DataFrame'leri bağlama
Python ile Veri Temizleme

Adel Nehme
VP of AI Curriculum, DataCamp
Kayıt bağlama
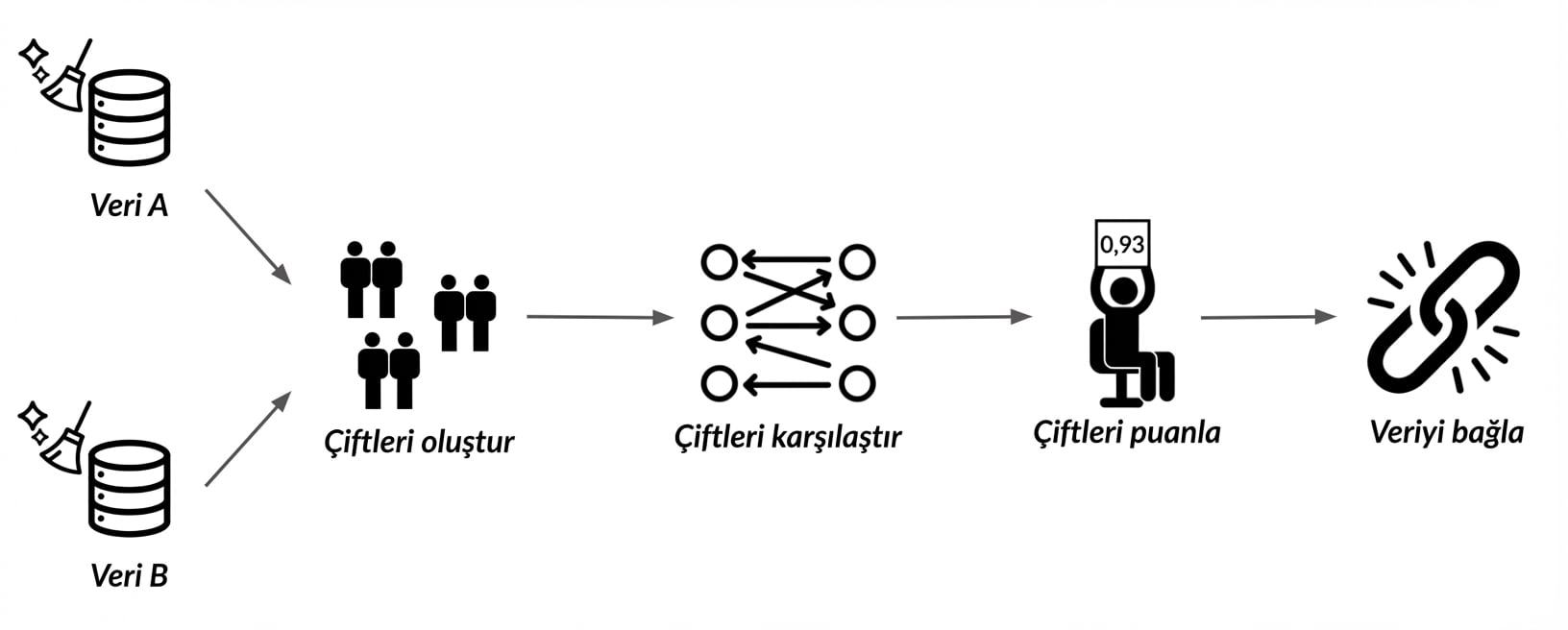
Kayıt bağlama
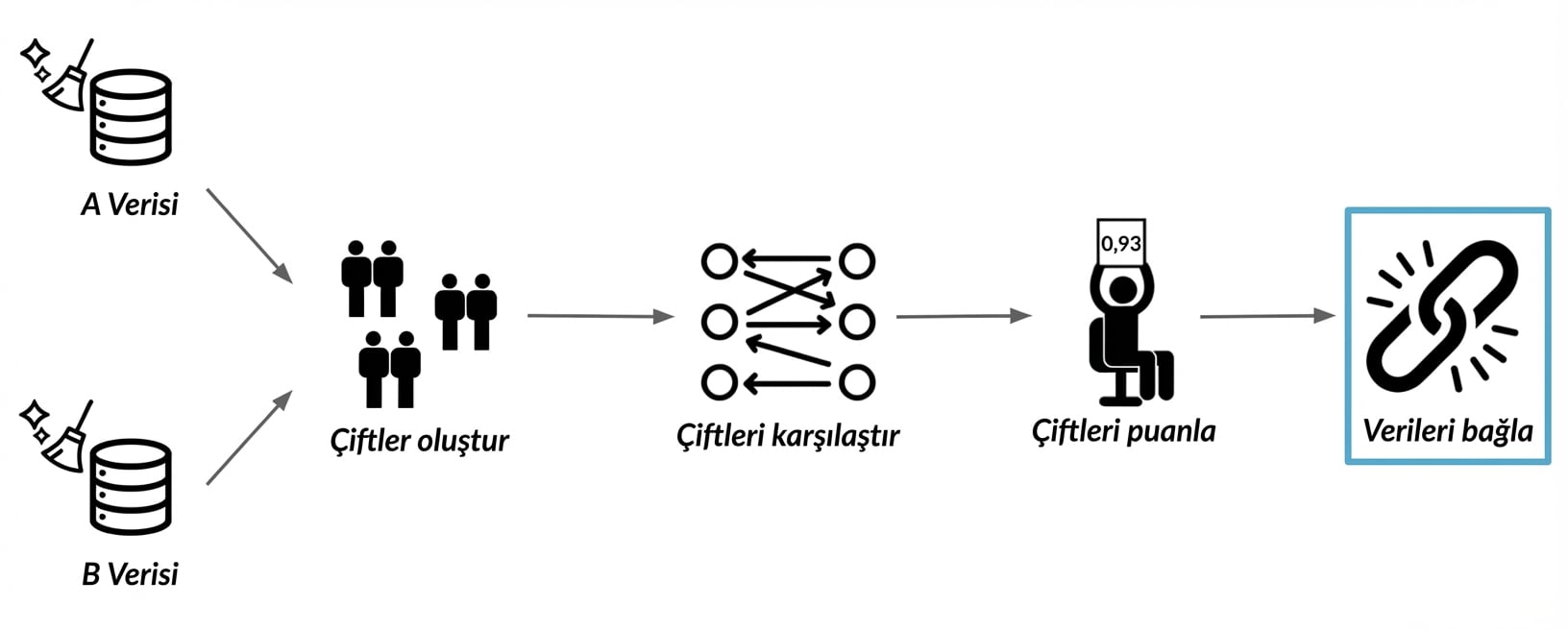
Şu an ne yapıyoruz
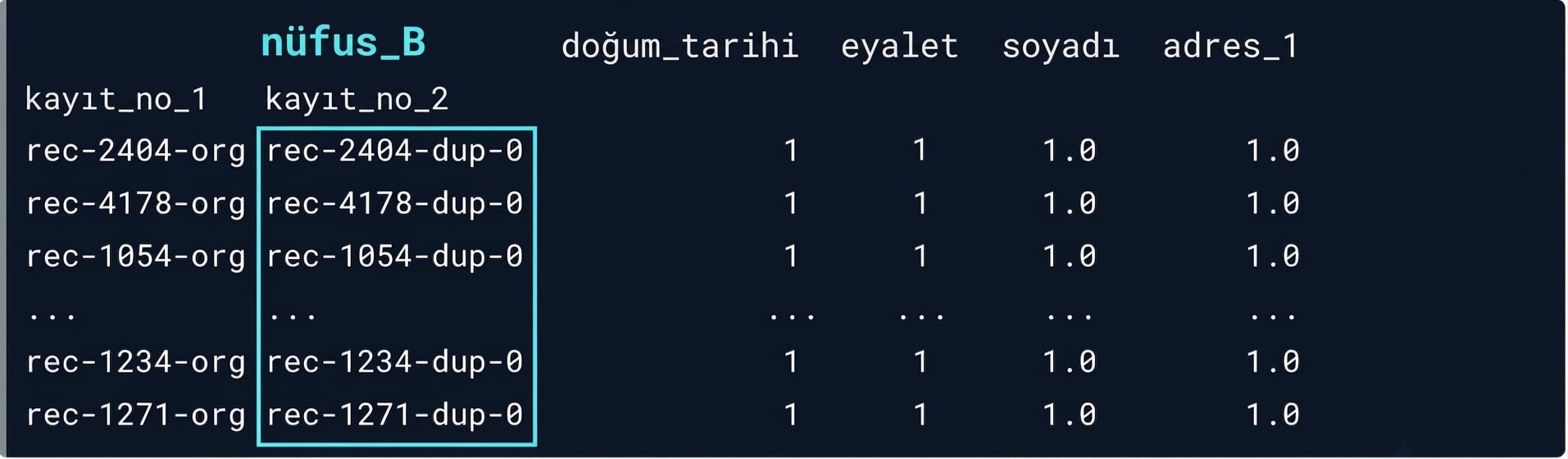
Olası eşleşmelerimiz
potential_matches
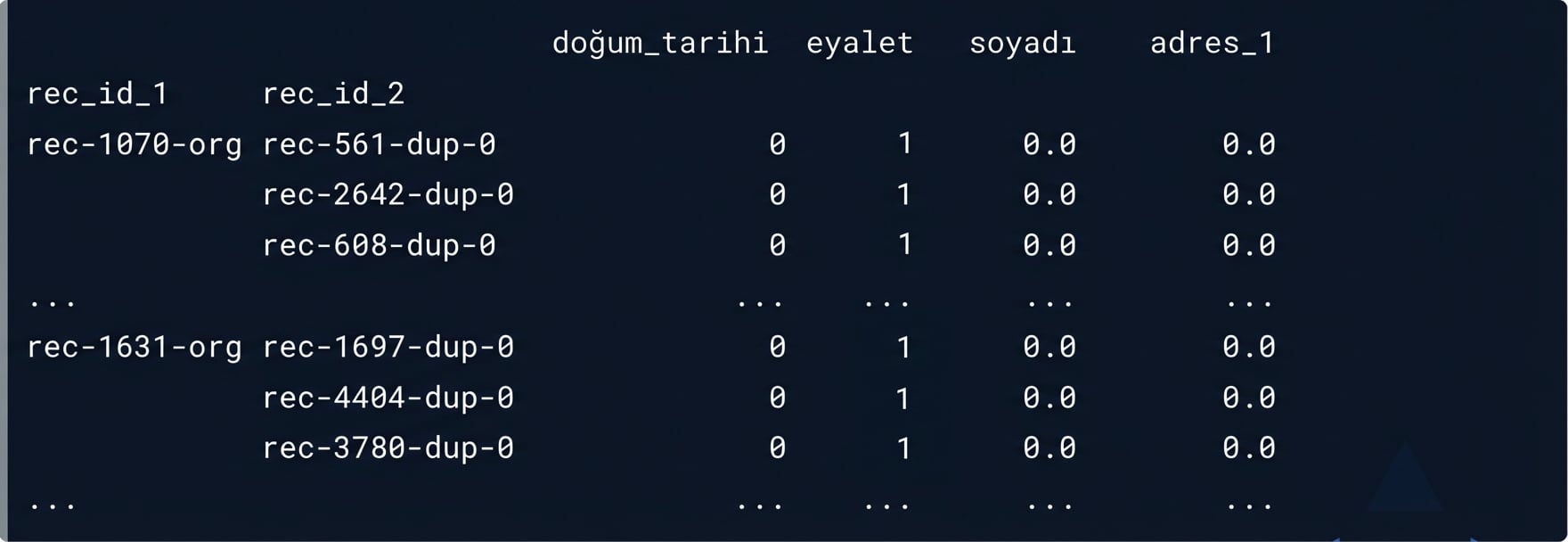
Olası eşleşmelerimiz
potential_matches
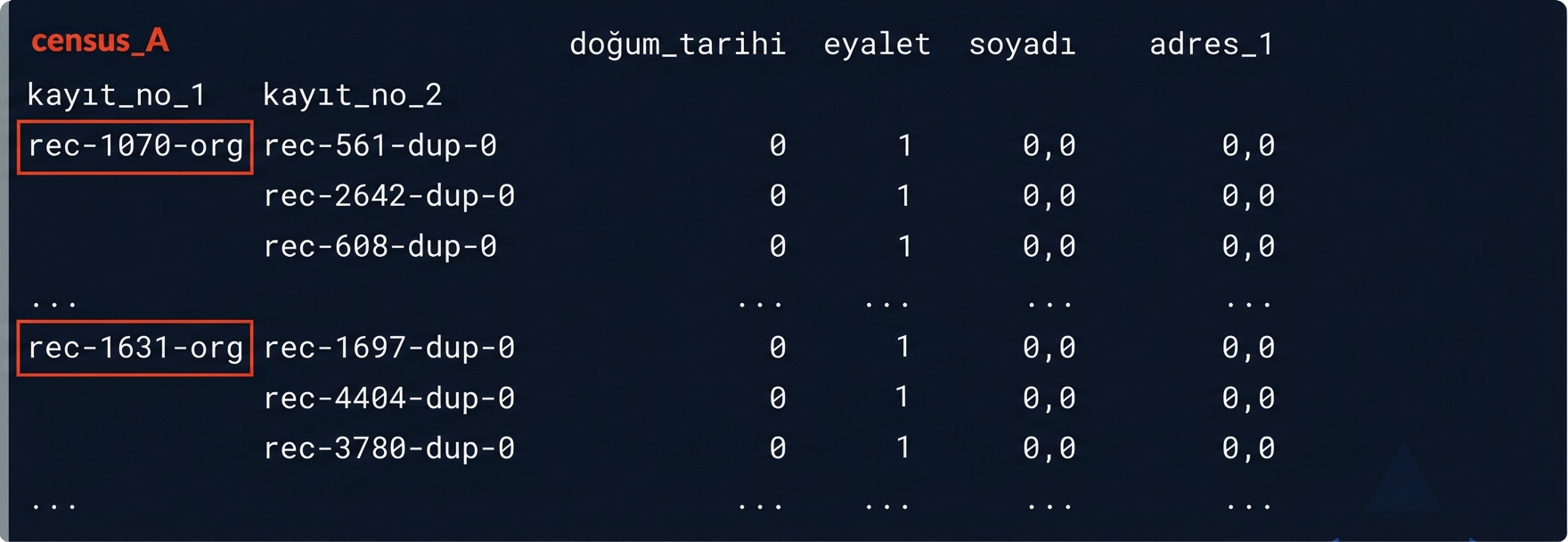
Olası eşleşmelerimiz
potential_matches

Olası eşleşmelerimiz
potential_matches

Olası eşleşmeler (yüksek olasılık)
matches = potential_matches[potential_matches.sum(axis = 1) >= 3]
print(matches)
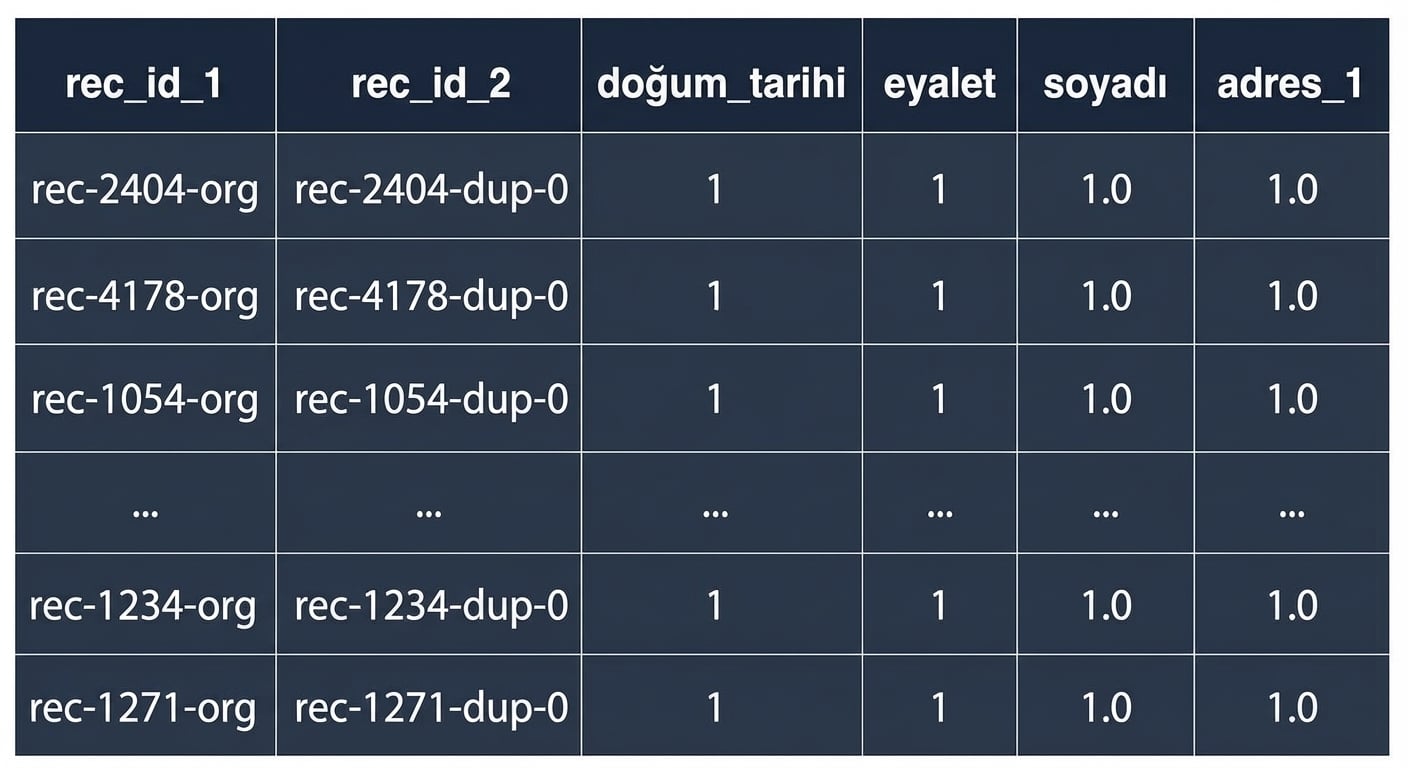
Olası eşleşmeler (yüksek olasılık)
matches = potential_matches[potential_matches.sum(axis = 1) >= 3]
print(matches)