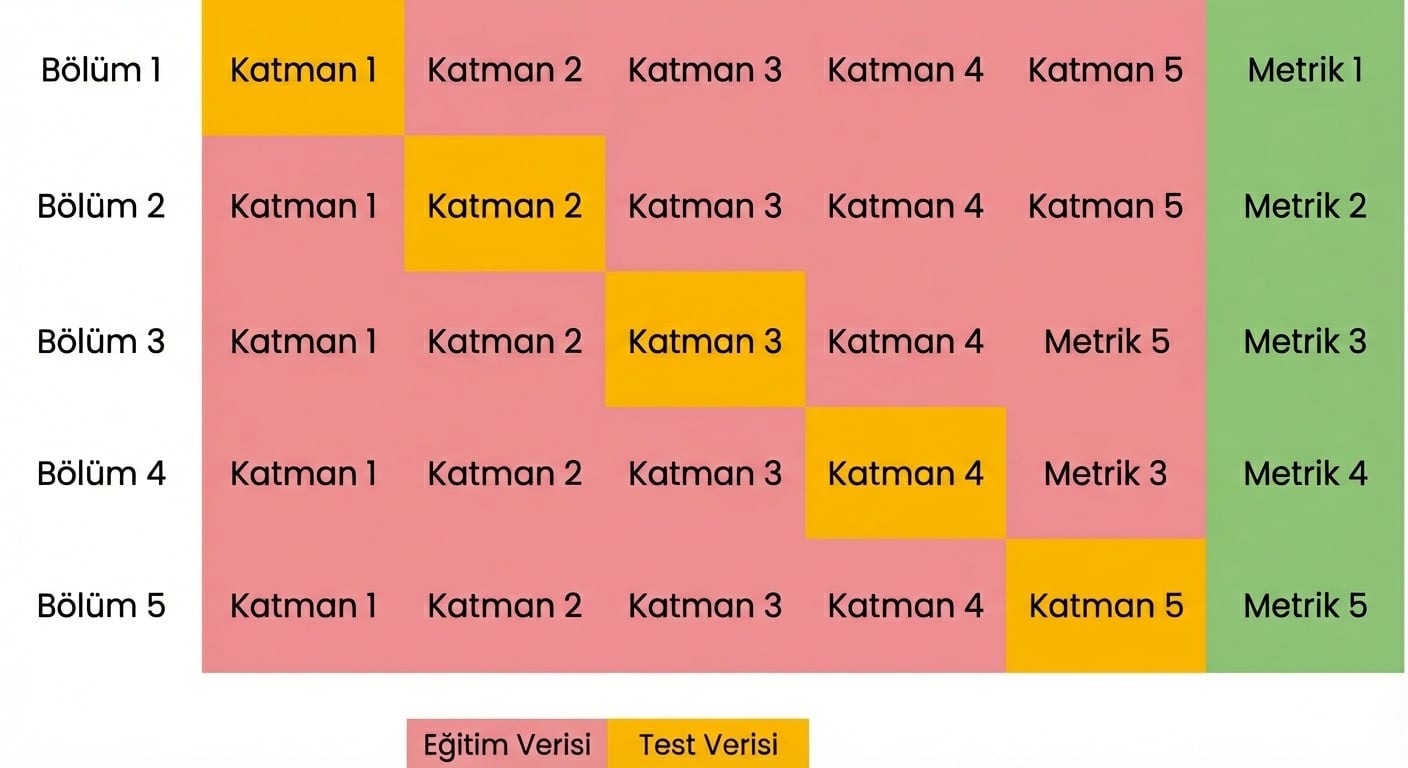
Çapraz doğrulama
scikit-learn ile Supervised Learning

George Boorman
Core Curriculum Manager, DataCamp
Çapraz doğrulamanın temelleri

Çapraz doğrulamanın temelleri

Çapraz doğrulamanın temelleri

Çapraz doğrulamanın temelleri

Çapraz doğrulamanın temelleri

Çapraz doğrulamanın temelleri

Çapraz doğrulamanın temelleri
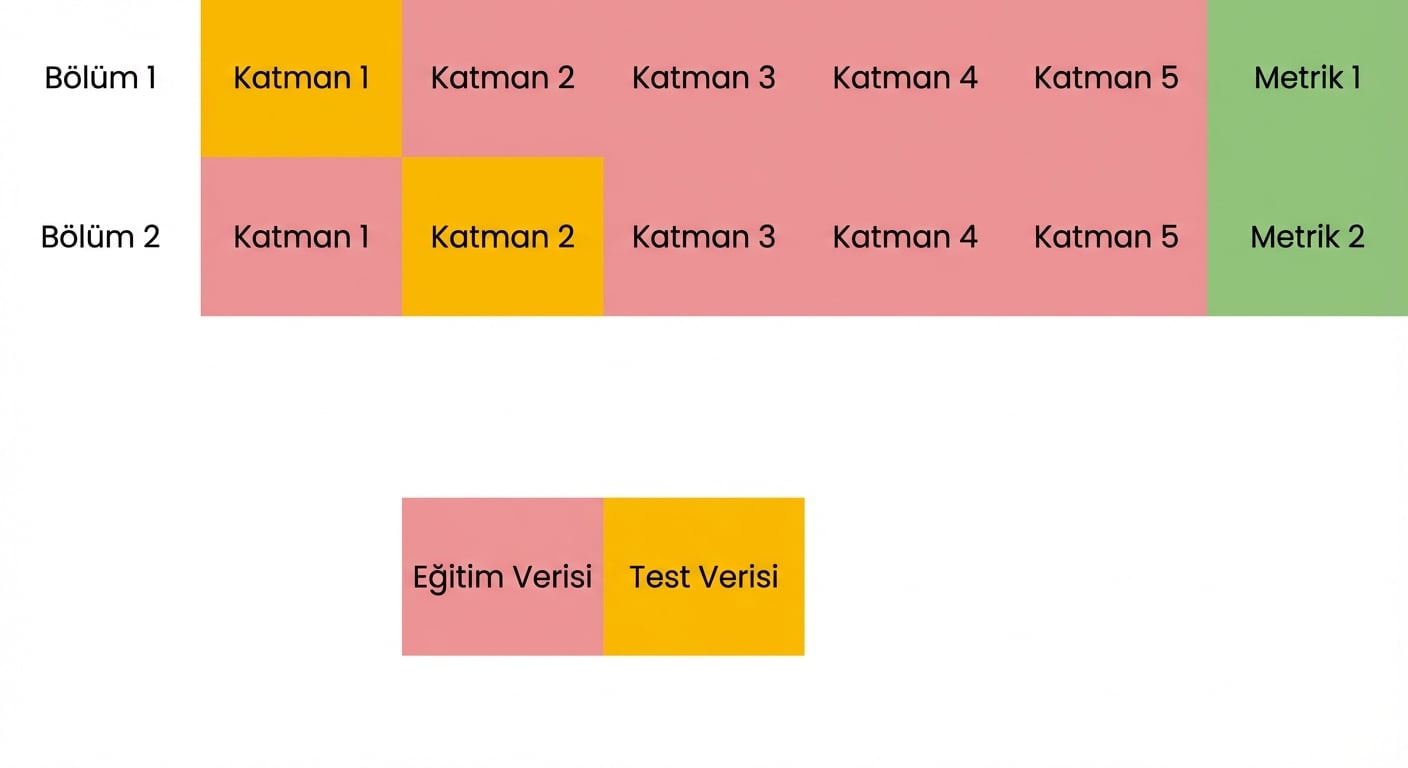
Çapraz doğrulamanın temelleri

Çapraz doğrulamanın temelleri

Çapraz doğrulamanın temelleri