Gradient Boosted Trees in
xgboostusano la log-loss come funzione di perdita- L’obiettivo è minimizzarla
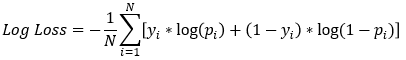
| Stato reale del prestito | Probabilità prevista | Log-loss |
|---|---|---|
| 1 | 0.1 | 2.3 |
| 0 | 0.9 | 2.3 |
- Una insolvenza prevista male ha un impatto finanziario peggiore
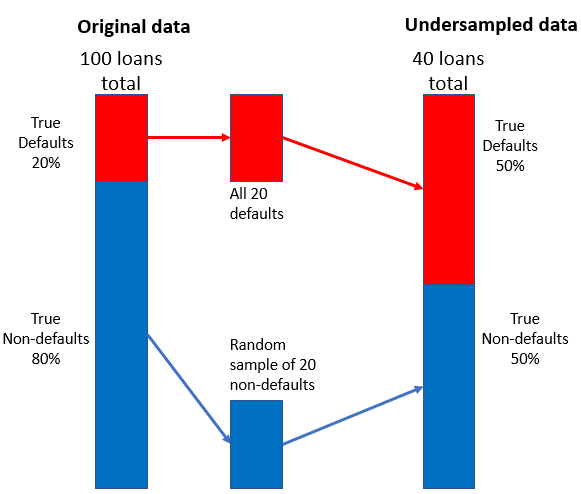
Strategia di undersampling
- Combina un piccolo campione casuale di non insolvenze con le insolvenze