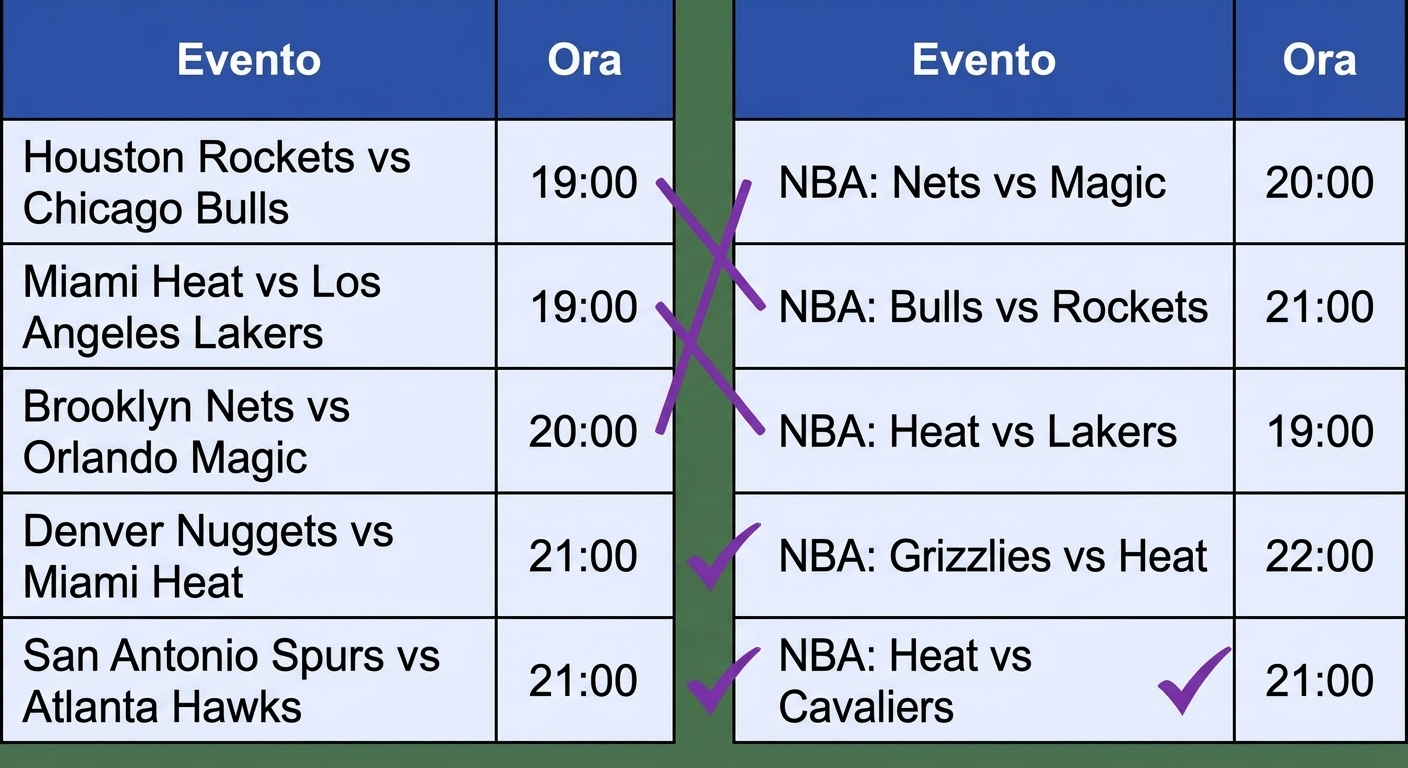
Confrontare stringhe
Pulizia dei dati in Python

Adel Nehme
VP of AI Curriculum, DataCamp
Distanza di edit minima
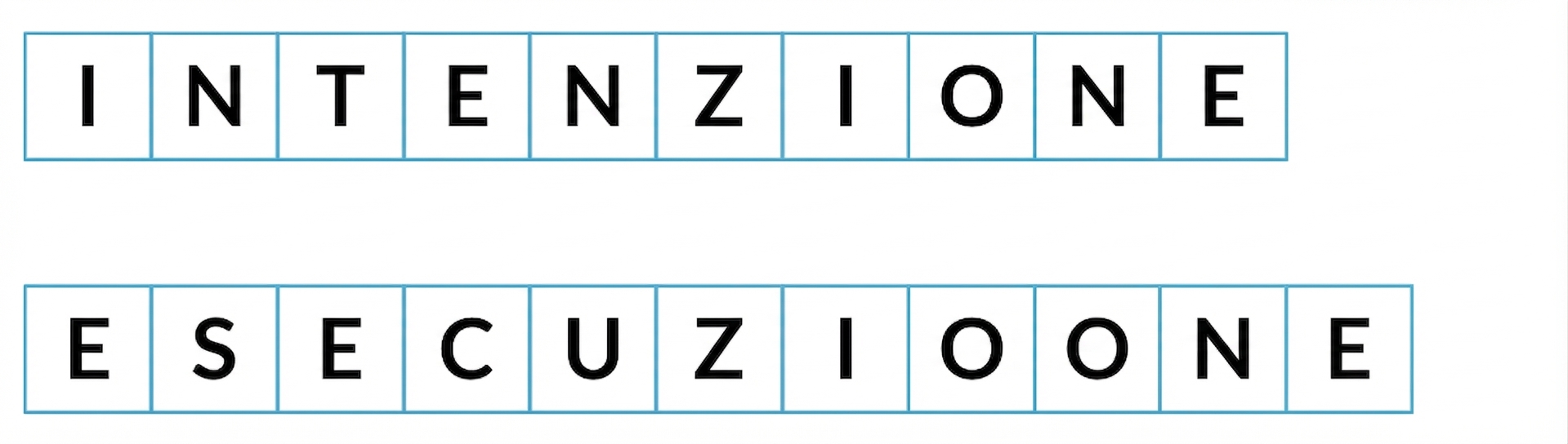
Numero minimo di passaggi per trasformare una stringa in un'altra
Distanza di edit minima
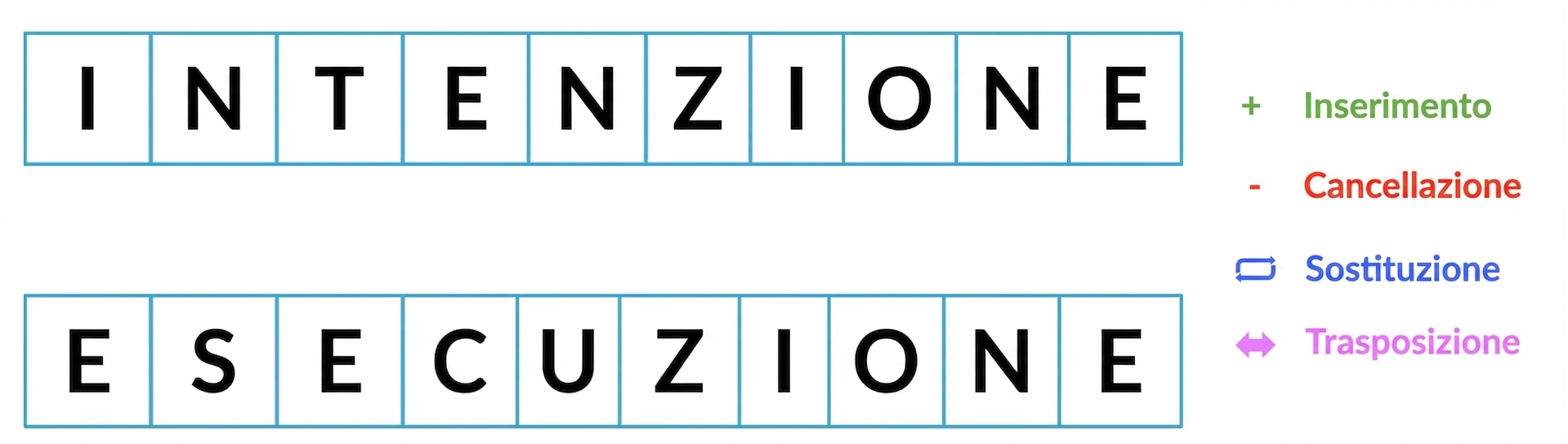
Numero minimo di passaggi per trasformare una stringa in un'altra
Distanza di edit minima
Distanza di edit minima
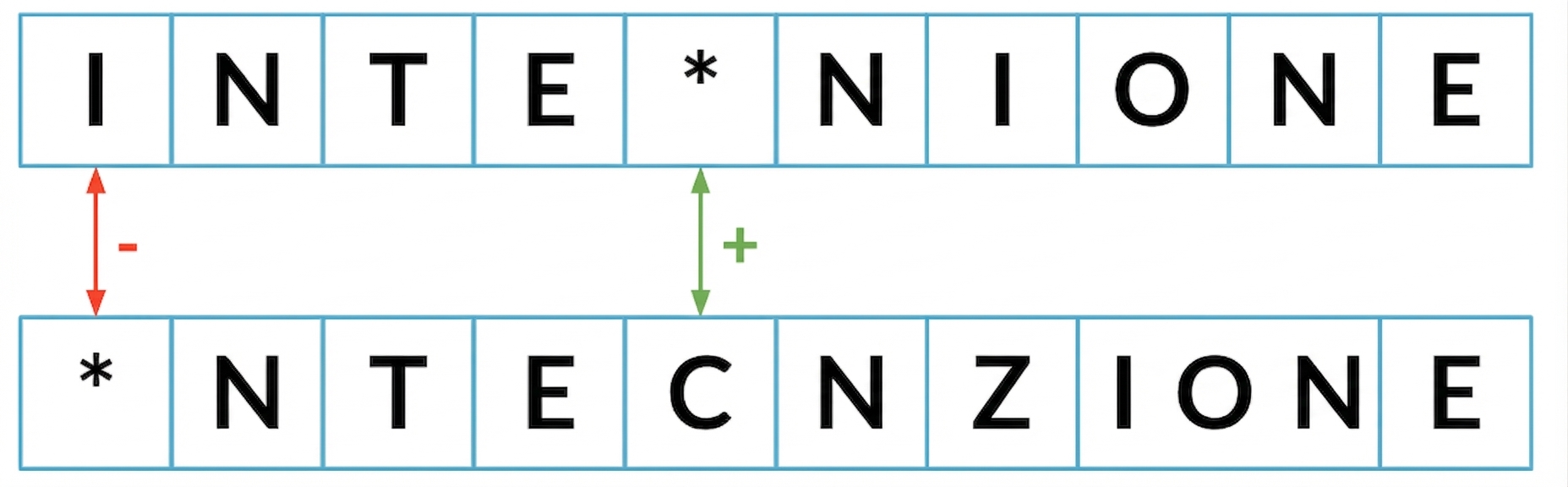
Distanza di edit minima finora: 2
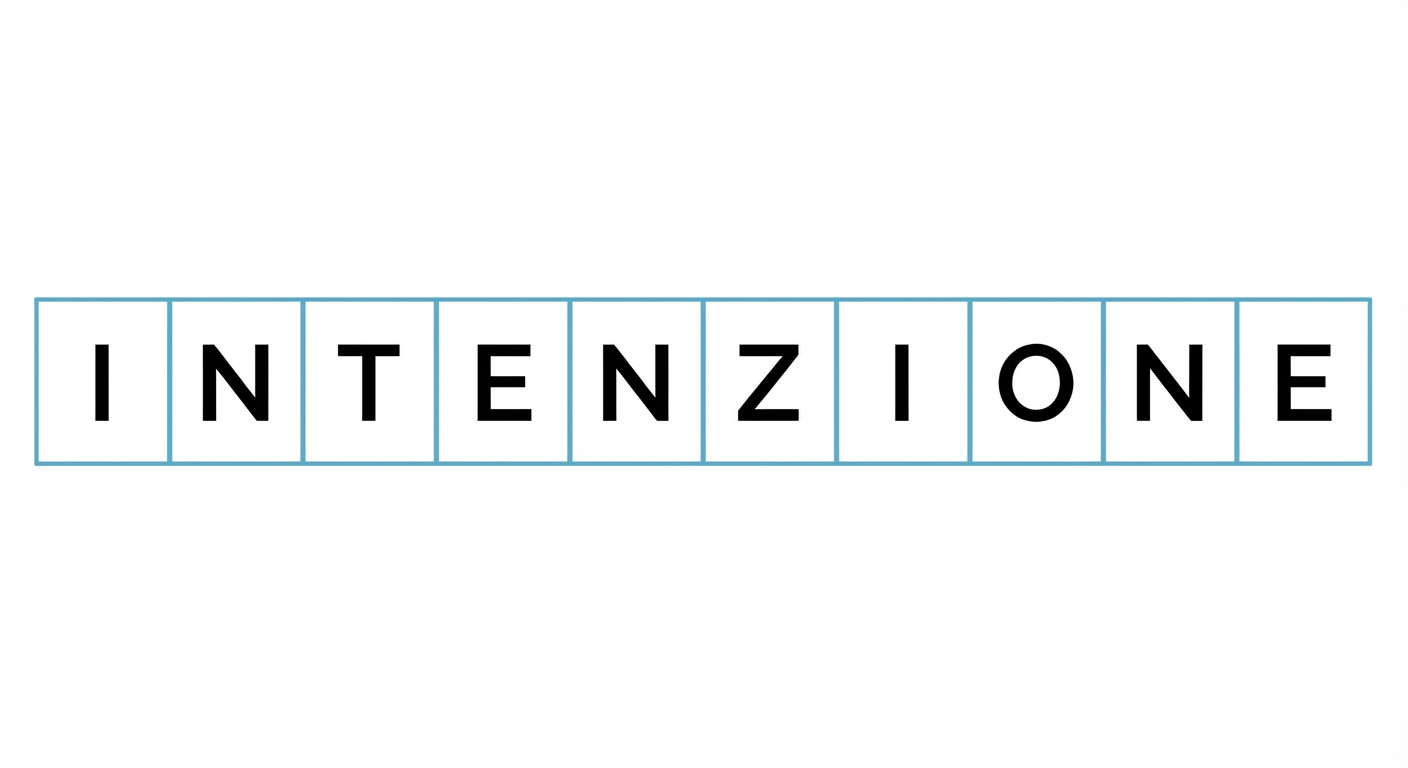
Distanza di edit minima
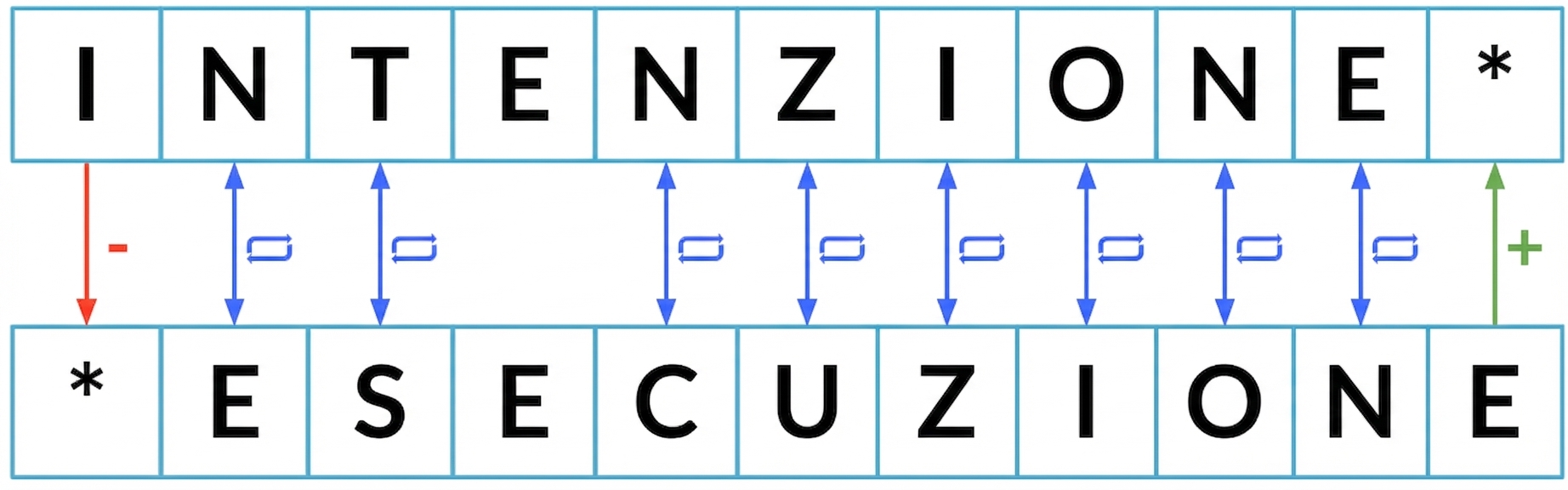
Distanza di edit minima: 5
Distanza di edit minima
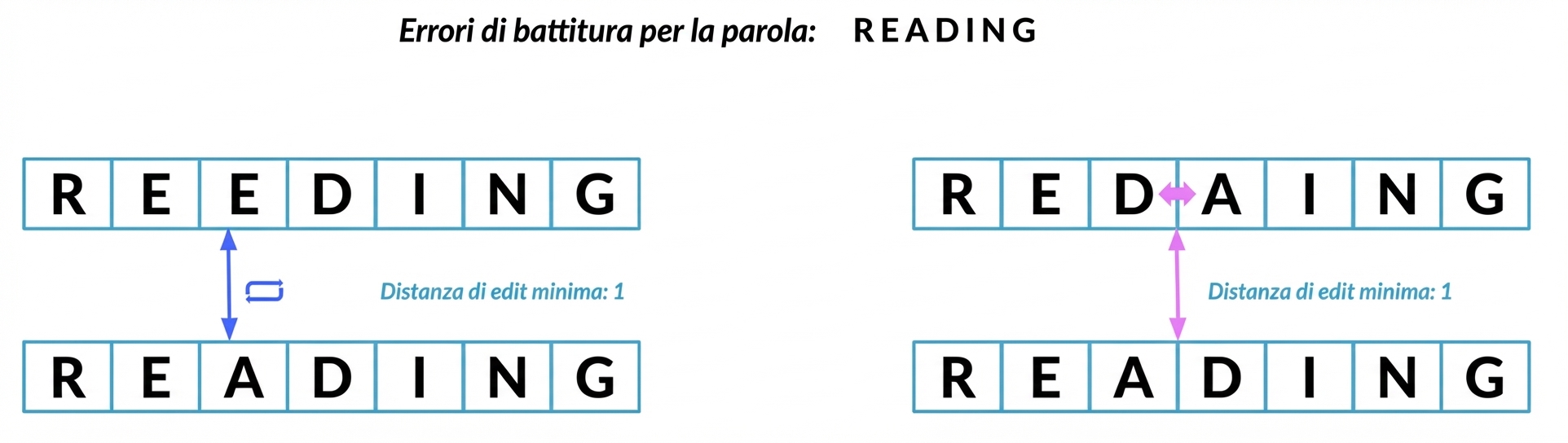
Record linkage