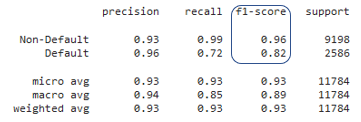
Selezione colonne per il rischio di credito
Credit Risk Modeling in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Interpretare l'importanza delle colonne
# Importanza colonne da importance_type = 'weight'
{'person_home_ownership_RENT': 1, 'person_home_ownership_OWN': 2}
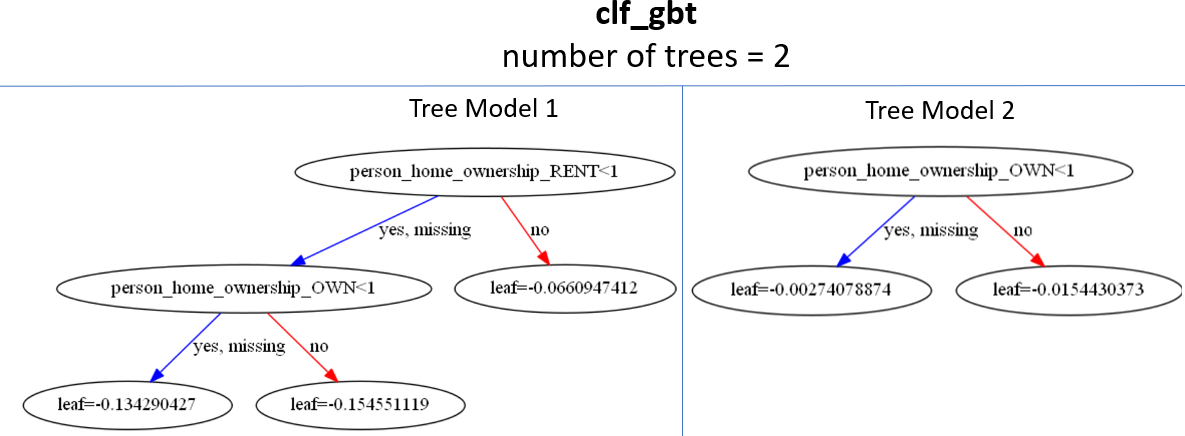
Grafico dell'importanza delle colonne
- Usa la funzione
plot_importance()
xgb.plot_importance(clf_gbt, importance_type = 'weight')
{'person_income': 315, 'loan_int_rate': 195, 'loan_percent_income': 146}
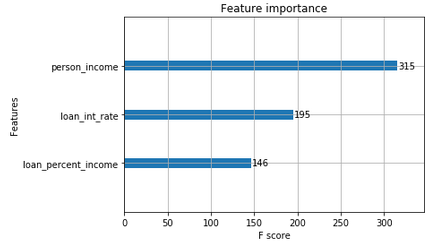
F1 score per i modelli
- Valutare accuracy e recall per gruppi di colonne richiede tempo
- L'F1 è un'unica metrica che combina accuracy e recall
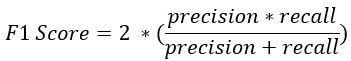
- È mostrato nel
classification_report()