Prepararsi al fine-tuning
Introduzione agli LLM in Python

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
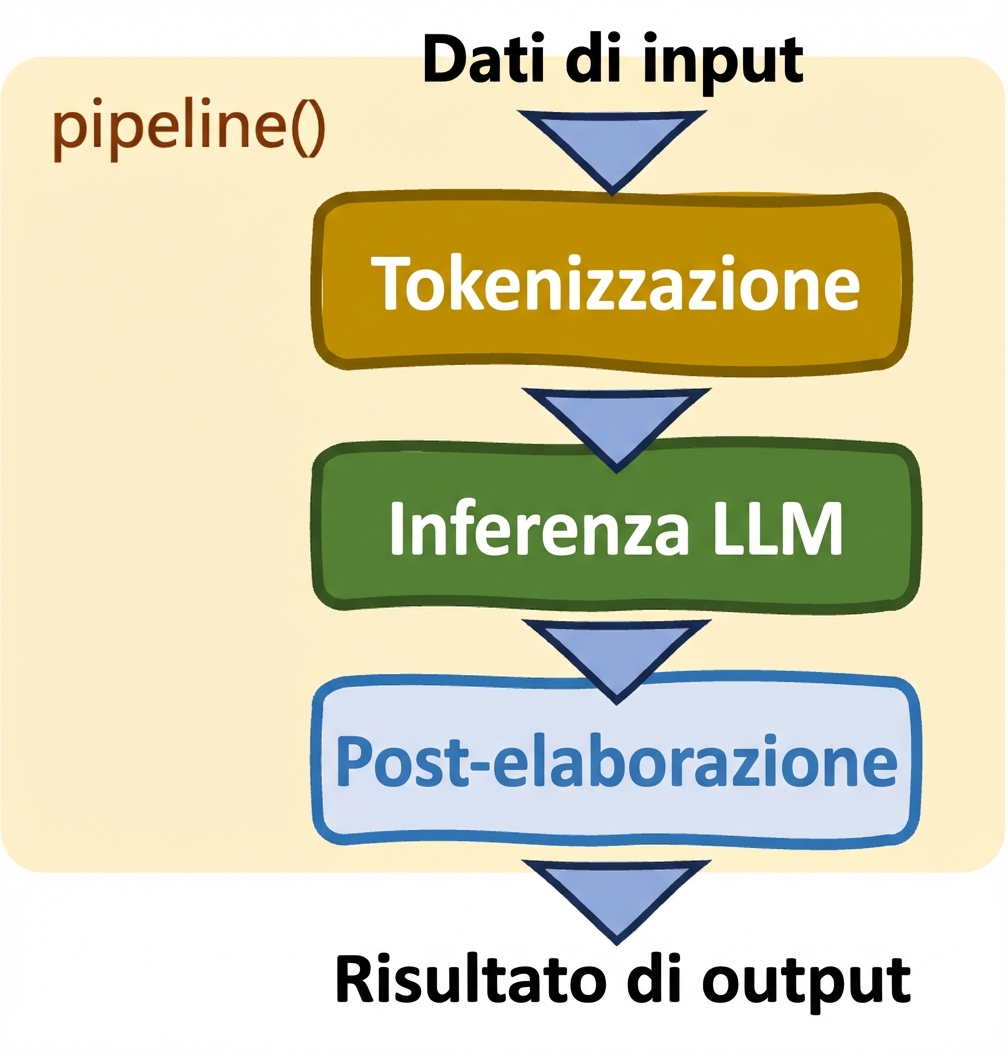
Pipeline e classi Auto
Pipeline: pipeline()
- Semplifica i task
- Selezione automatica di modello e tokenizer
- Controllo limitato
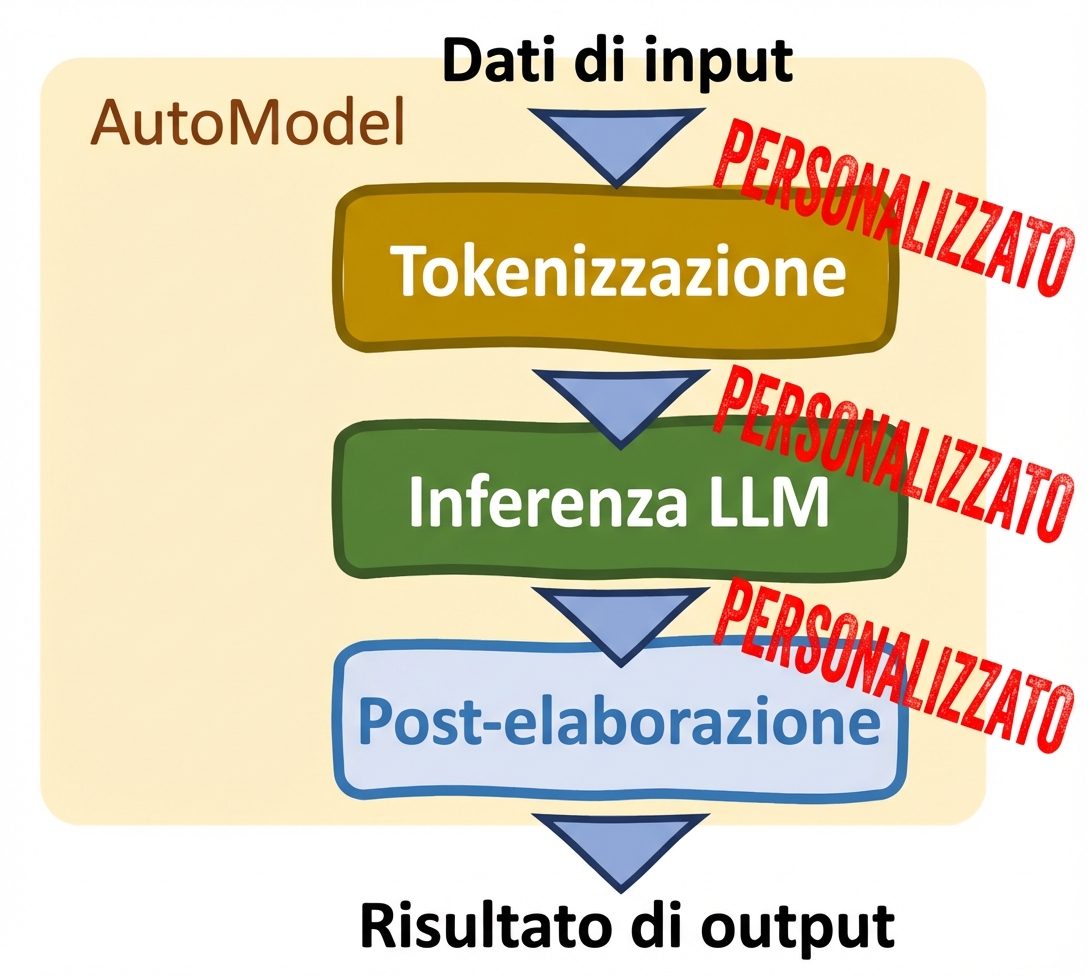
Classi Auto (AutoModel class)
- Personalizzazione
- Regolazioni manuali
- Supporta il fine-tuning
Ciclo di vita degli LLM
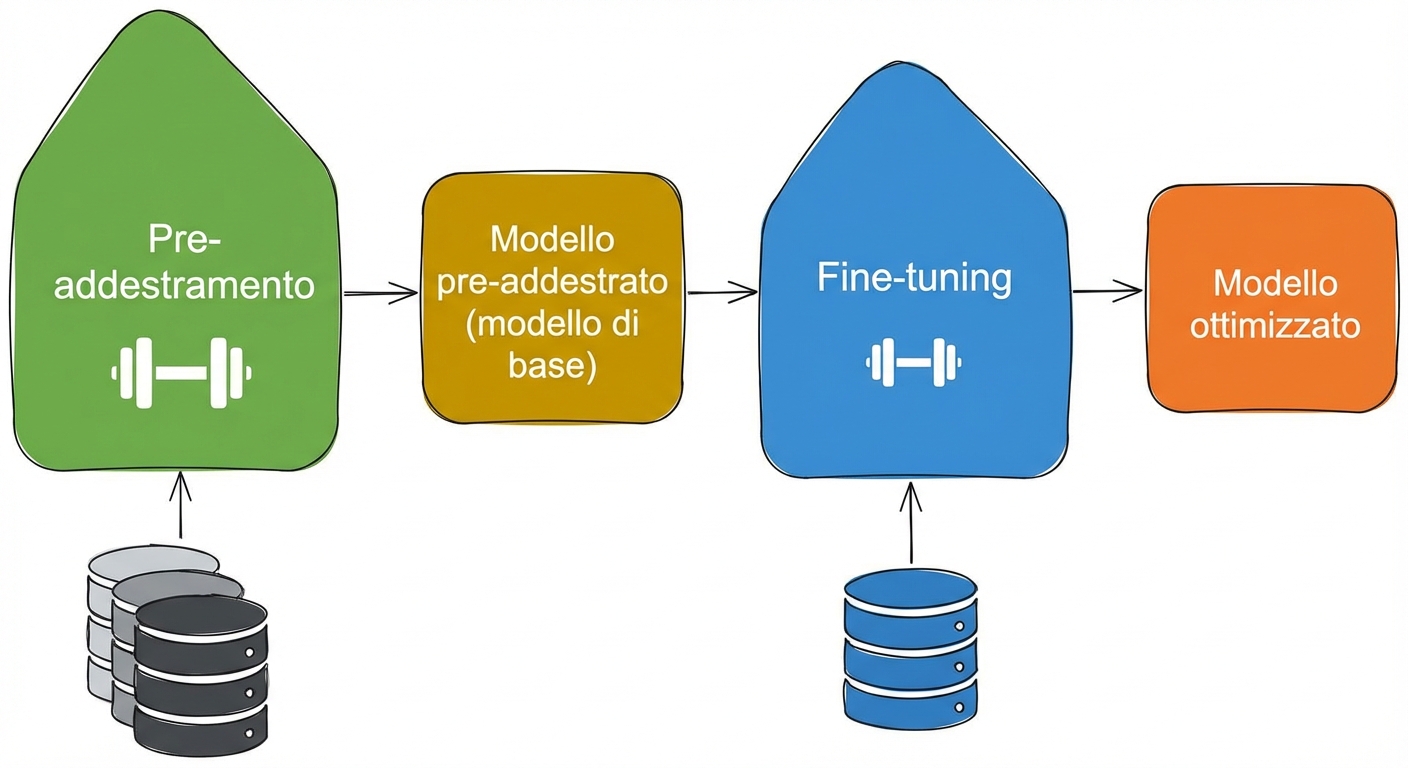
Ciclo di vita degli LLM
Tokenizzazione a sottoparole
- Comune nei tokenizer moderni
- Le parole si dividono in sotto-parti significative

Tokenizzazione a sottoparole
- Comune nei tokenizer moderni
- Le parole si dividono in sotto-parti significative


