Üyelik kısıtları
Python ile Veri Temizleme

Adel Nehme
Content Developer @DataCamp
Bu sorunlar neden oluşur?
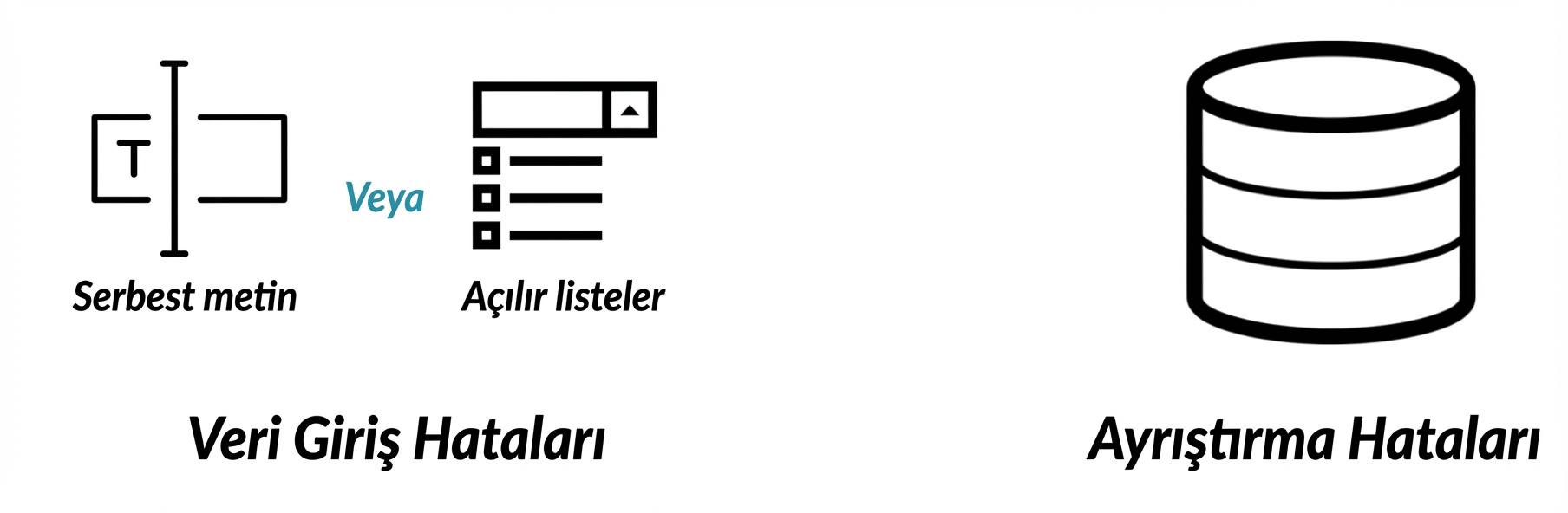
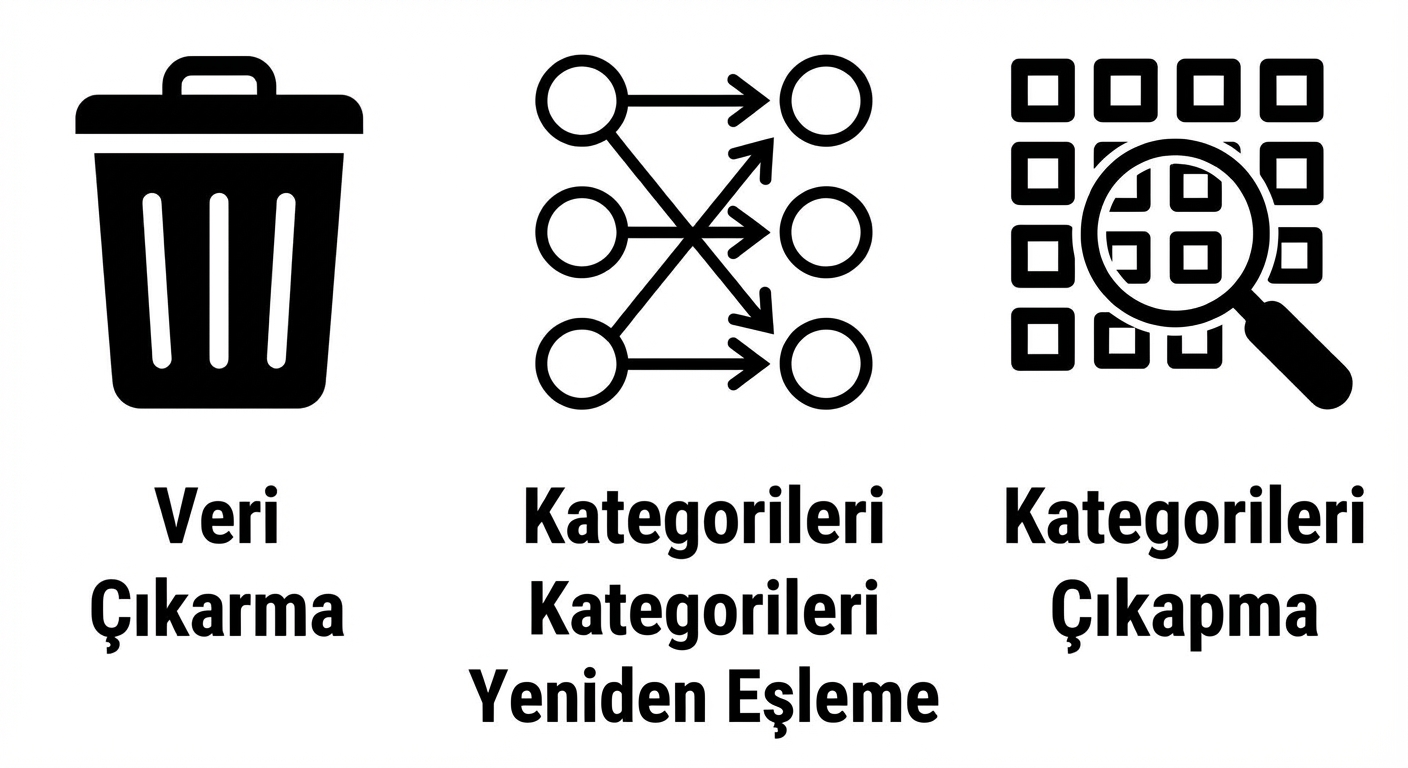
Bu sorunları nasıl ele alırız?
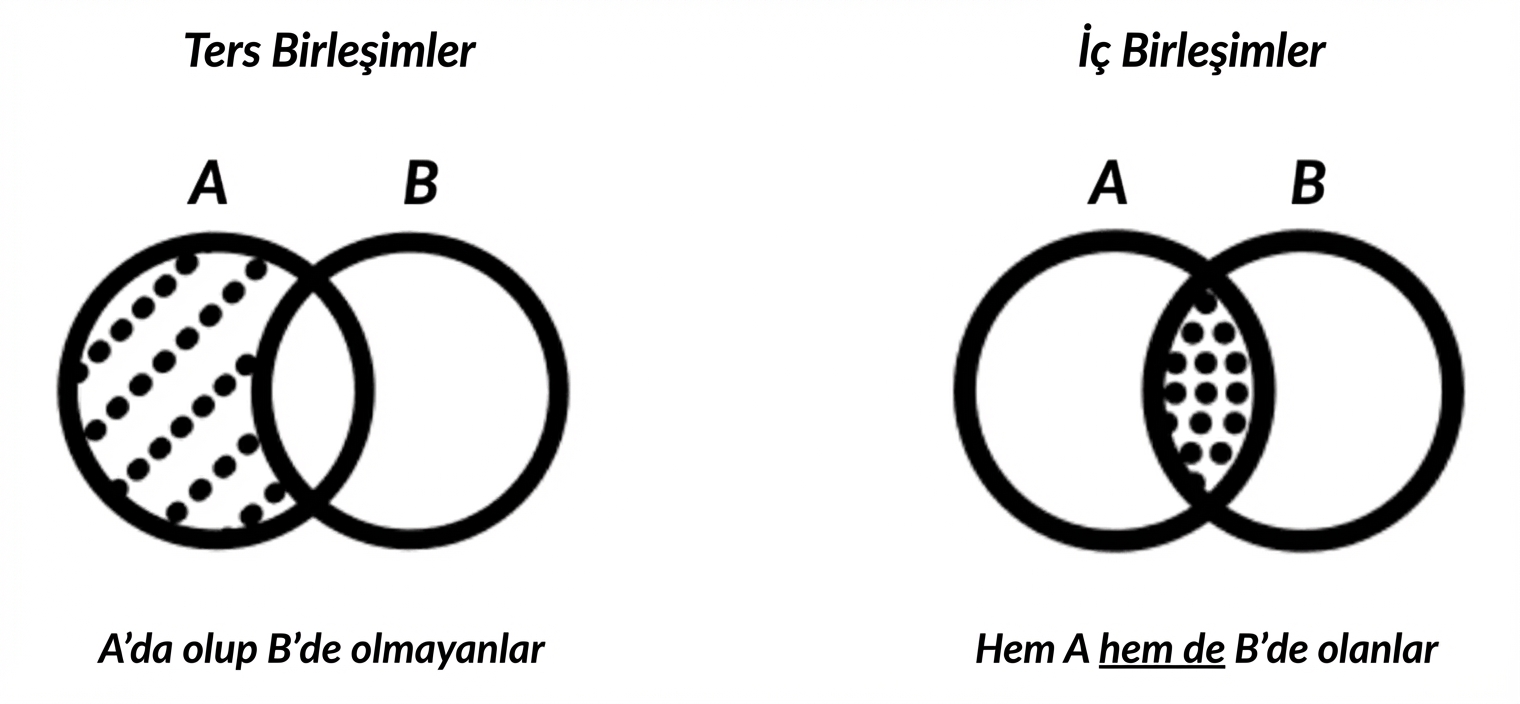
Birleştirmeler hakkında not
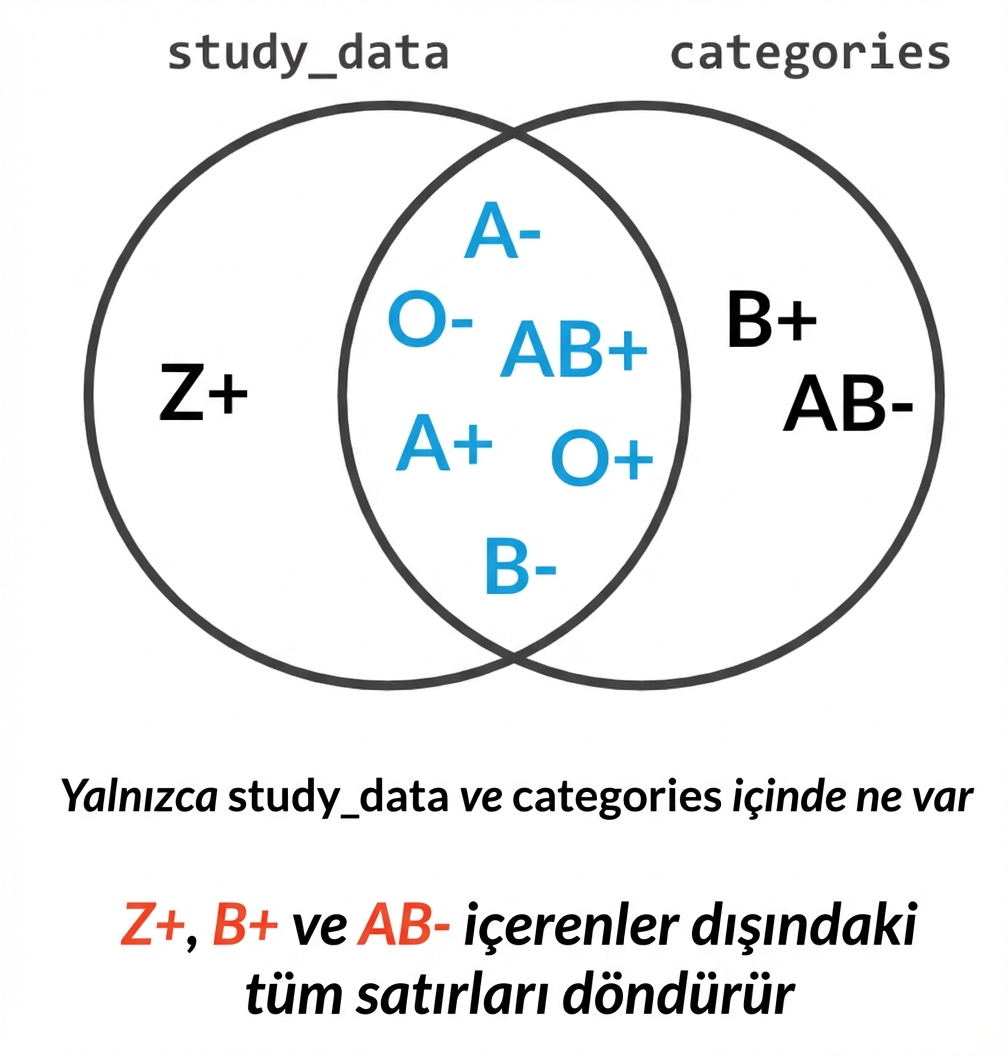
Kan gruplarında left anti join
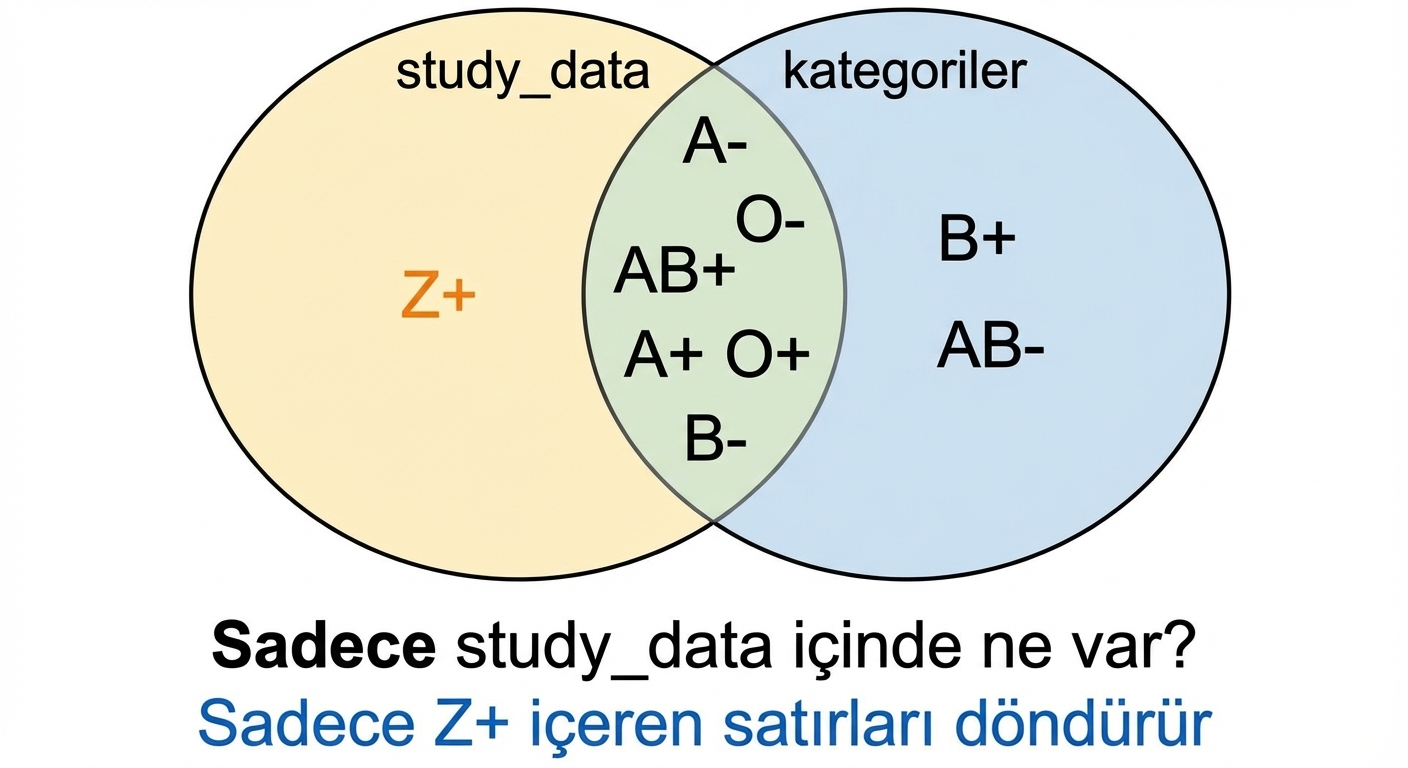
Kan gruplarında inner join
Python ile Veri Temizleme
Adel Nehme
Content Developer @DataCamp

