Trasformare le variabili
Introduzione alla regressione con statsmodels in Python

Maarten Van den Broeck
Content Developer at DataCamp
Dataset delle persiche

Non è una relazione lineare
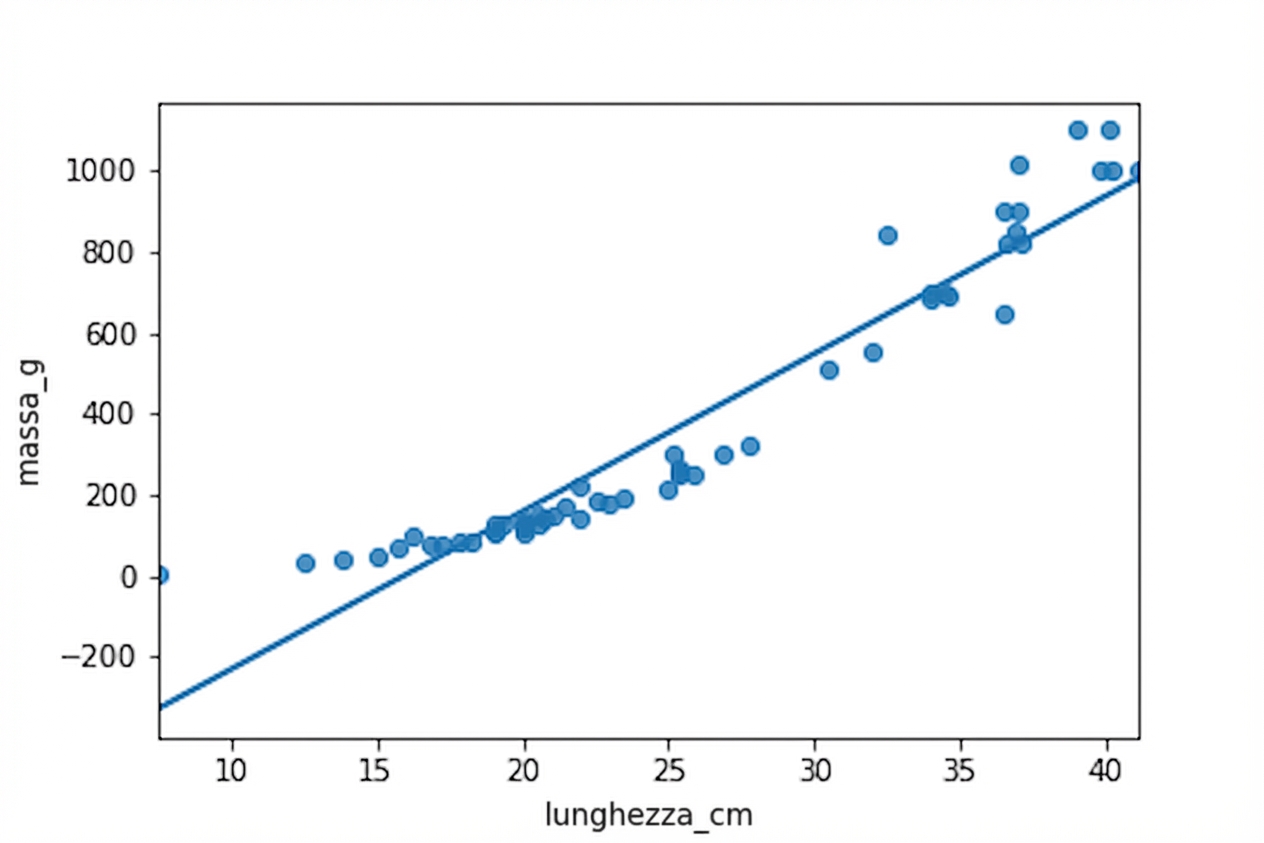
Brème vs persico

Grafico: massa vs lunghezza^3
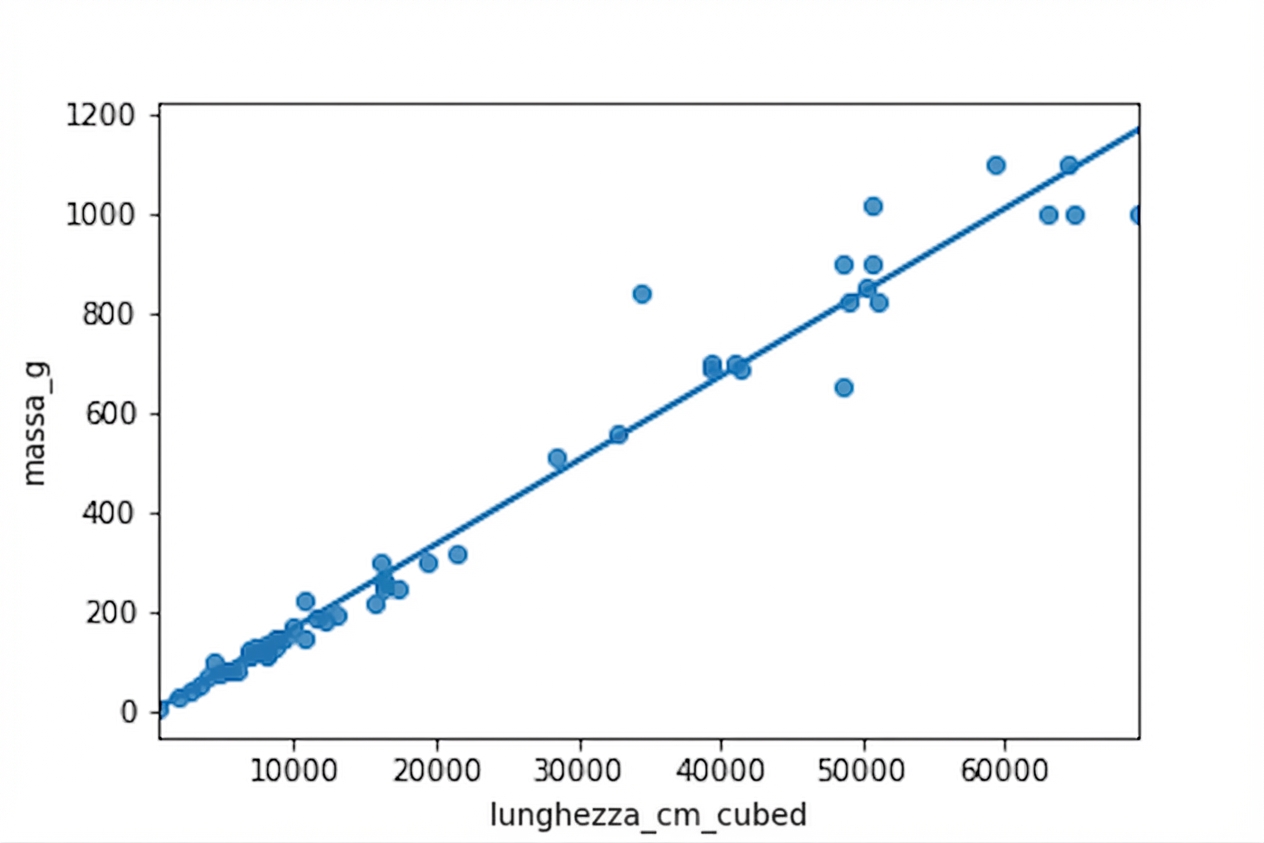
Grafico: massa vs lunghezza^3
fig = plt.figure()
sns.regplot(x="length_cm_cubed", y="mass_g",
data=perch, ci=None)
sns.scatterplot(data=prediction_data,
x="length_cm_cubed", y="mass_g",
color="red", marker="s")
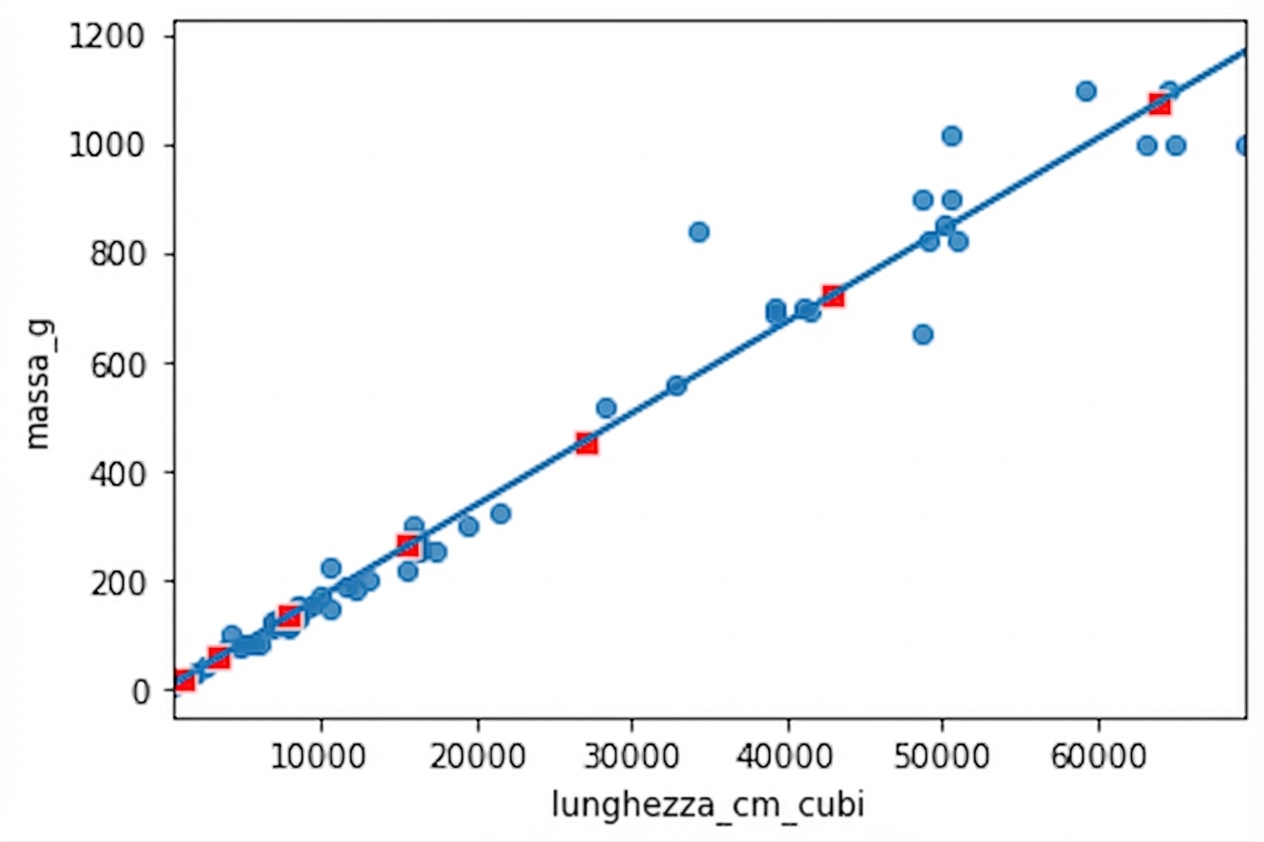
fig = plt.figure()
sns.regplot(x="length_cm", y="mass_g",
data=perch, ci=None)
sns.scatterplot(data=prediction_data,
x="length_cm", y="mass_g",
color="red", marker="s")
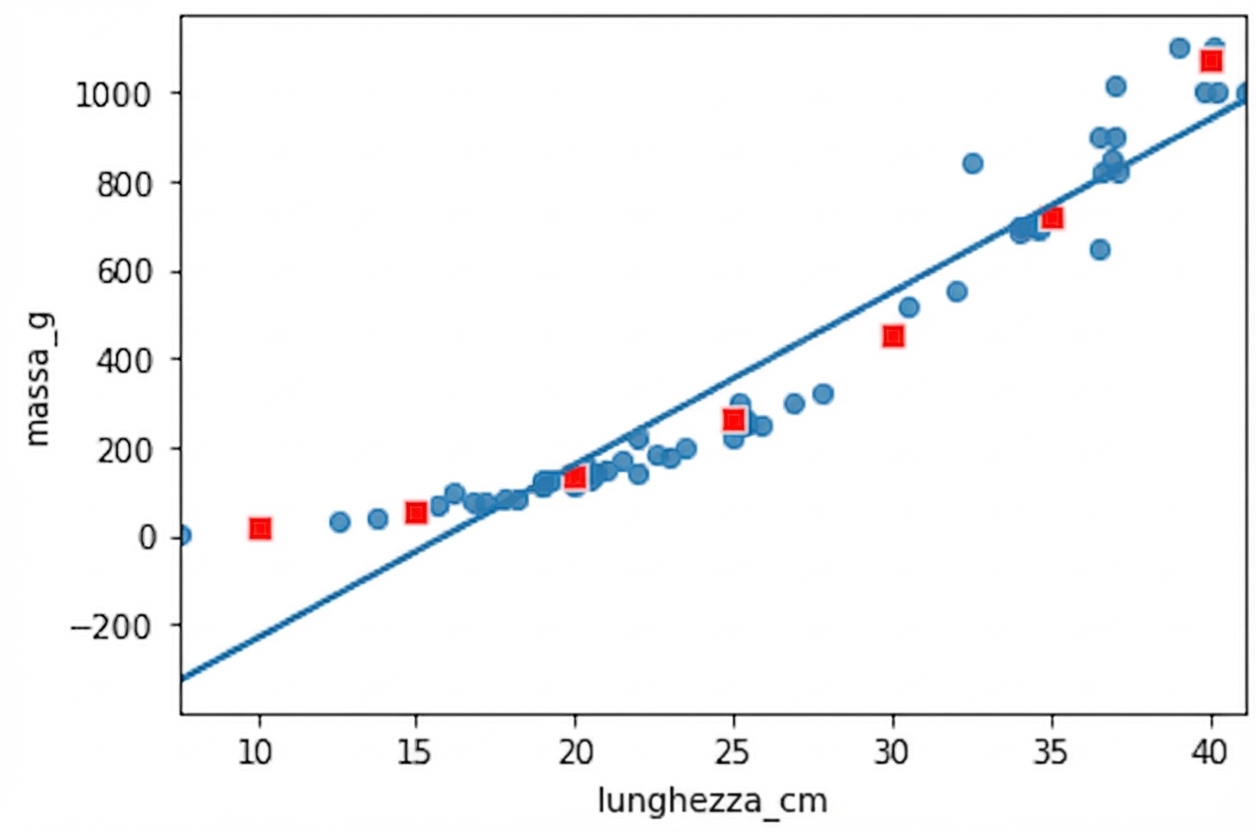
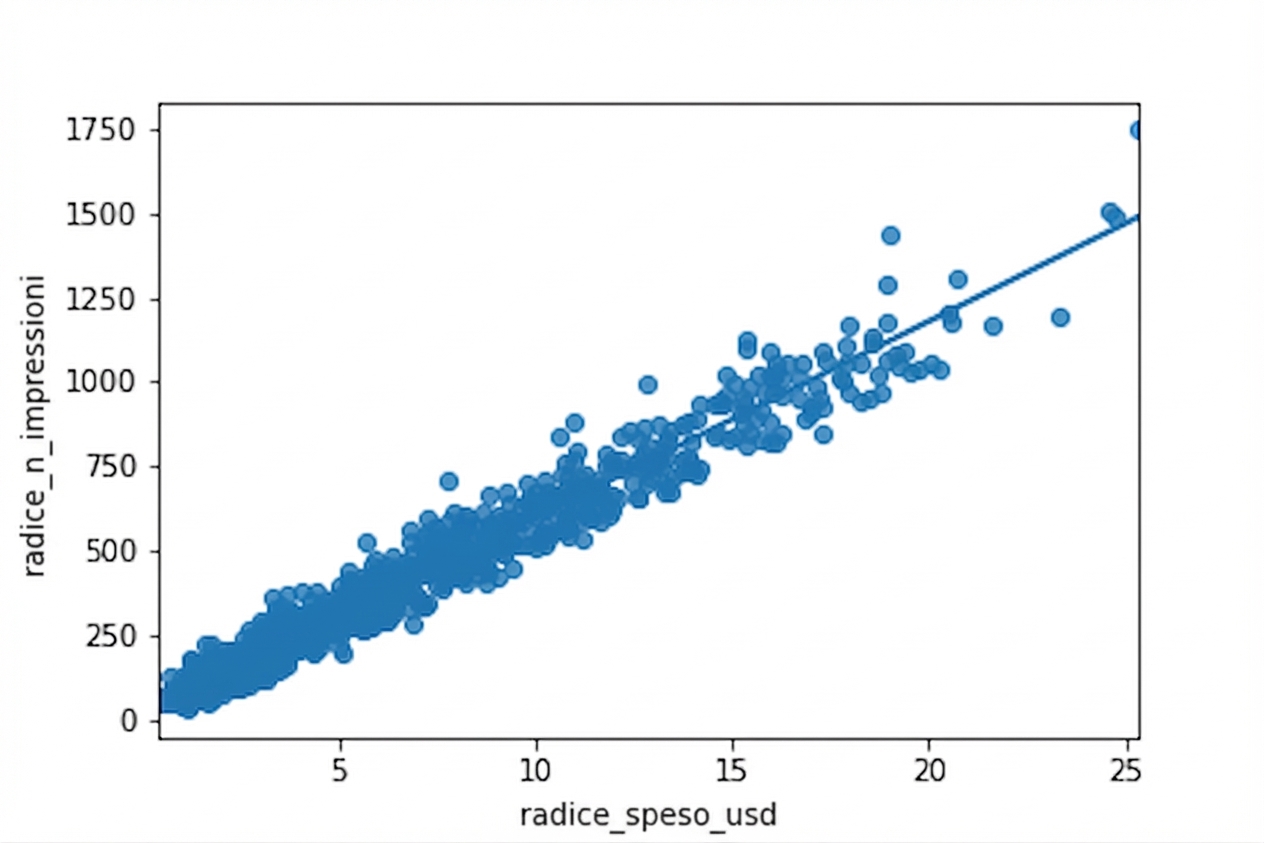
Grafico compresso
Radice quadrata vs radice quadrata