Metriche per task linguistici: ROUGE, METEOR, EM
Introduzione agli LLM in Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Task LLM e metriche
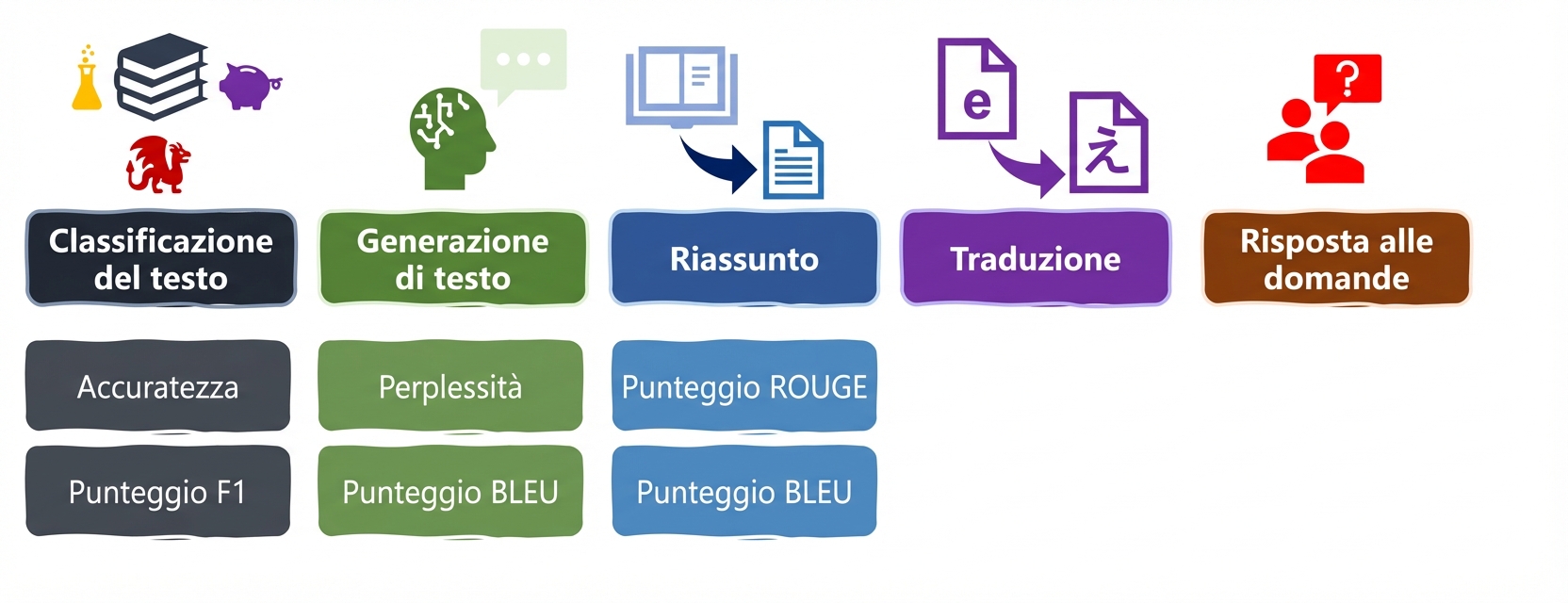
Task LLM e metriche
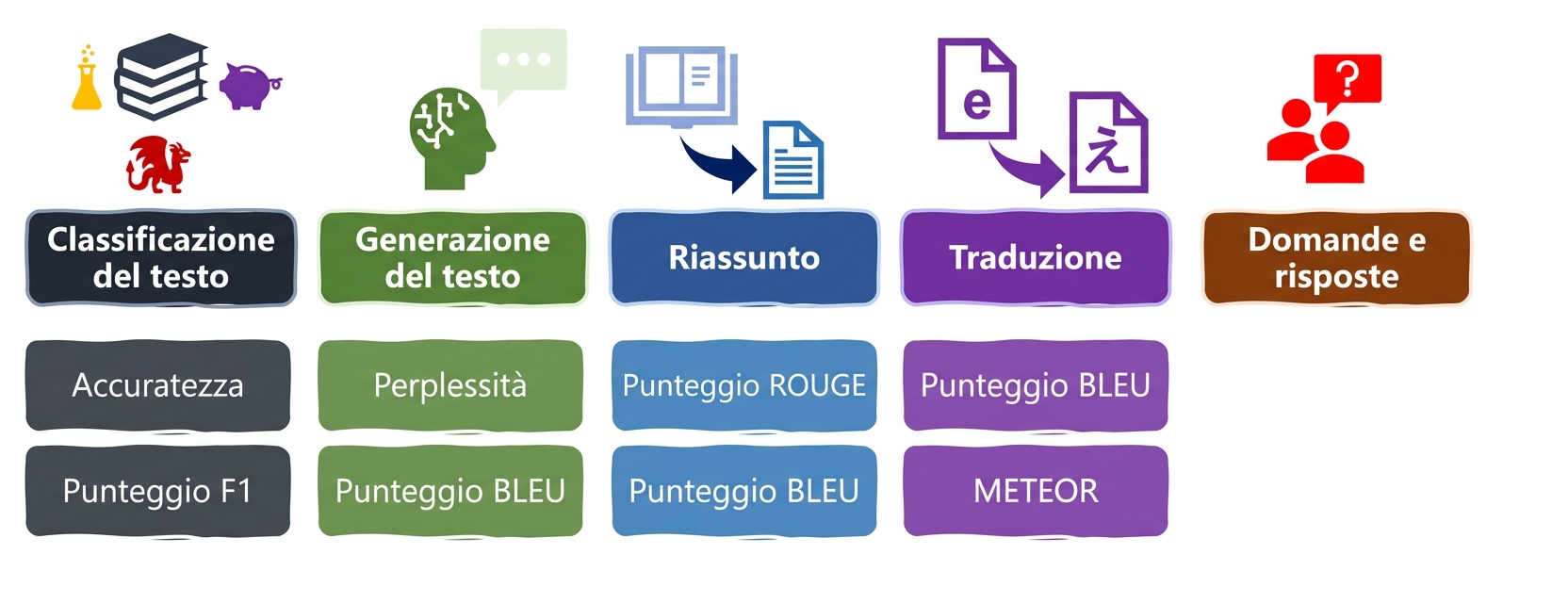
Task LLM e metriche
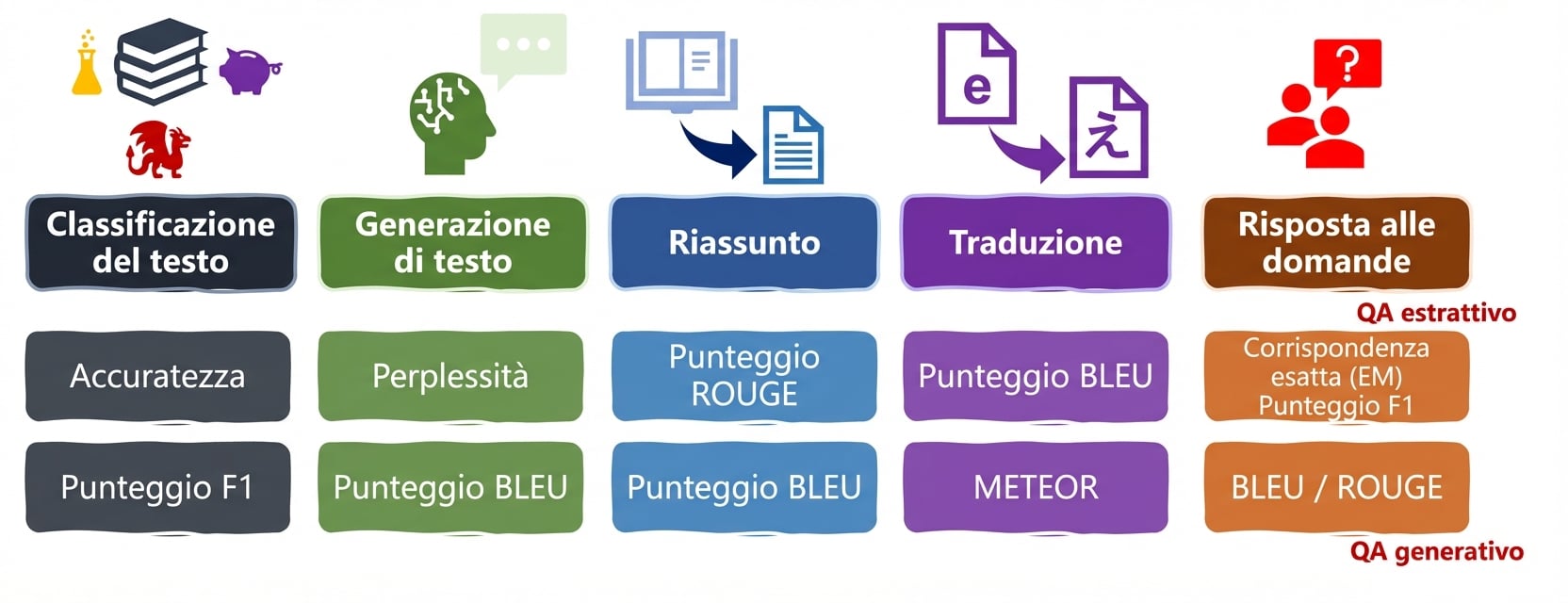
ROUGE
- ROUGE: similarità tra un riassunto generato e i riassunti di riferimento
- Considera n-grammi e overlap
predictions:output dell’LLMreferences: riassunti umani

Domanda e risposta

