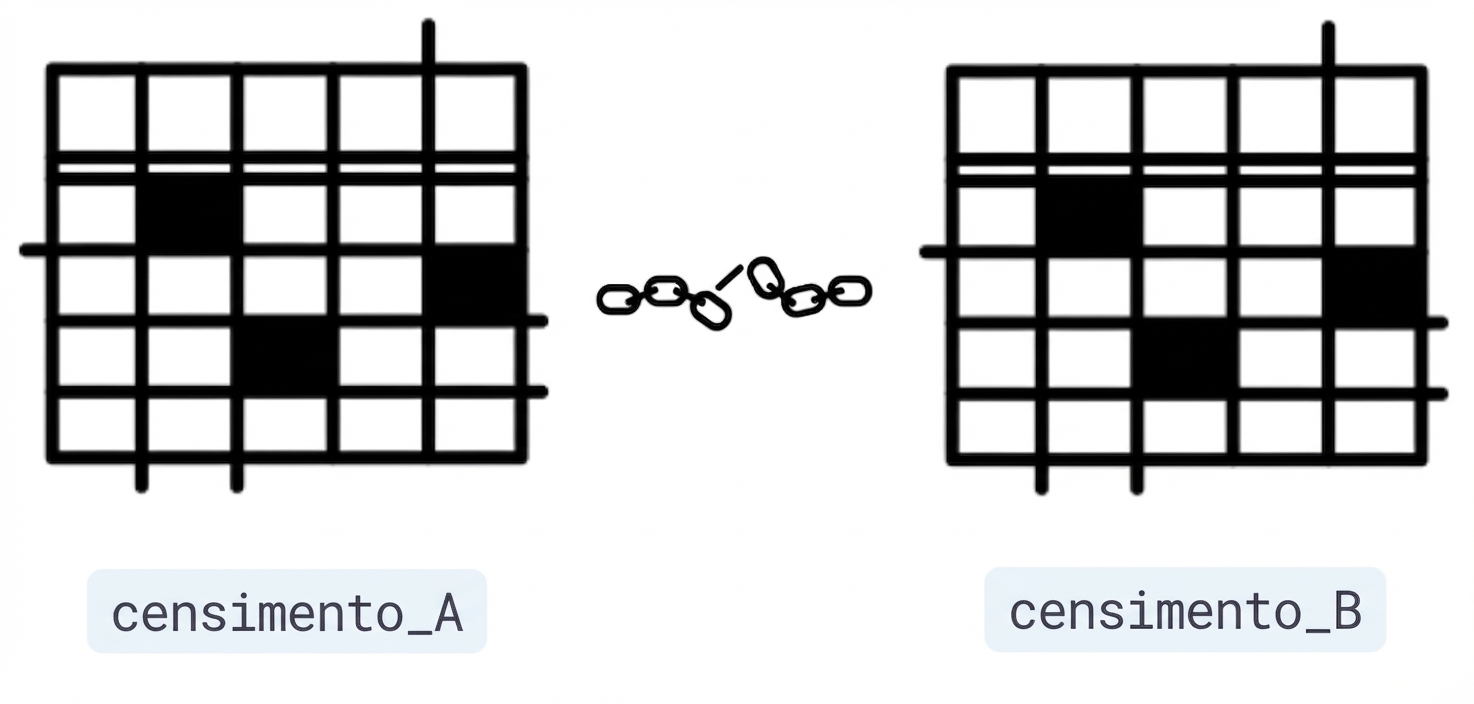
Collegare DataFrame
Pulizia dei dati in Python

Adel Nehme
VP of AI Curriculum, DataCamp
Record linkage
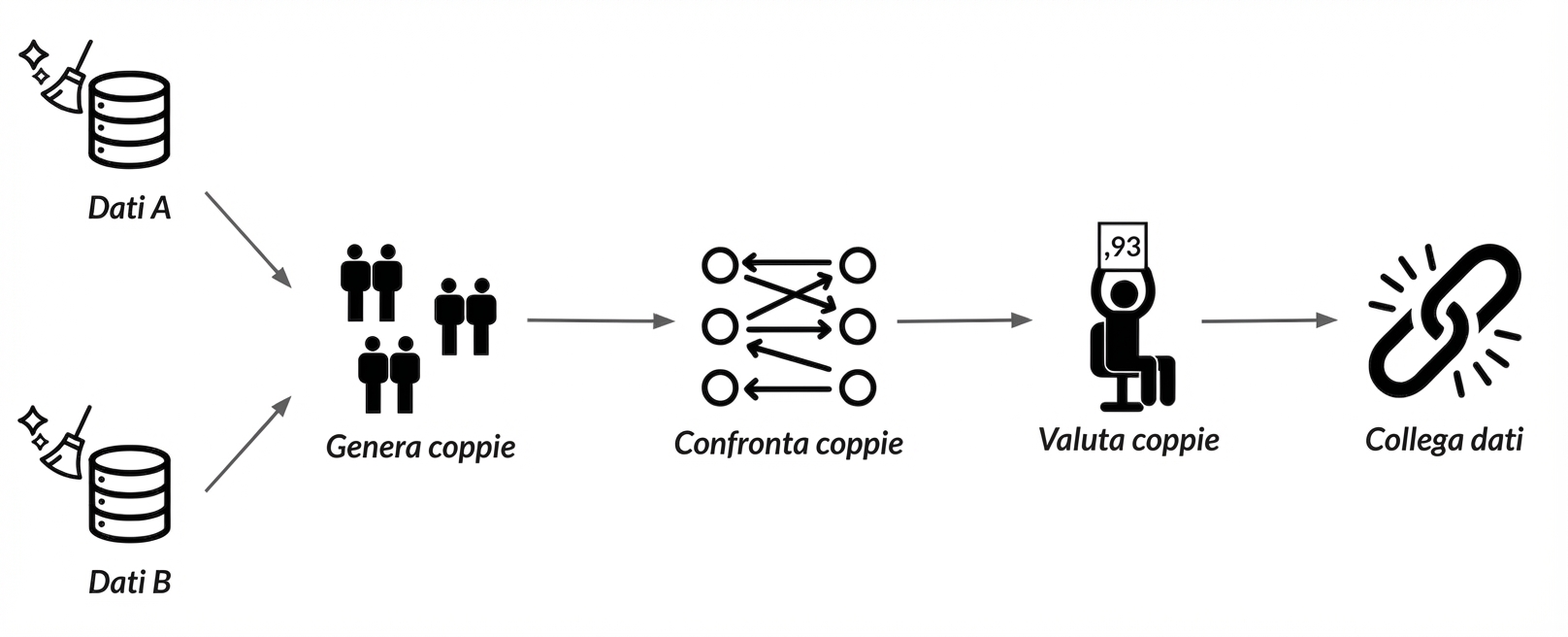
Record linkage
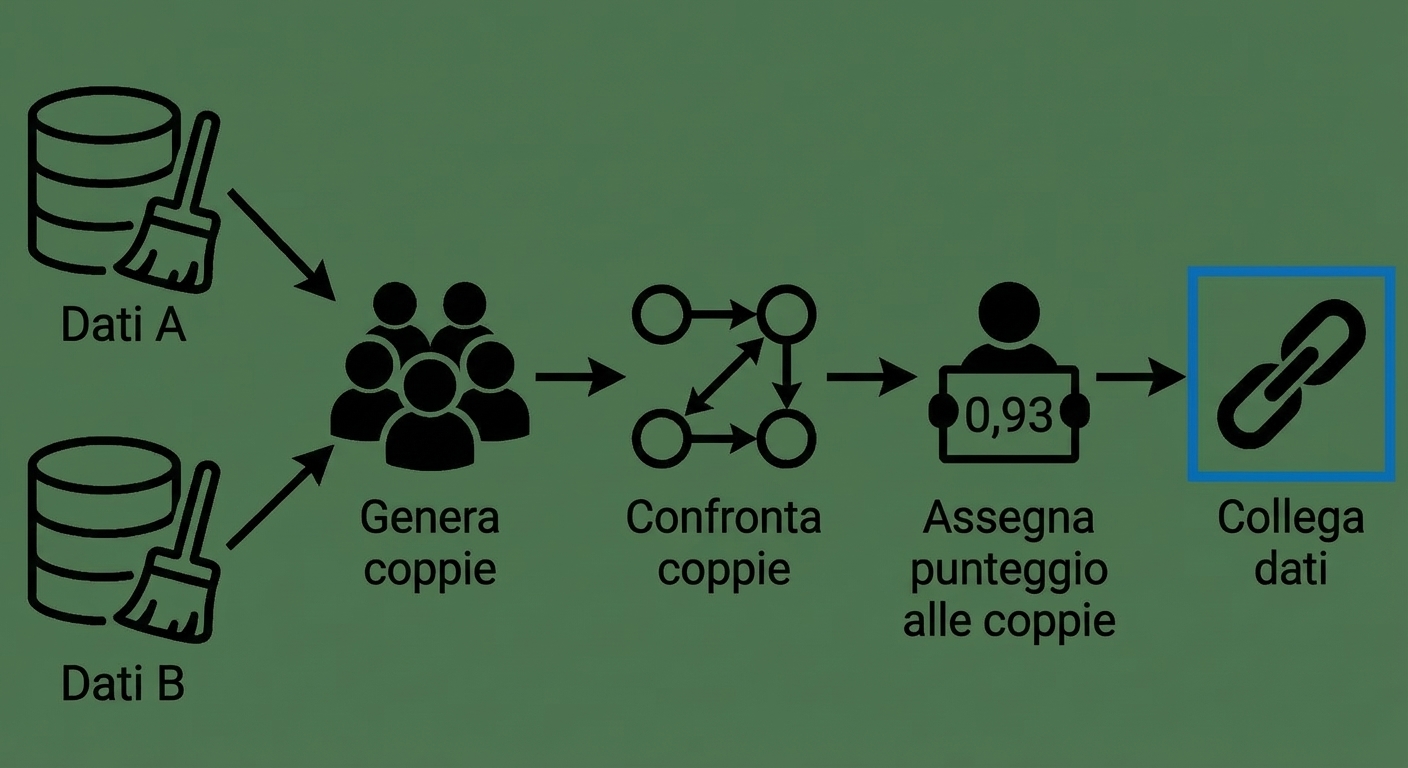
Cosa stiamo facendo ora
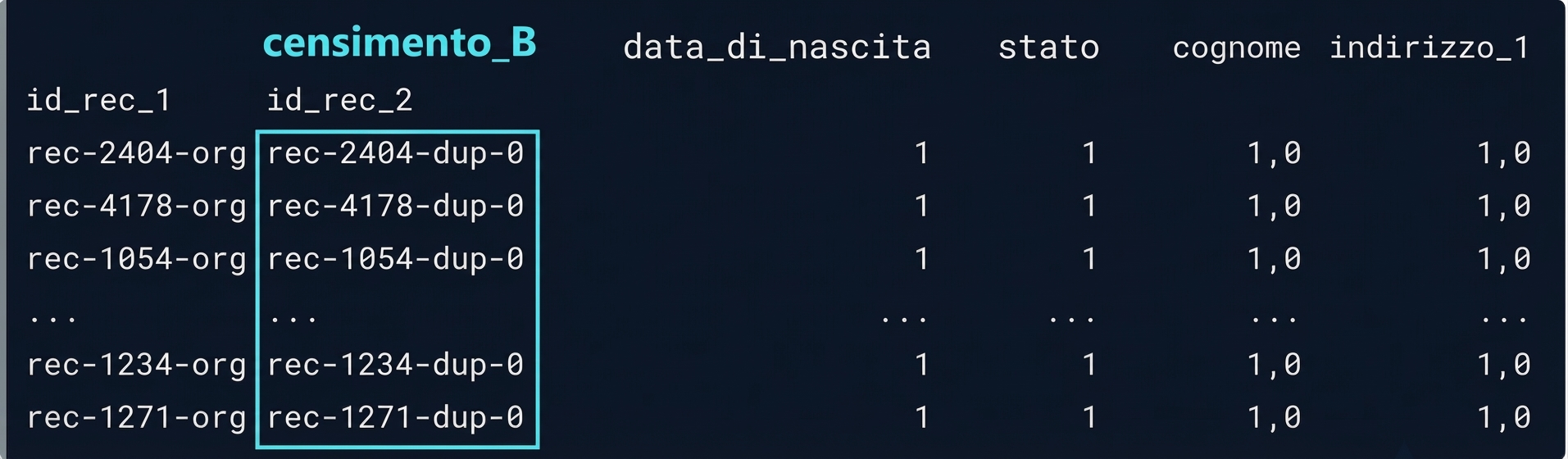
Possibili corrispondenze
potential_matches
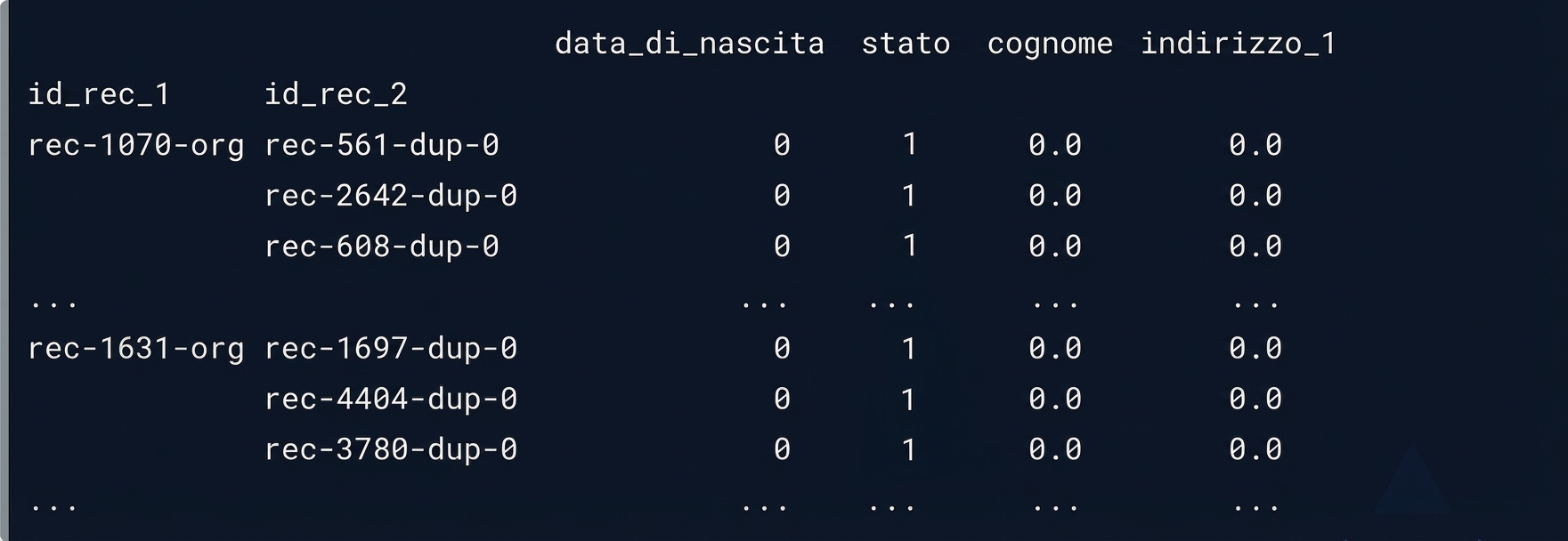
Possibili corrispondenze
potential_matches
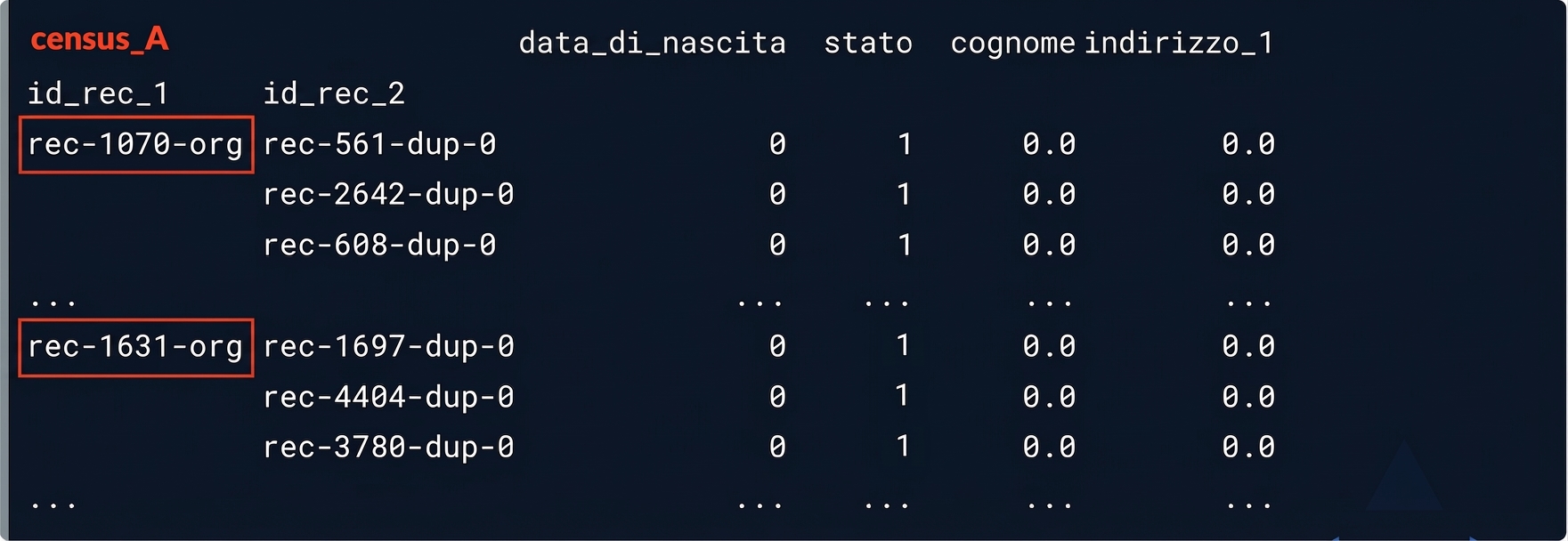
Possibili corrispondenze
potential_matches
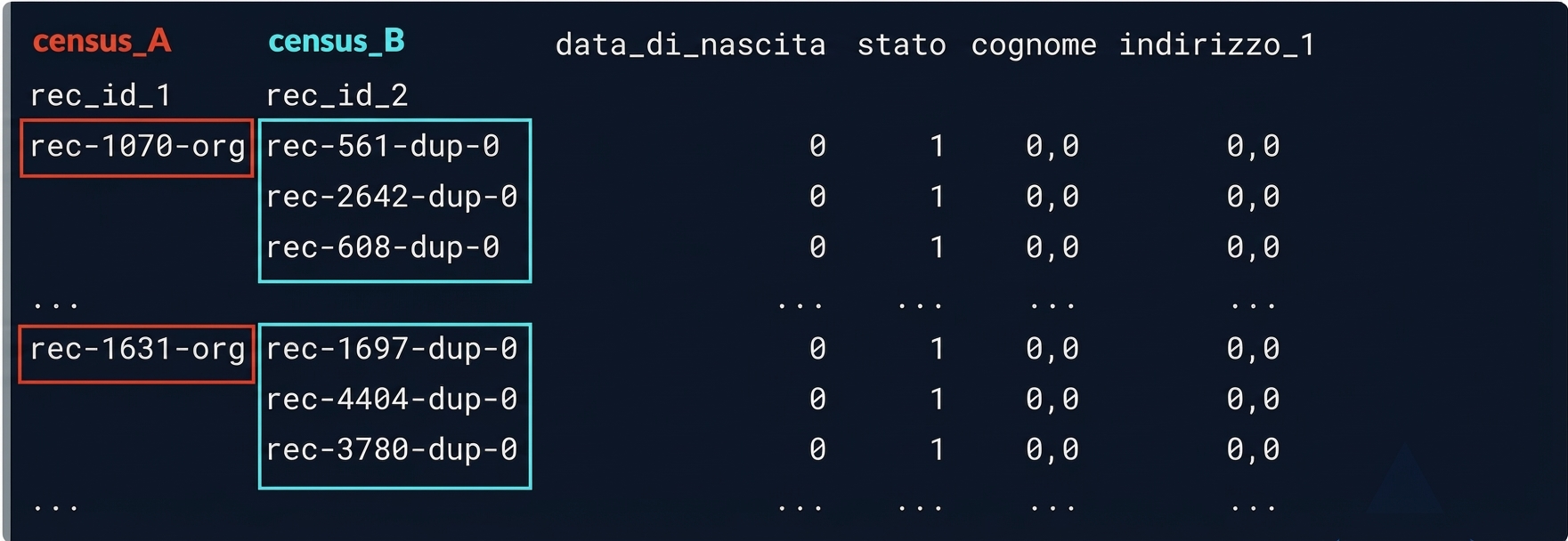
Possibili corrispondenze
potential_matches
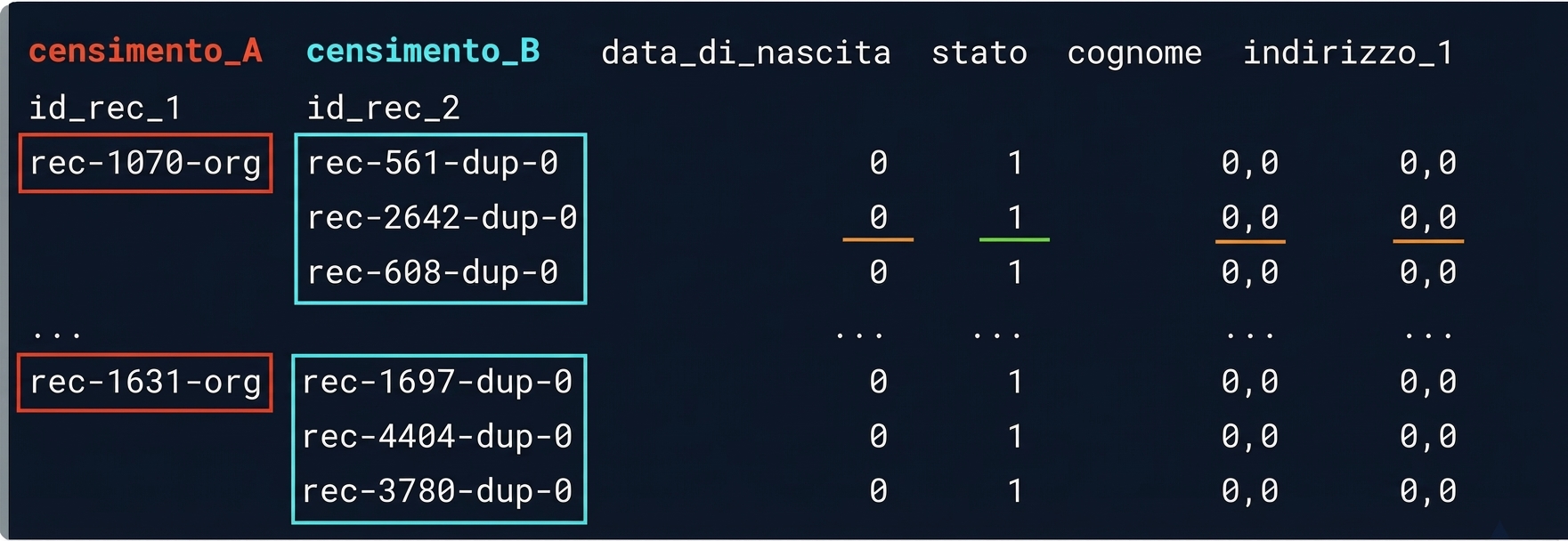
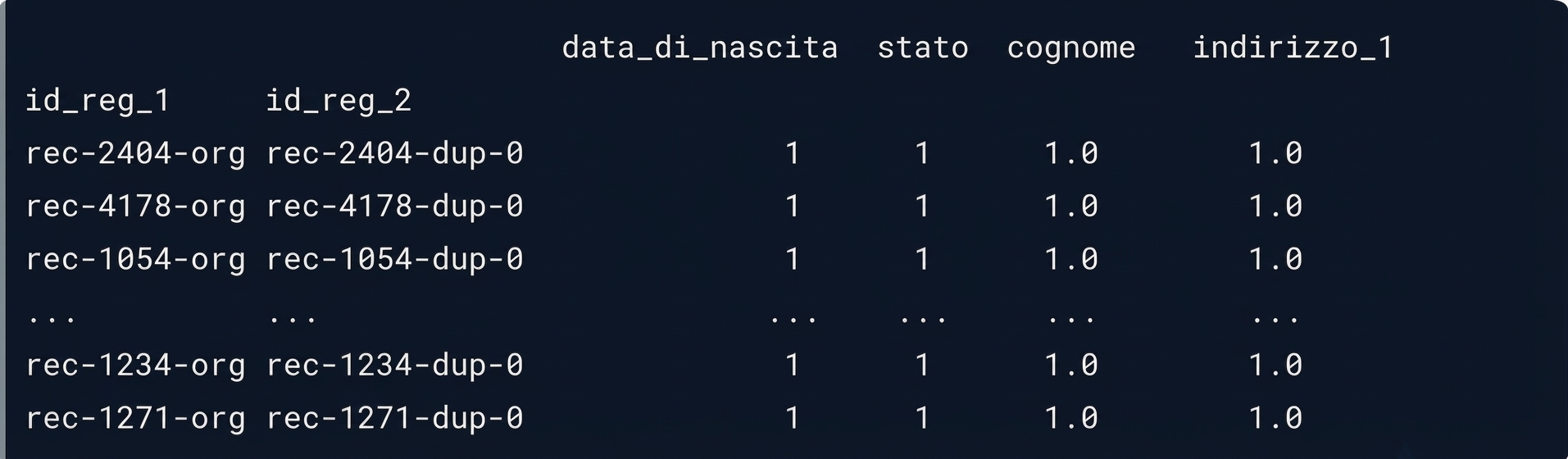
Corrispondenze probabili
matches = potential_matches[potential_matches.sum(axis = 1) >= 3]
print(matches)
Corrispondenze probabili
matches = potential_matches[potential_matches.sum(axis = 1) >= 3]
print(matches)