Gestire i dati mancanti
Analisi esplorativa dei dati in Python

George Boorman
Curriculum Manager, DataCamp
Perché i dati mancanti sono un problema?
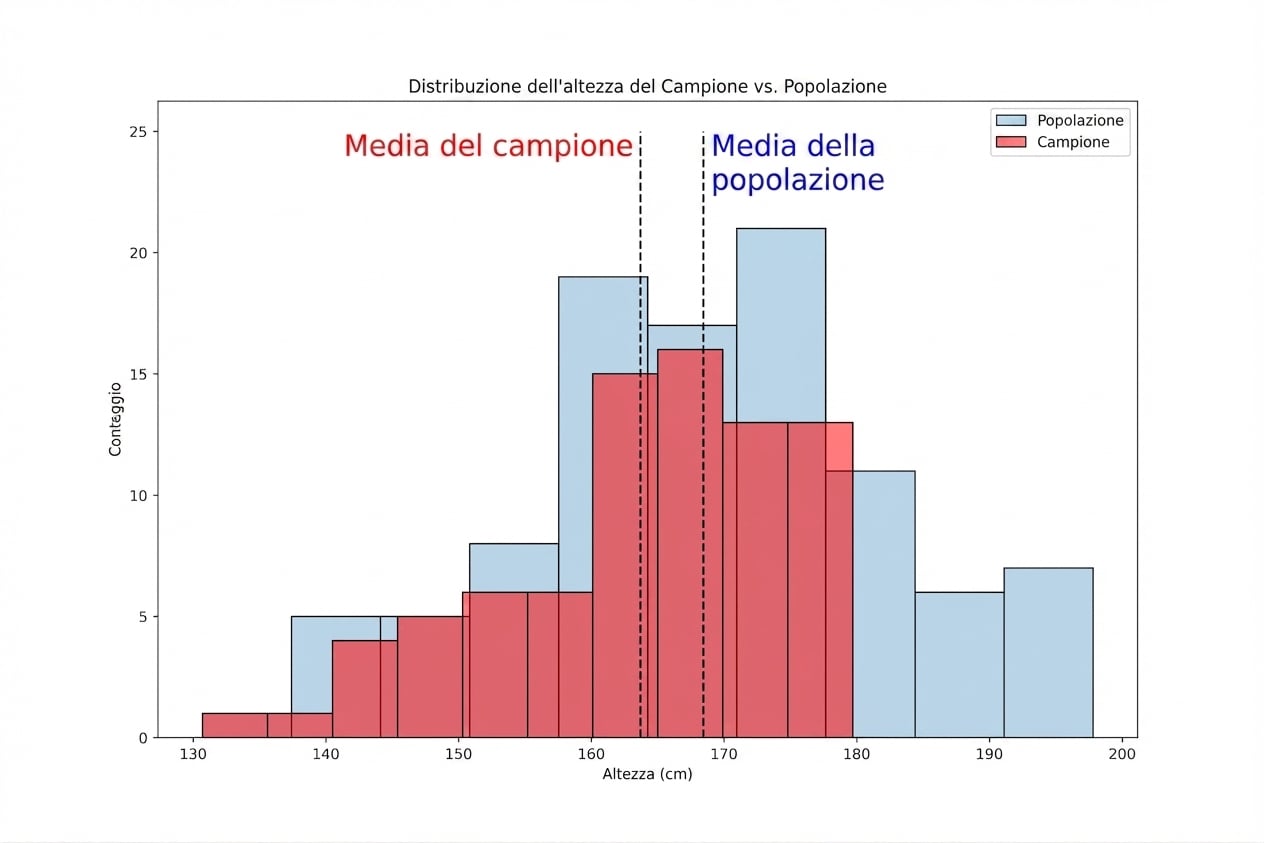
Stipendio per livello di esperienza
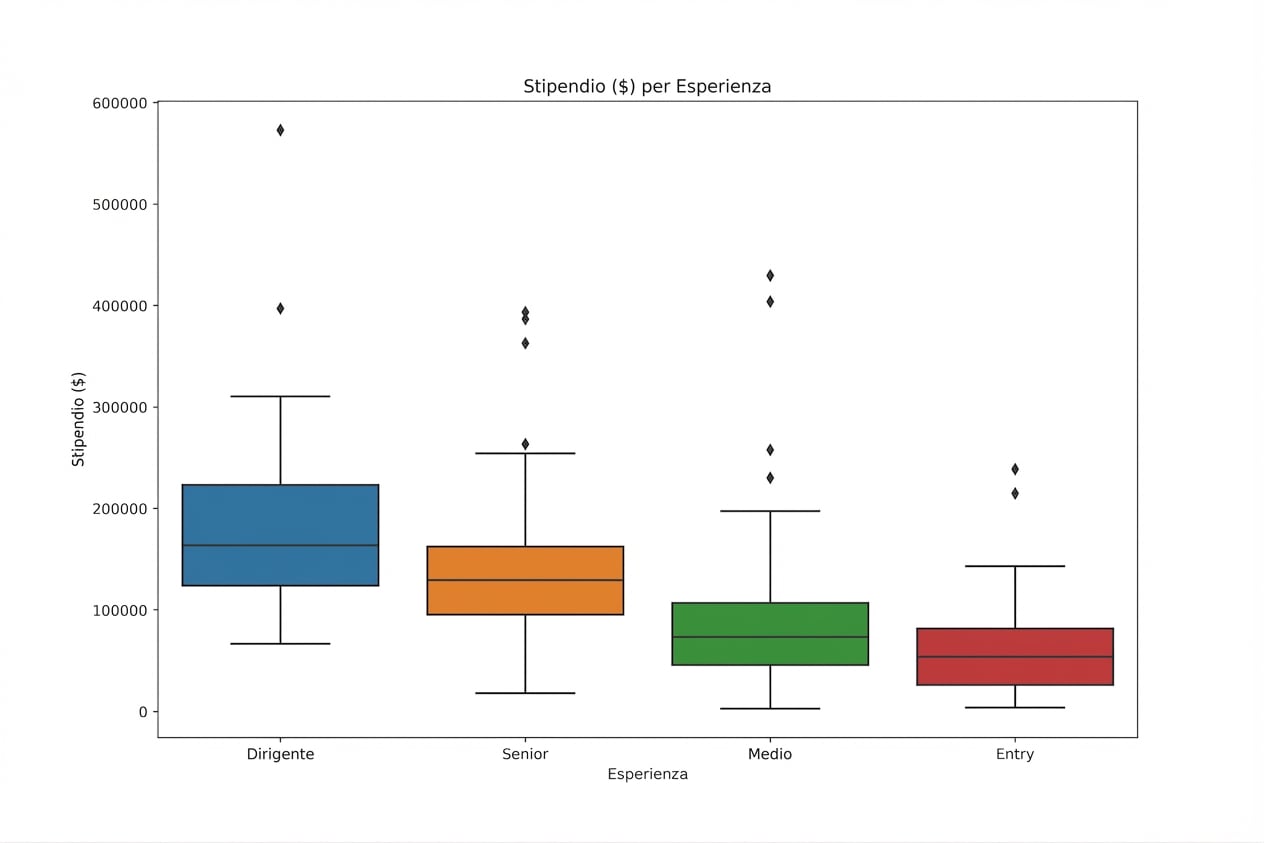
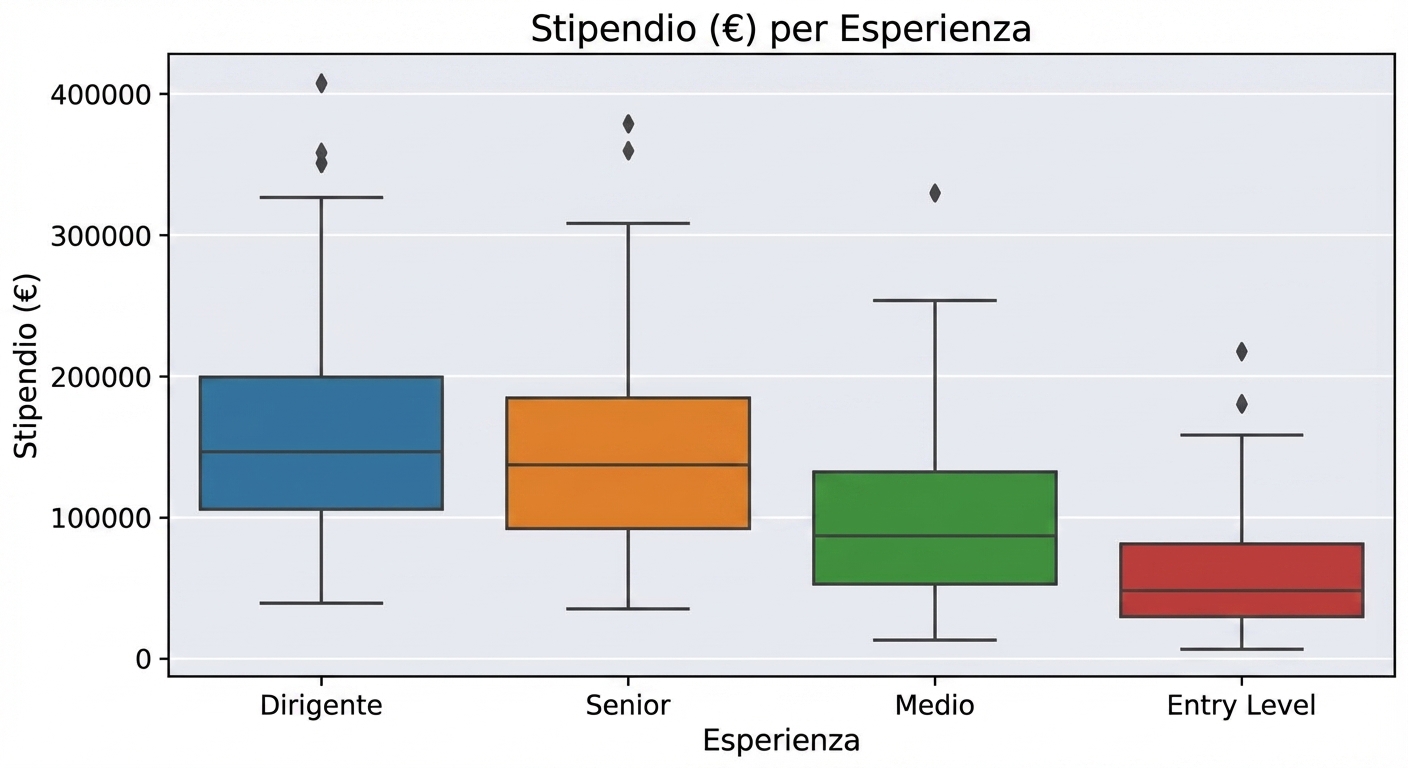
Analisi esplorativa dei dati in Python
George Boorman
Curriculum Manager, DataCamp

