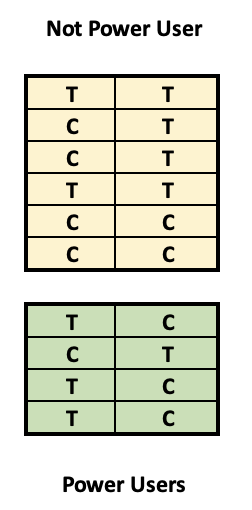
Impostazione dei dati sperimentali
Progettazione Sperimentale in Python

James Chapman
Curriculum Manager, DataCamp
Il problema della randomizzazione
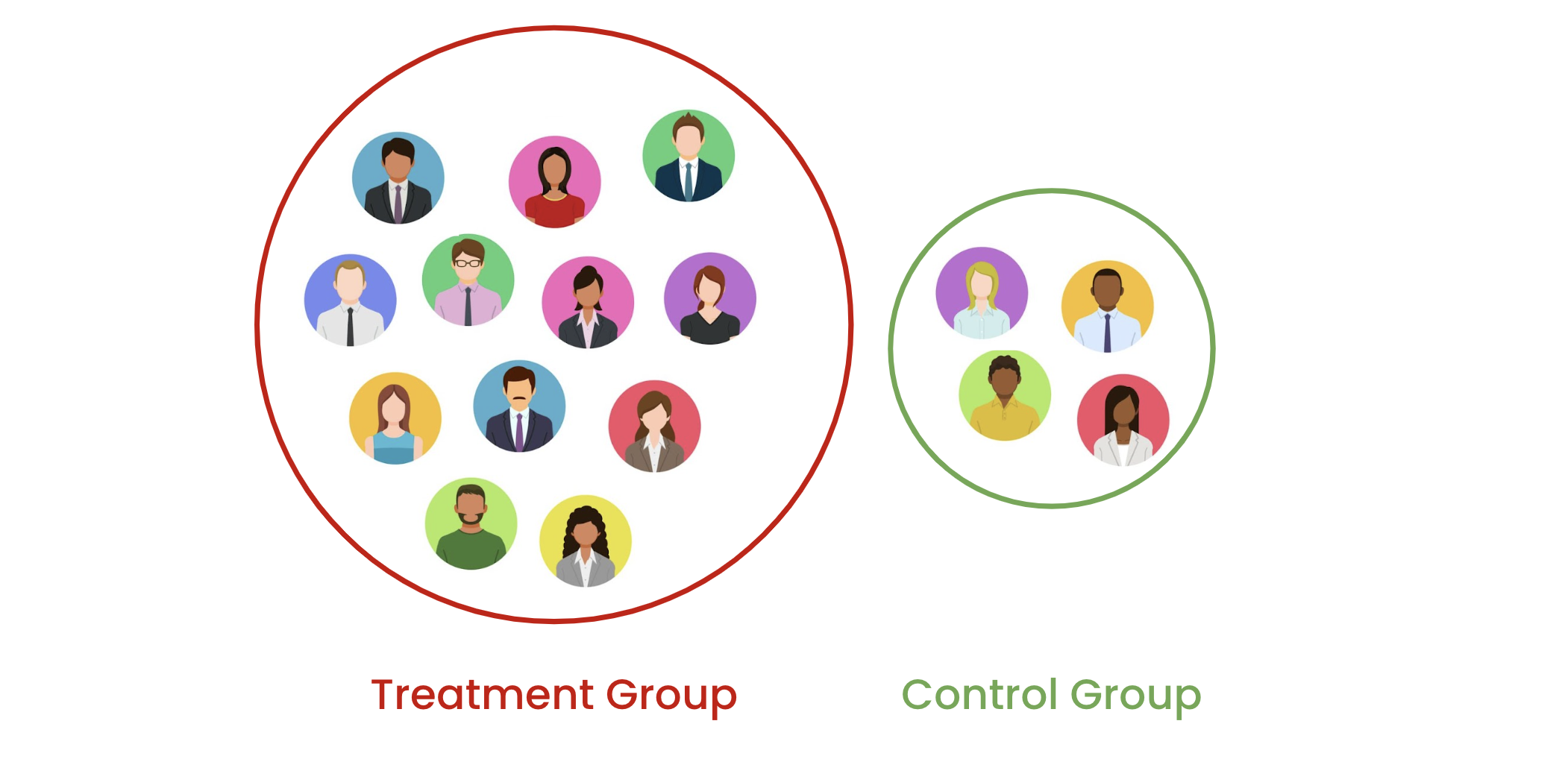
Il problema della randomizzazione
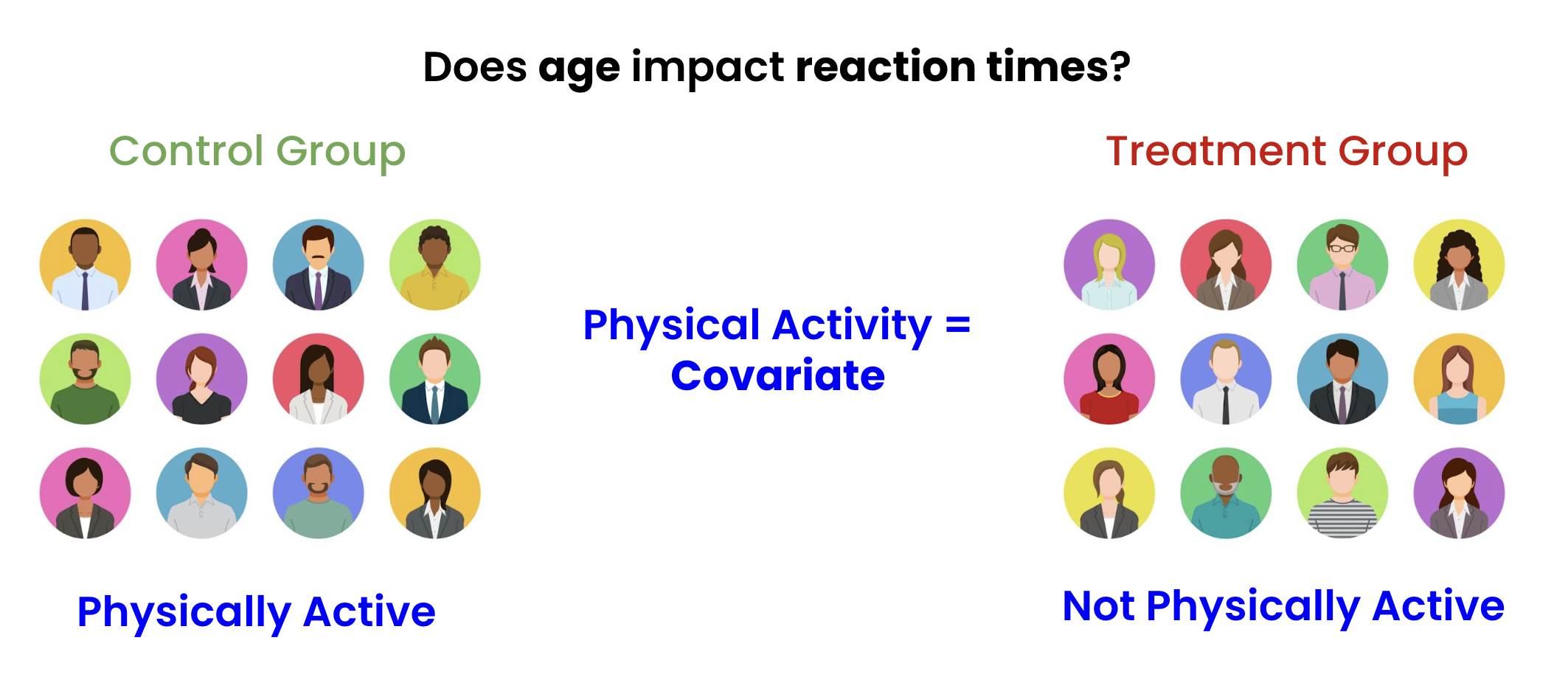
Risultato: più difficile misurare l'effetto del trattamento!
Randomizzazione a blocchi
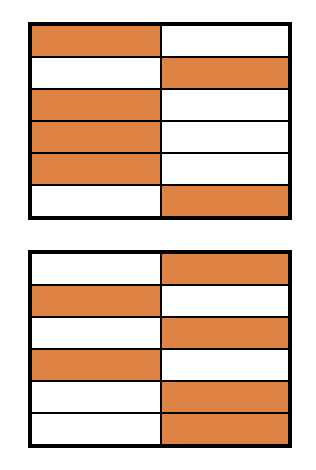
- 24 soggetti divisi in due gruppi, poi randomizzati
Visualizzare gli split
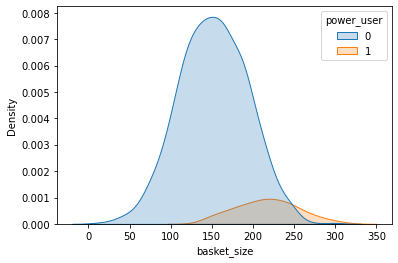
Randomizzazione stratificata