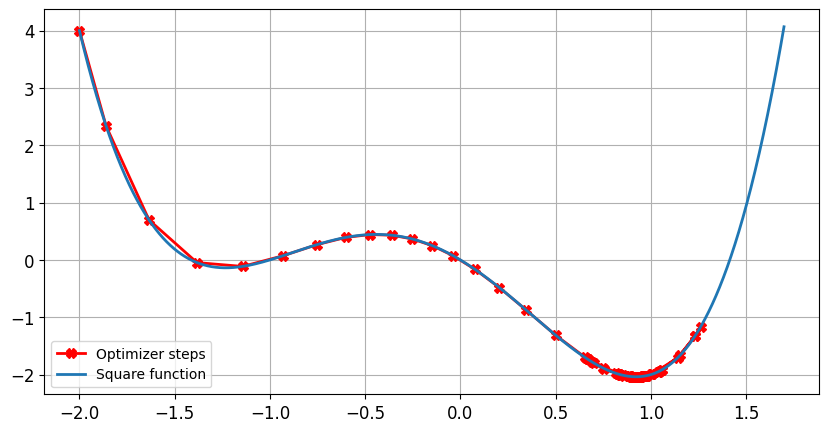
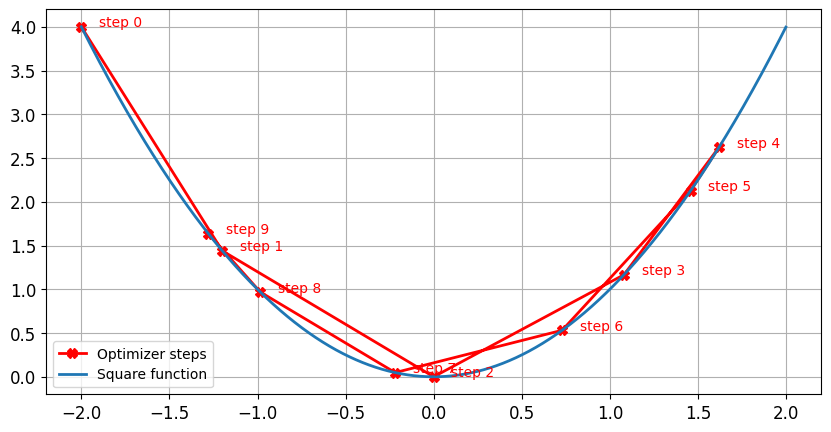
Learning rate and momentum
Introduzione al Deep Learning con PyTorch

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Impact of the learning rate: optimal learning rate

- Step size decreases near zero as the gradient gets smaller
Impact of the learning rate: small learning rate

Impact of the learning rate: high learning rate
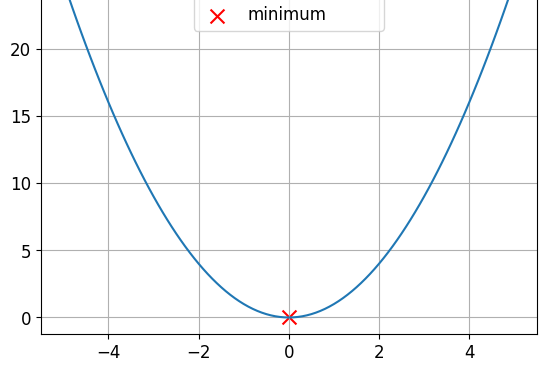
Convex and non-convex functions
This is a convex function.
This is a non-convex function.
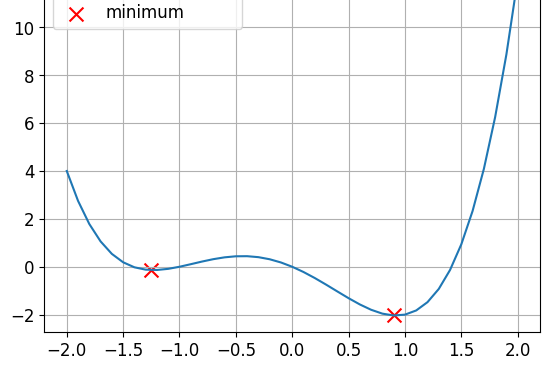
- Loss functions are non-convex
Without momentum
lr = 0.01momentum = 0, after 100 steps minimum found forx = -1.23andy = -0.14
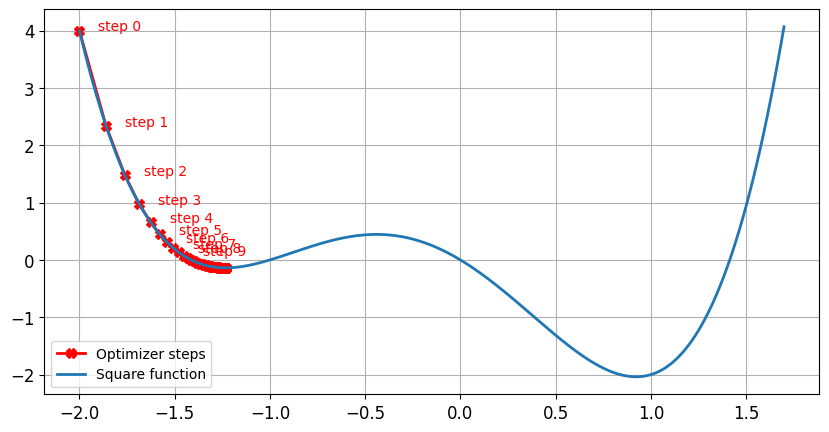
With momentum
lr = 0.01momentum = 0.9, after 100 steps minimum found forx = 0.92andy = -2.04