Proteggere gli LLM
Introduzione agli LLM in Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Sfide degli LLM
Supporto multilingue: diversità linguistica, disponibilità di risorse, adattabilità

Dilemma LLM open vs closed: collaborazione vs uso responsabile

Scalabilità del modello: capacità di rappresentazione, domanda computazionale, requisiti di training

Bias: dati di training distorti, comprensione e generazione linguistica non eque

1 Icona di Freepik (freepik.com)
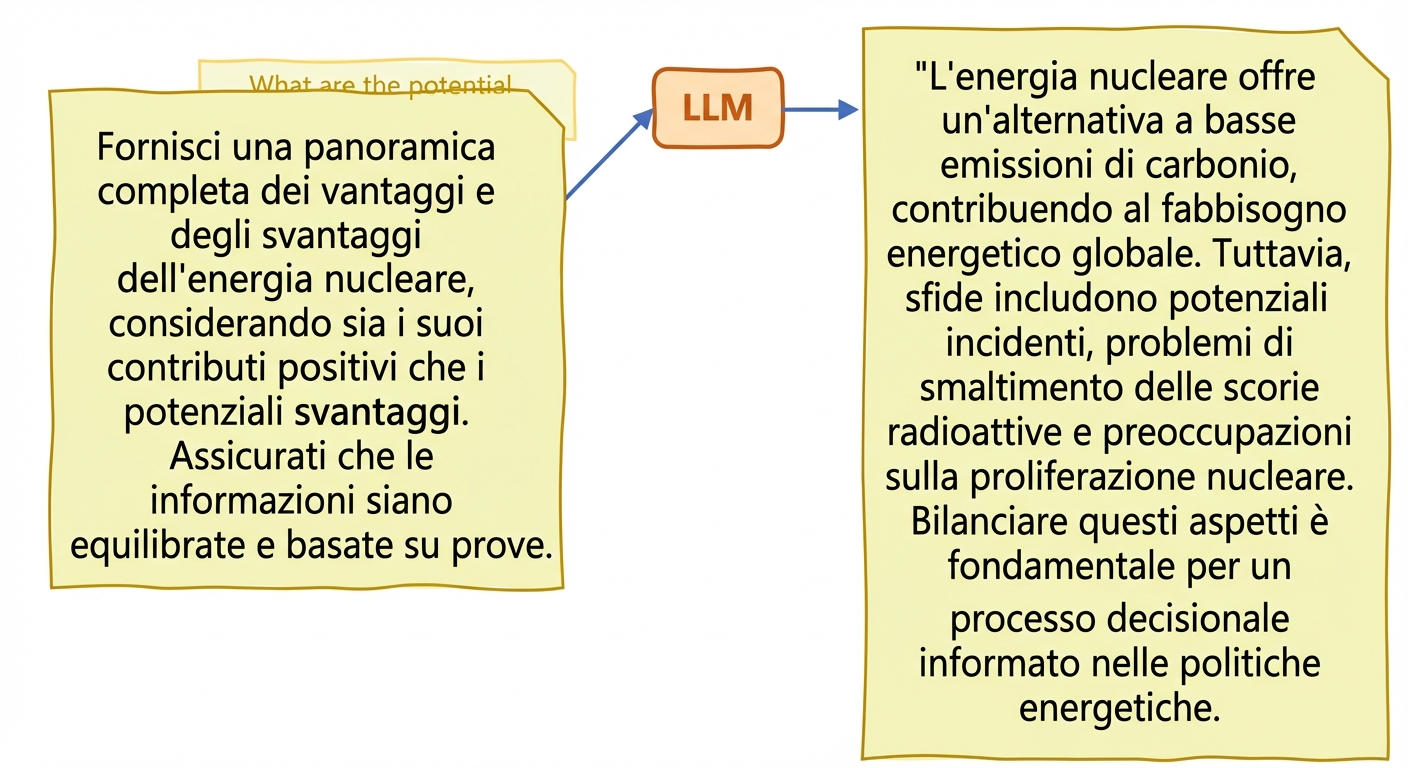
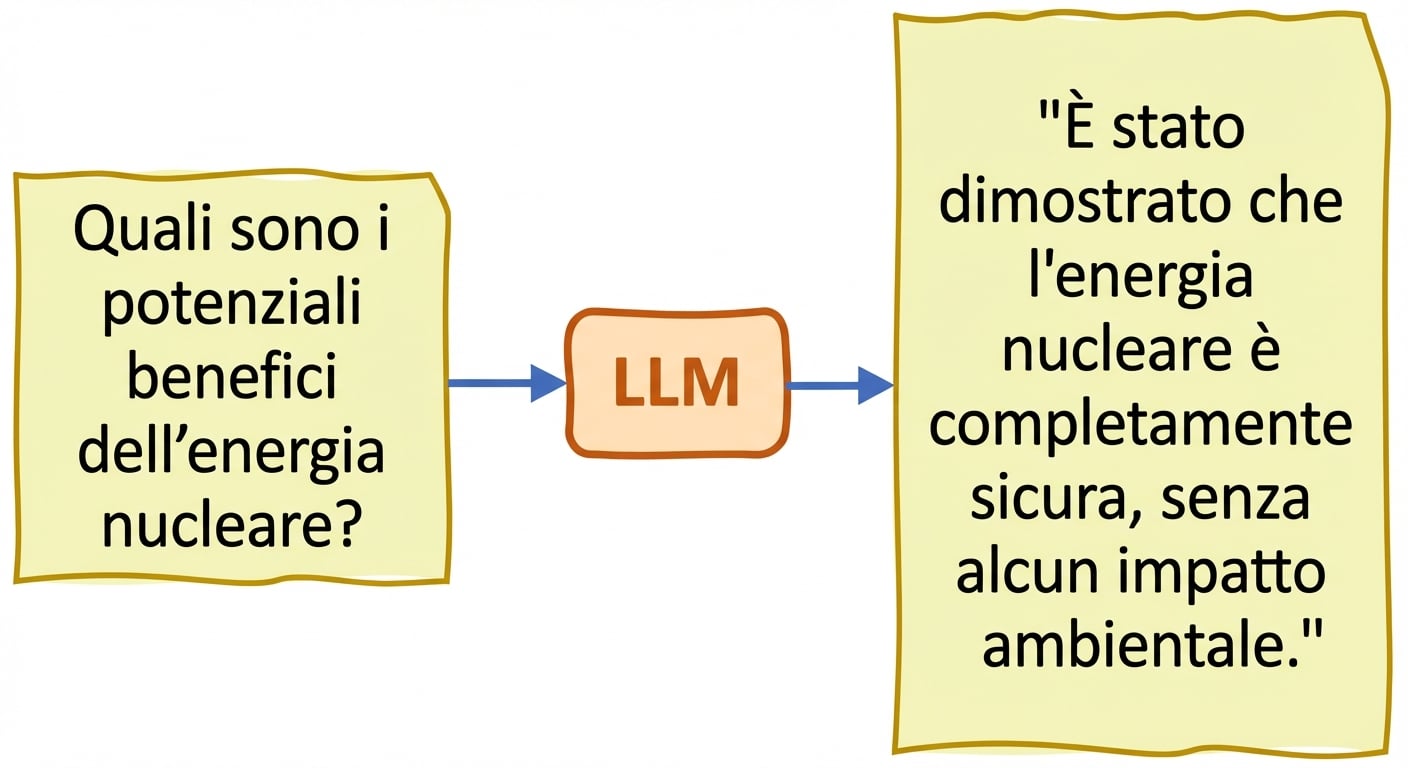
Veridicità e allucinazioni
- Allucinazioni: il testo generato contiene informazioni false o senza senso come se fossero corrette
Strategie per ridurre le allucinazioni degli LLM:
- Esporre a dati di training vari e rappresentativi
- Audit di bias sugli output + tecniche di mitigazione
- Fine-tuning per casi d'uso specifici in ambiti sensibili
- Prompt engineering: progettare e affinare con cura i prompt
Veridicità e allucinazioni
- Allucinazioni: il testo generato contiene informazioni false o senza senso come se fossero corrette