Parallel computation frameworks
Introduzione al Data Engineering

Vincent Vankrunkelsven
Data Engineer @ DataCamp
![]()
HDFS
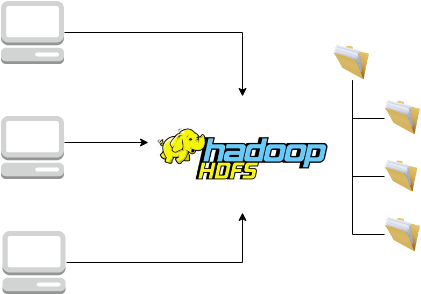
MapReduce
![]()
Hive
- Runs on Hadoop
- Structured Query Language: Hive SQL
- Initially MapReduce, now other tools
![]()
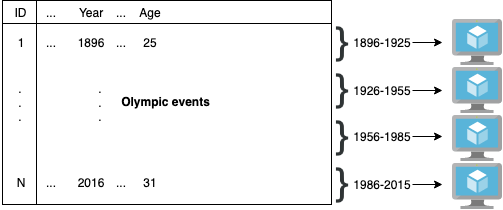
Hive: an example
![]()
- Avoid disk writes
- Maintained by Apache Software Foundation

