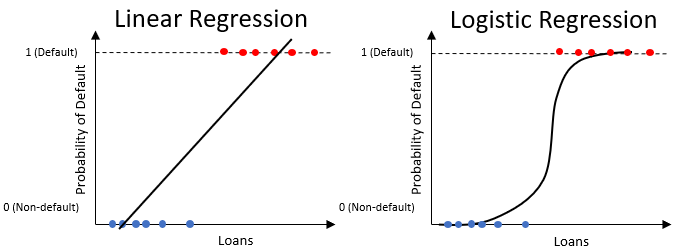
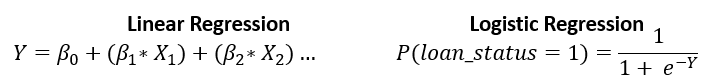Regressione logistica per la probabilità di default
Credit Risk Modeling in Python

Michael Crabtree
Data Scientist, Ford Motor Company
Prevedere probabilità
- Probabilità di default come output del machine learning
- Si impara dai dati nelle colonne (feature)
- Modelli di classificazione (default, non default)
- Due modelli più comuni:
- Regressione logistica
- Albero decisionale
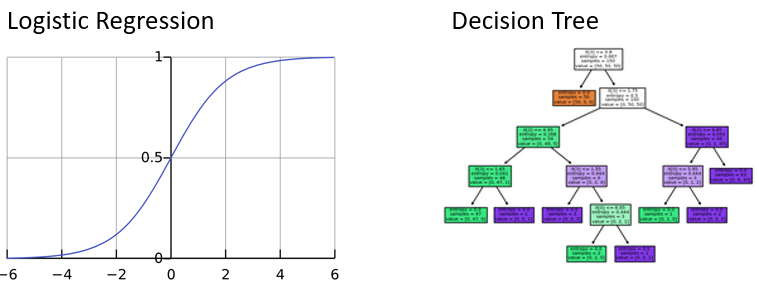
Regressione logistica
- Simile alla regressione lineare, ma produce solo valori tra
0e1