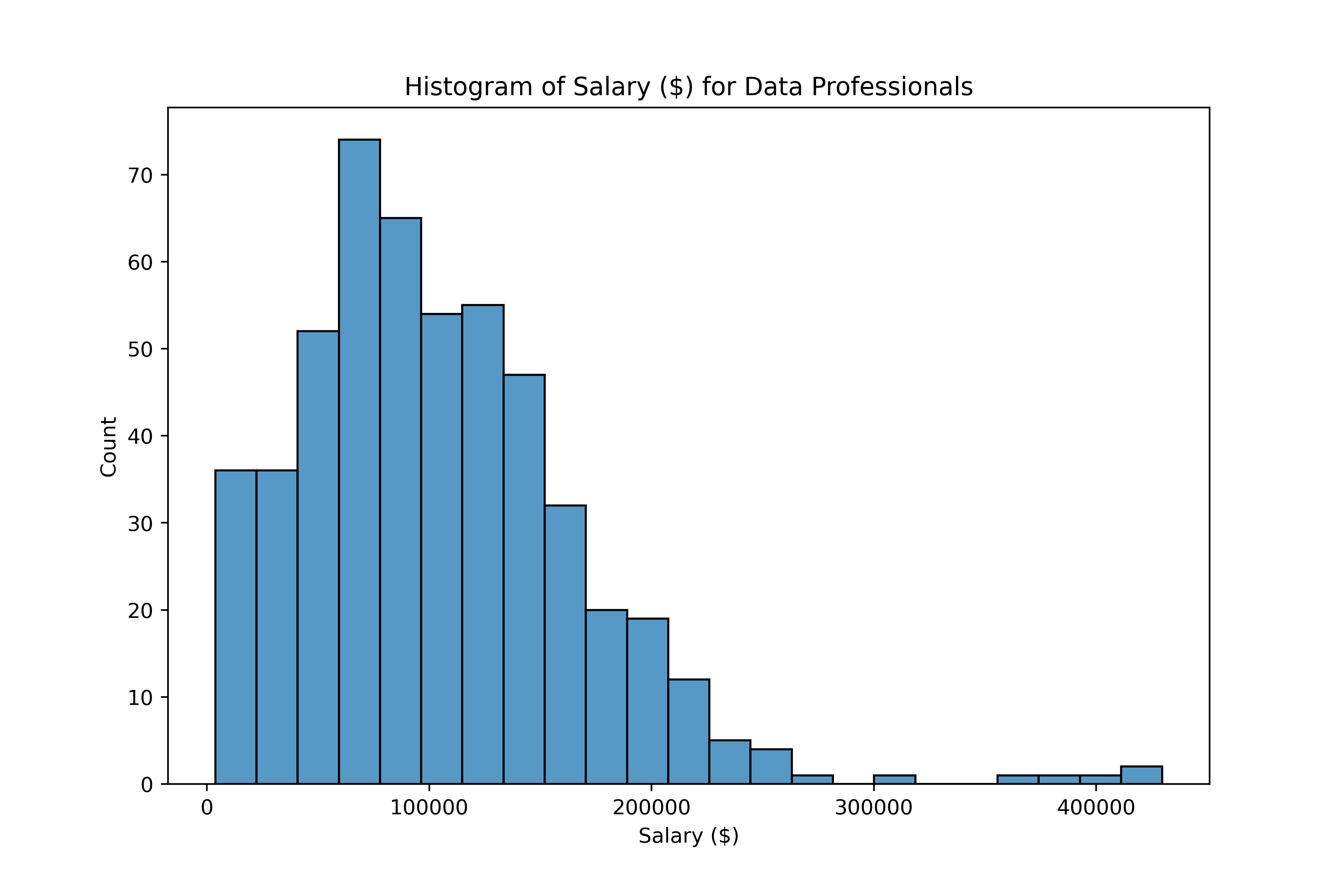
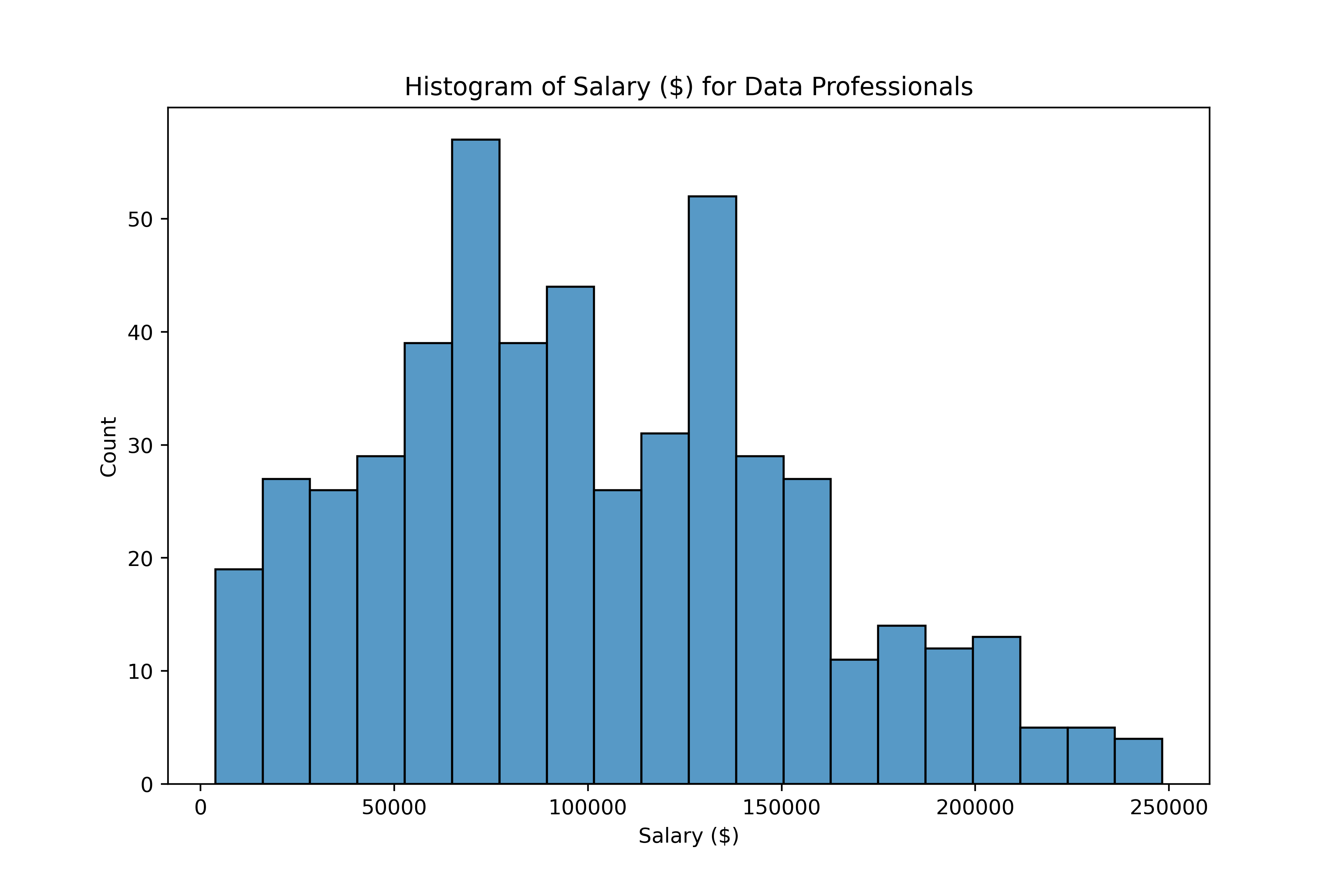
Gestire gli outlier
Analisi esplorativa dei dati in Python

George Boorman
Curriculum Manager, DataCamp
Cos'è un outlier?

1 Crediti immagine: https://unsplash.com/@ralphkayden
IQR nei box plot
sns.boxplot(data=salaries,
y="Salary_USD")
plt.show()
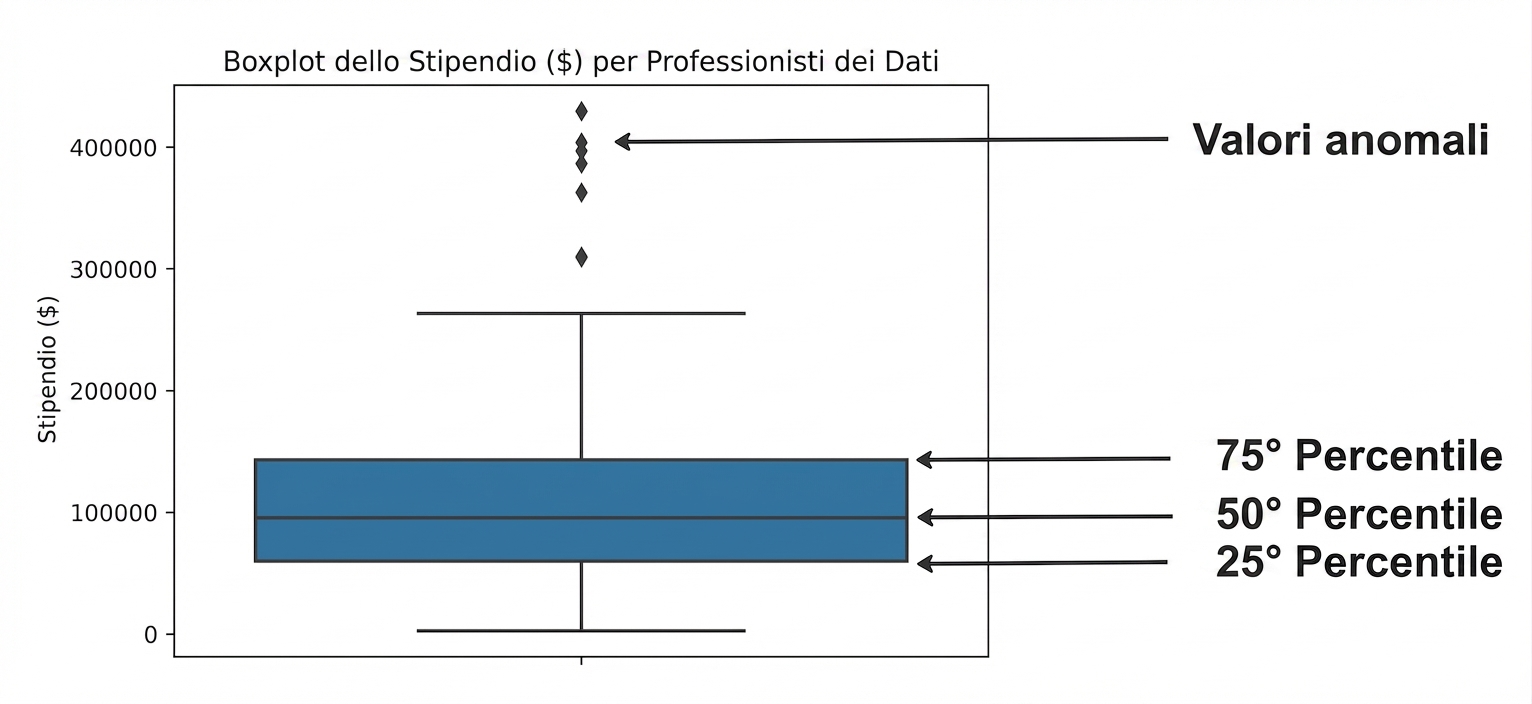
Distribuzione degli stipendi