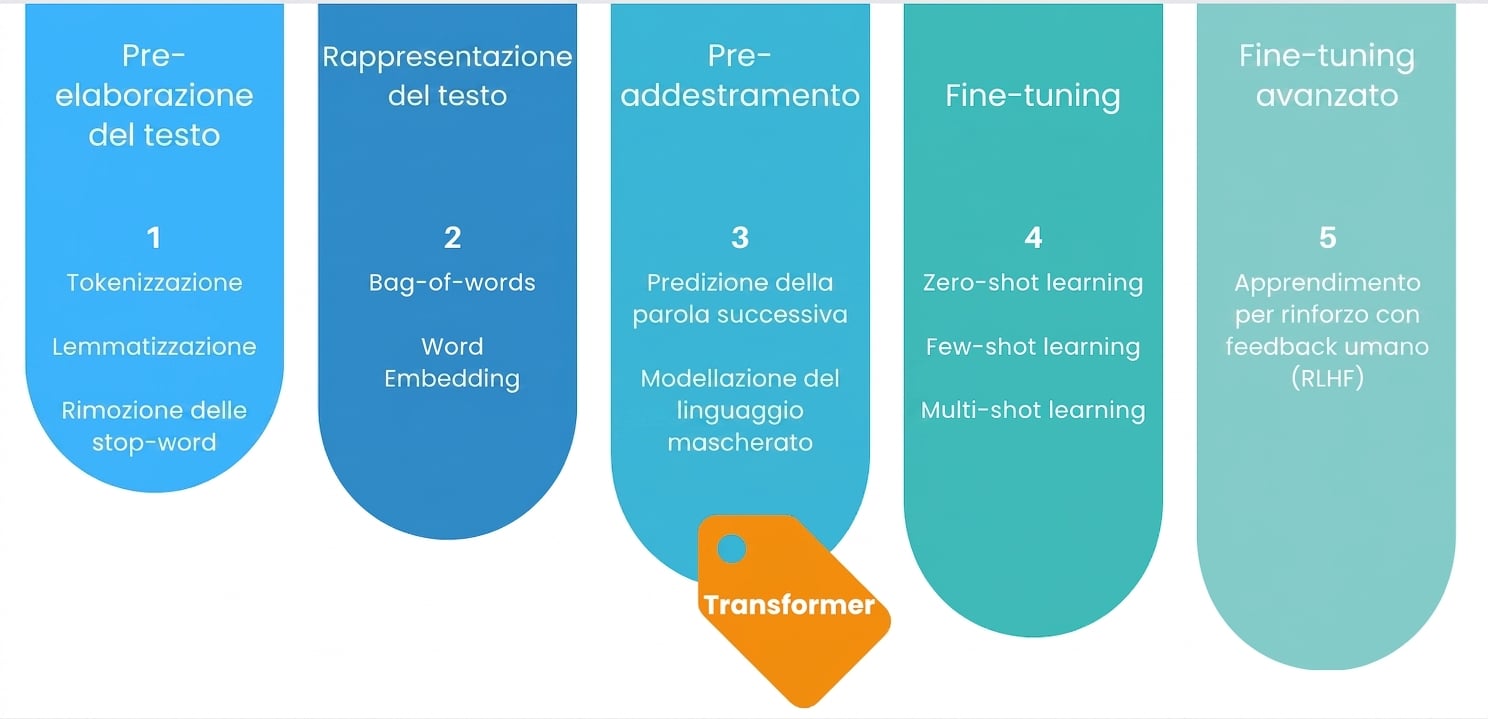
Messa a punto avanzata
Concetti sui Large Language Models (LLM)

Vidhi Chugh
AI strategist and ethicist
Dove siamo?
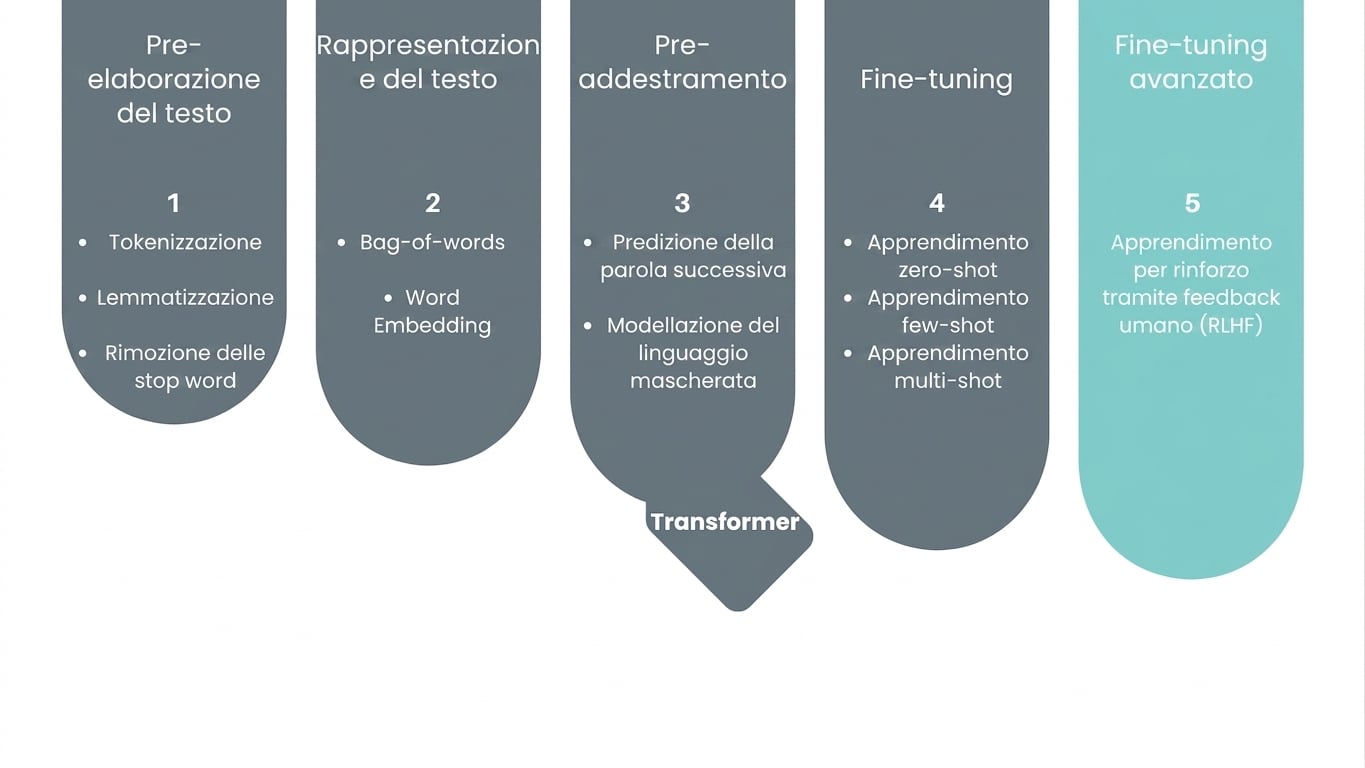
Reinforcement Learning con feedback umano

Pre-training

1 Freepik
Fine-tuning

Ma perché RLHF?

RLHF in breve

Entra l’esperto umano

Tempo di feedback
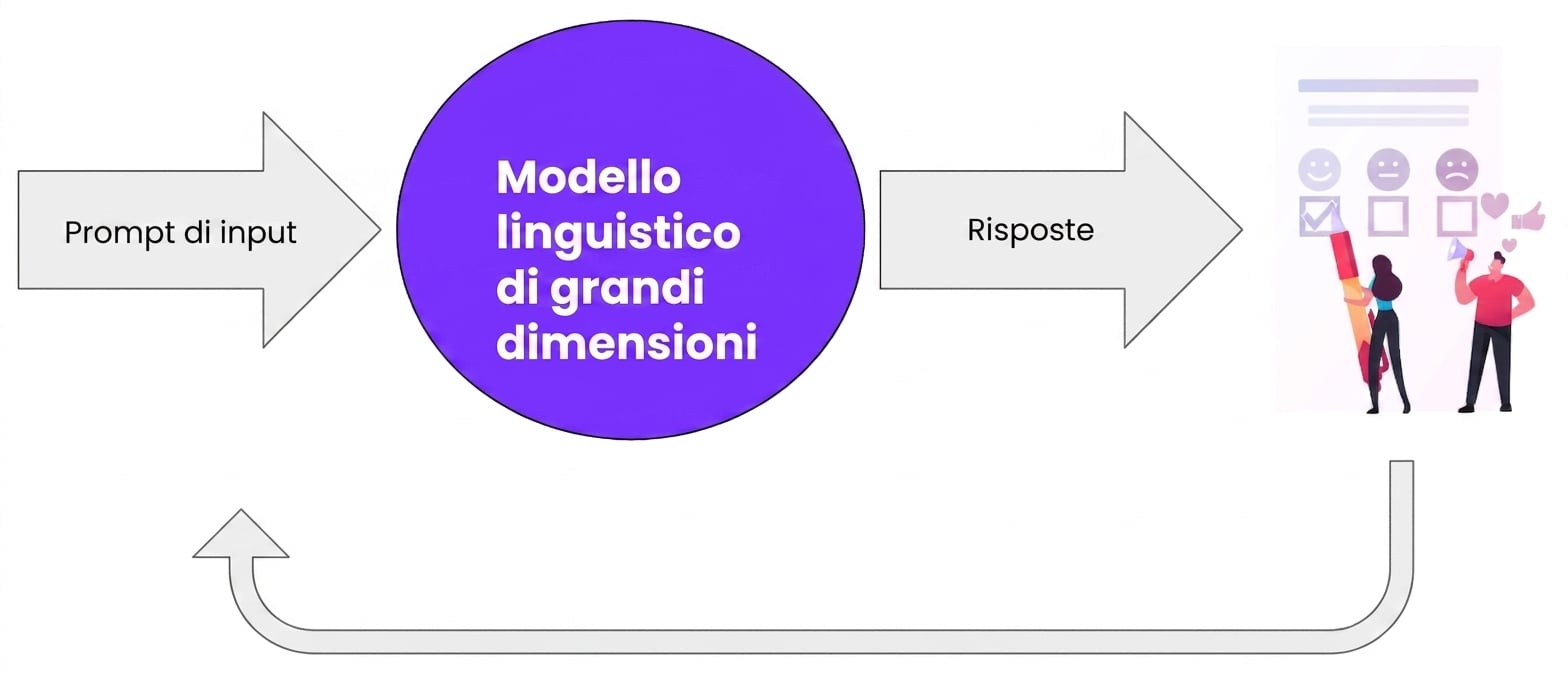
Completare l’LLM