Generare coppie
Pulizia dei dati in Python

Adel Nehme
VP of AI Curriculum, DataCamp
Motivazione
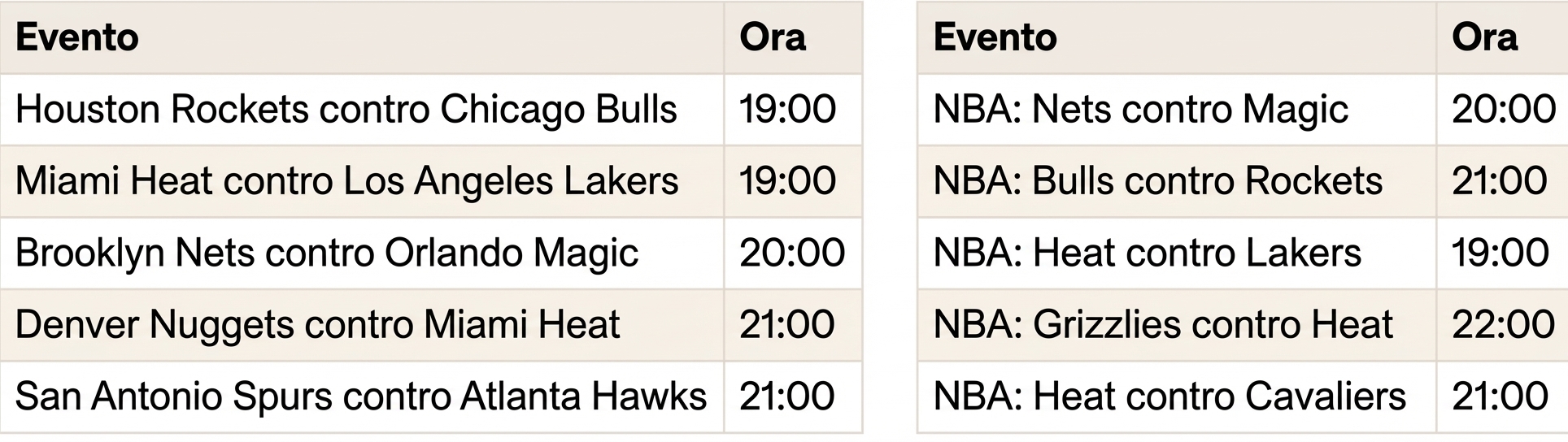
Quando le join non bastano
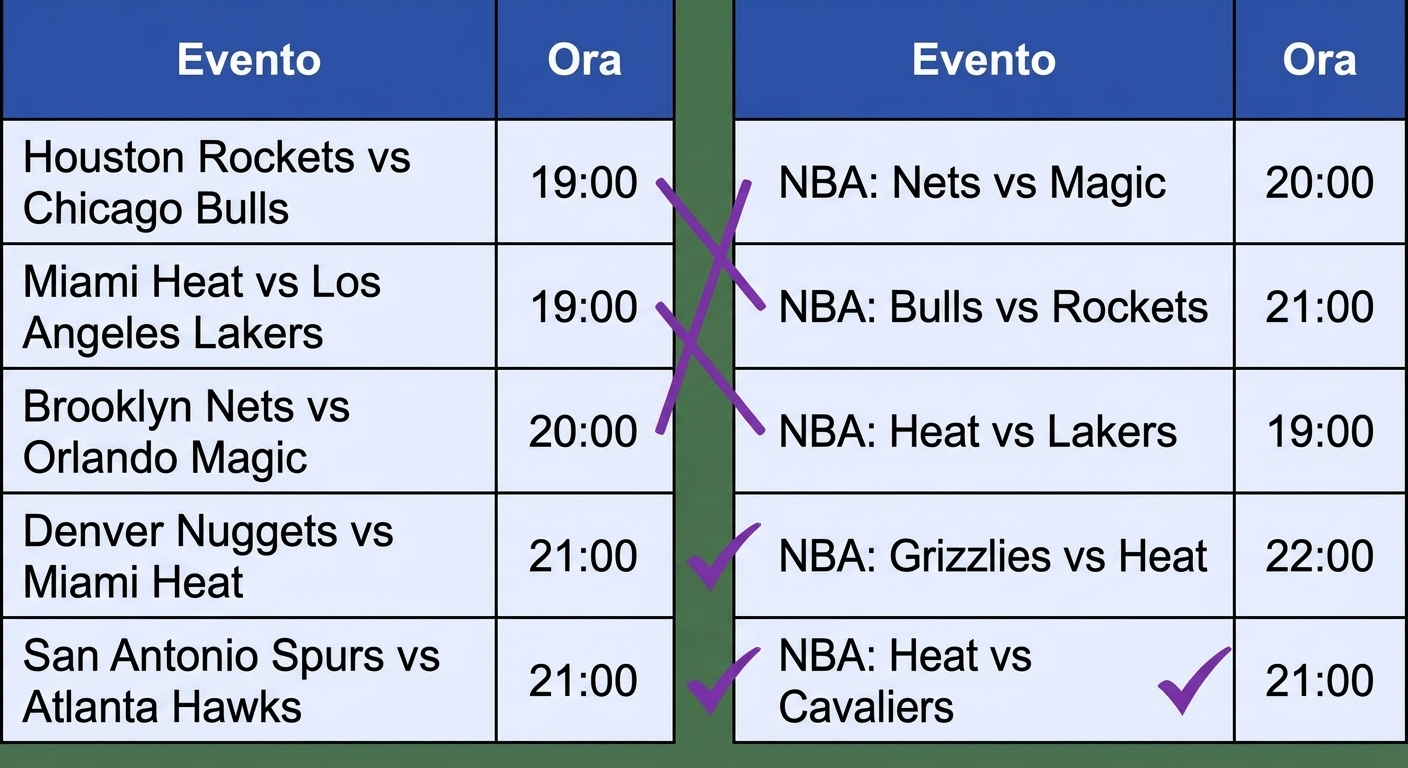
Record linkage
Il pacchetto recordlinkage
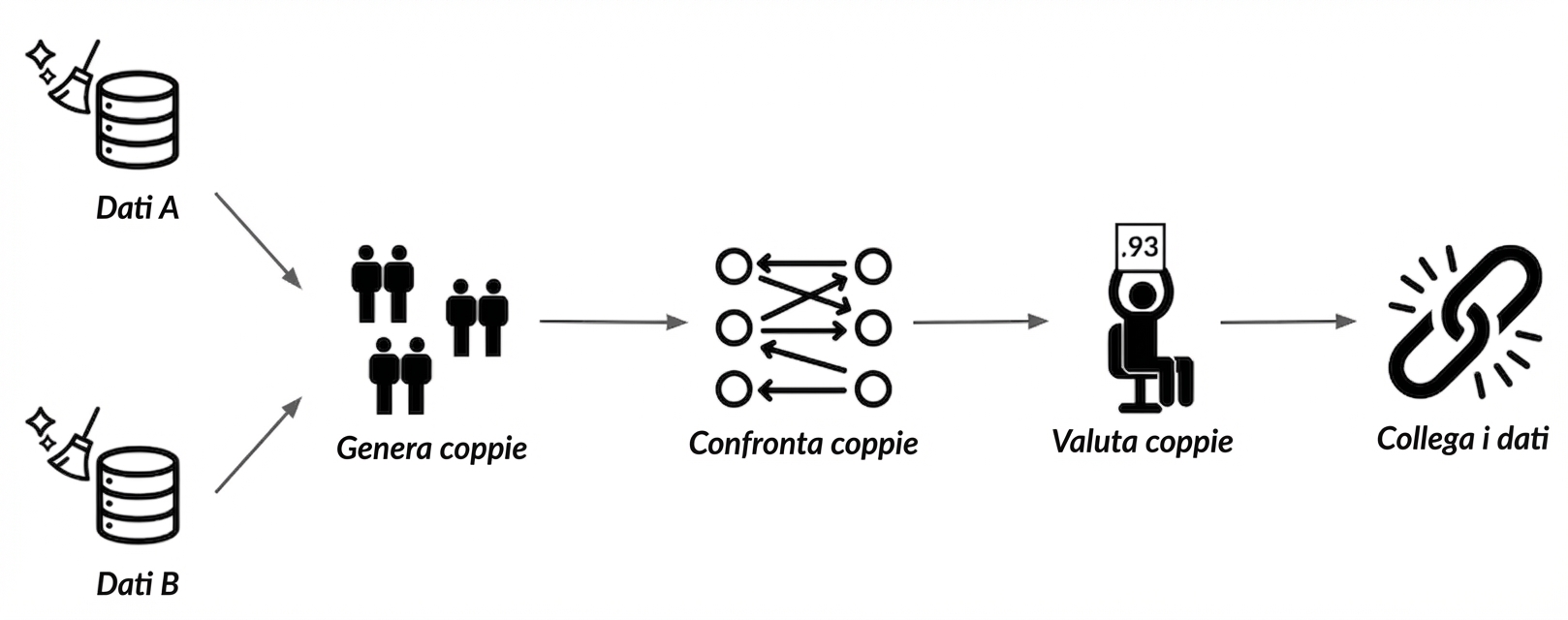
Generare coppie
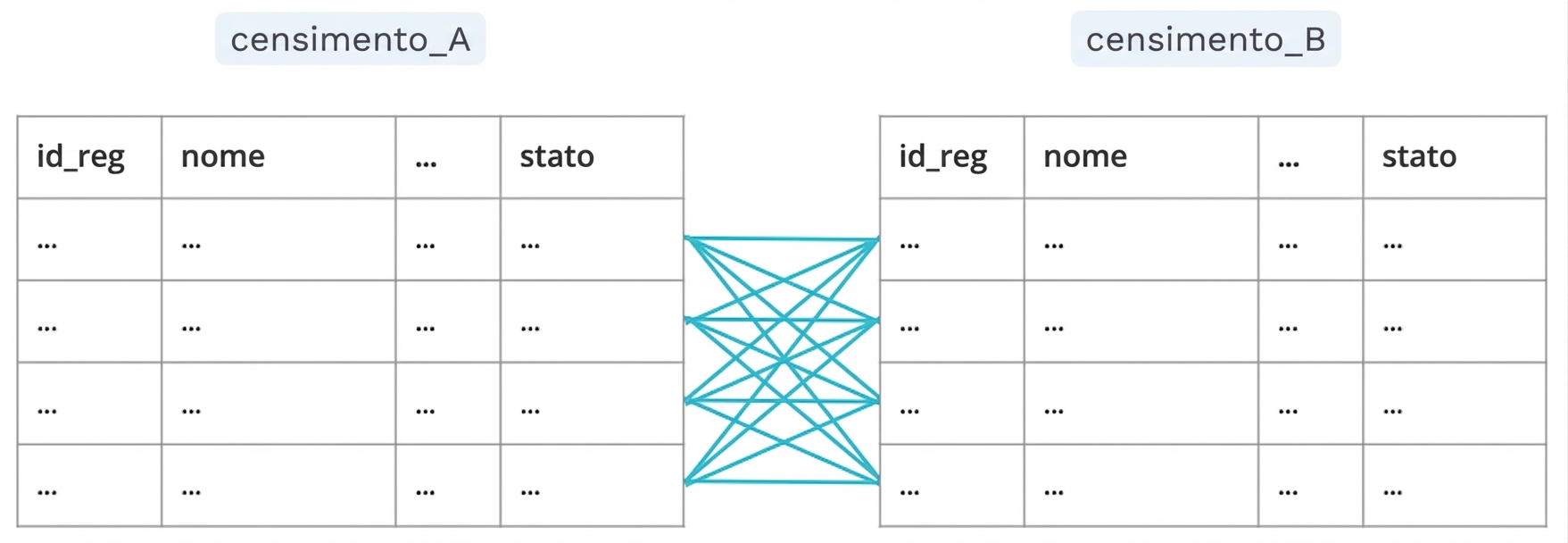
Generare coppie
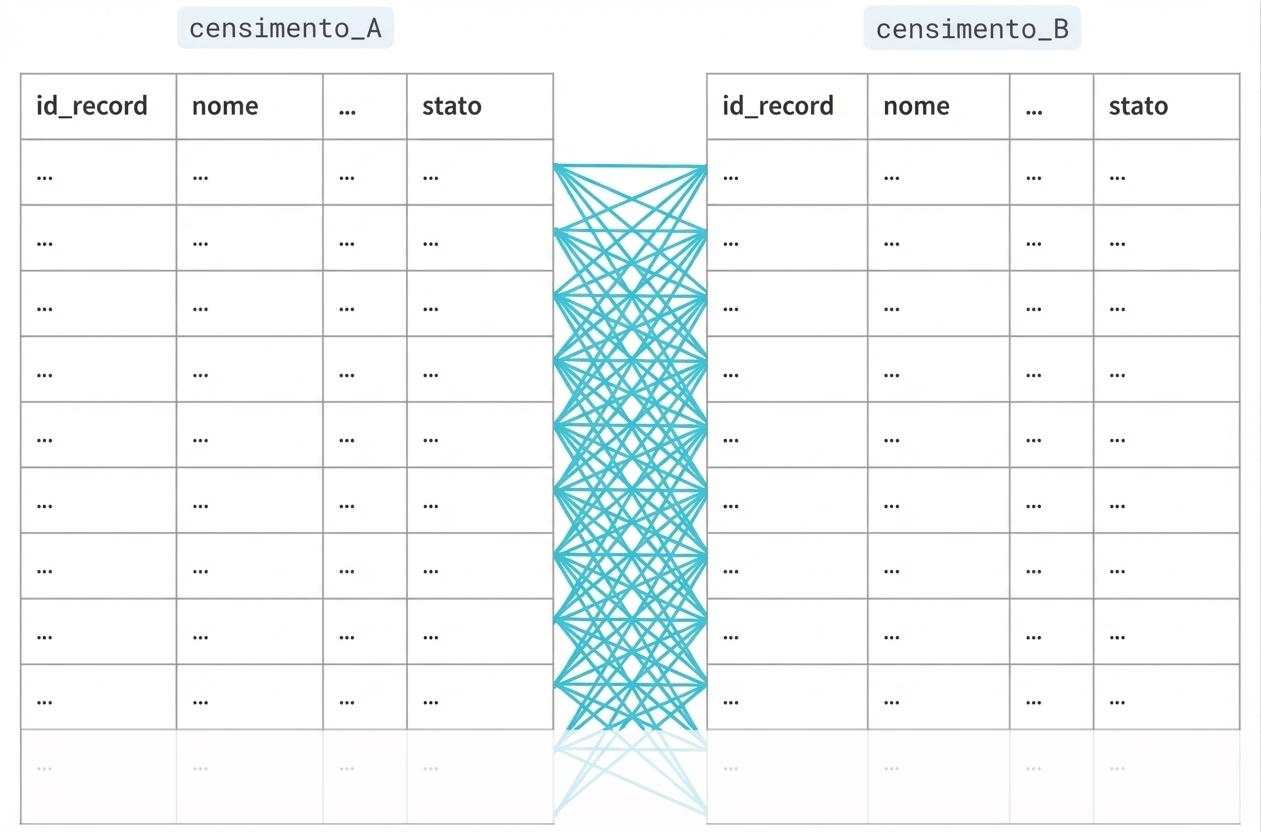
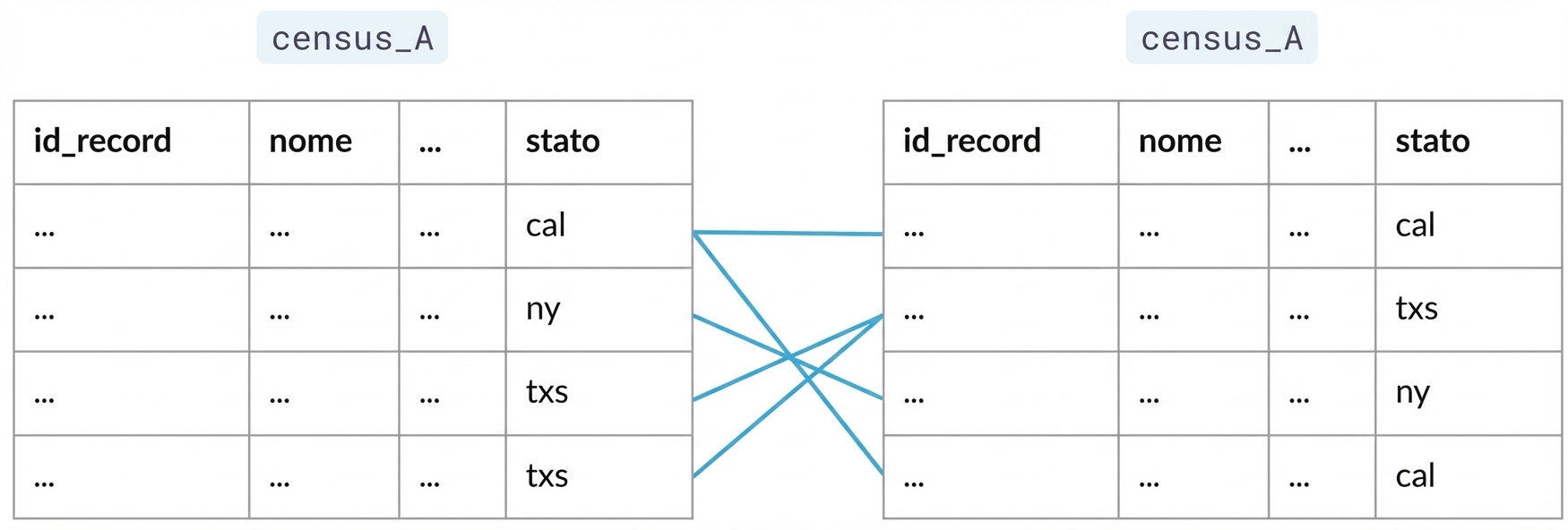
Blocking
Pulizia dei dati in Python
Adel Nehme
VP of AI Curriculum, DataCamp
Il pacchetto recordlinkage

