Vanishing and exploding gradients
Deep Learning intermedio con PyTorch

Michal Oleszak
Machine Learning Engineer
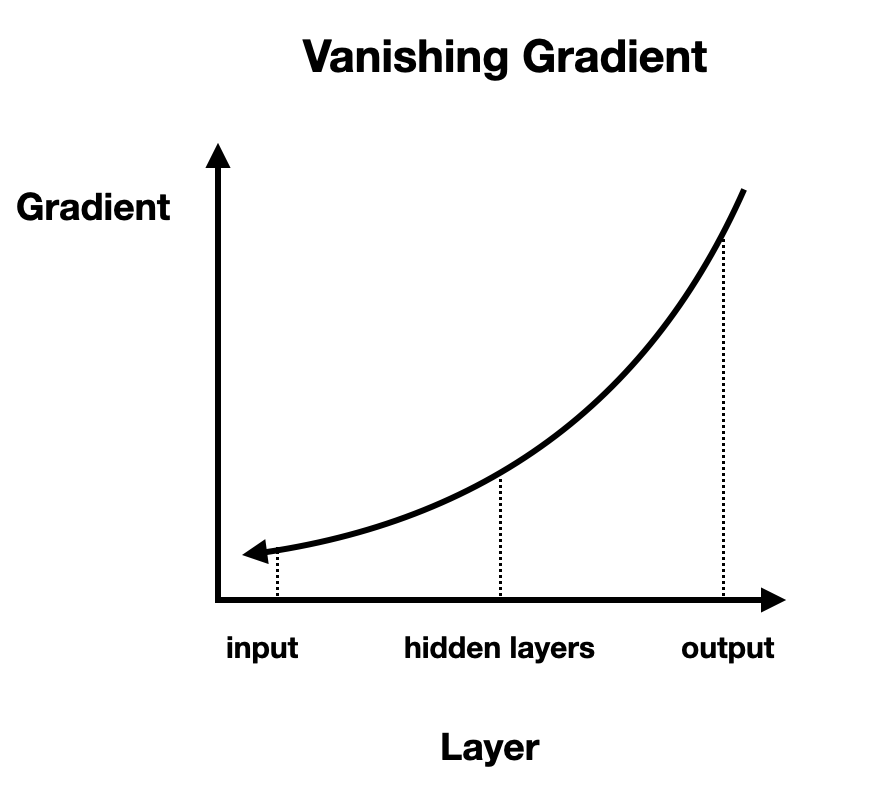
Vanishing gradients
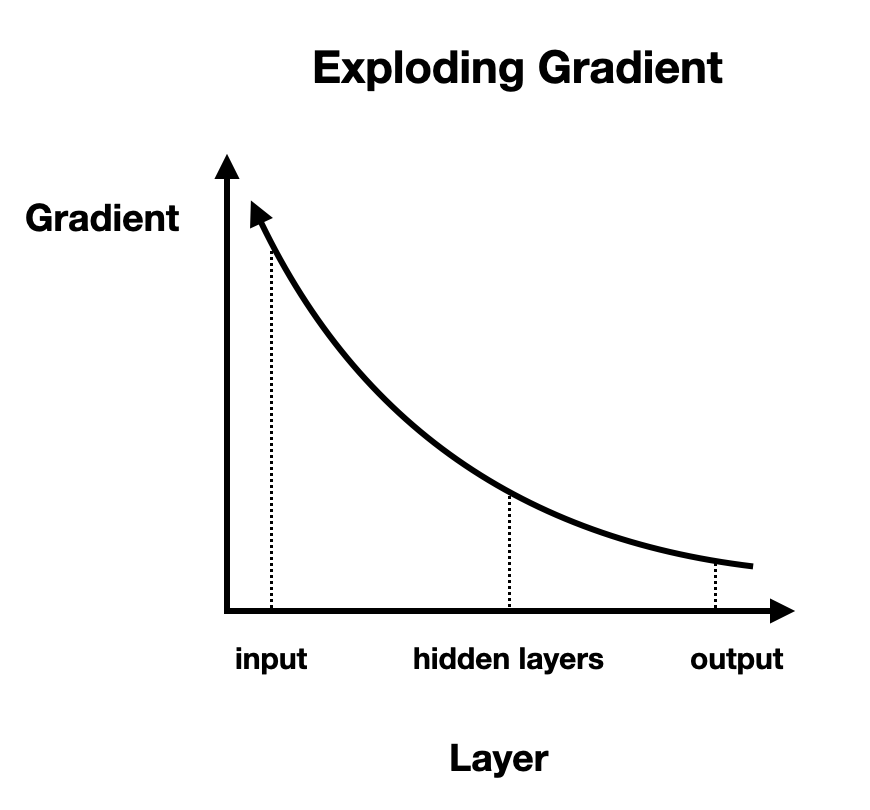
Exploding gradients
Solution to unstable gradients
- Proper weights initialization
- Good activations
- Batch normalization
Activation functions
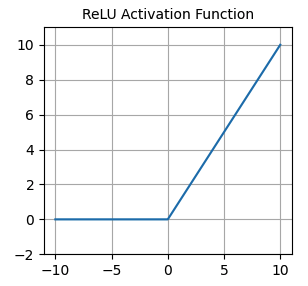
- Often used as the default activation
nn.functional.relu()- Zero for negative inputs - dying neurons
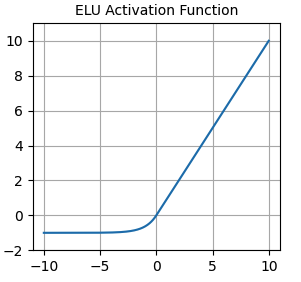
nn.functional.elu()- Non-zero gradients for negative values - helps against dying neurons
- Average output around zero - helps against vanishing gradients

