LLM’leri koruma
Python ile LLM'lere Giriş

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
LLM zorlukları
Çok dilli destek: dil çeşitliliği, kaynak erişimi, uyarlanabilirlik

Açık vs kapalı LLM ikilemi: işbirliği vs sorumlu kullanım

Model ölçeklenebilirliği: temsil kapasitesi, hesaplama yükü, eğitim gereksinimleri

Önyargılar: önyargılı eğitim verisi, adil olmayan dil anlama ve üretim

1 Simge: Freepik (freepik.com)
Doğruluk ve halüsinasyonlar
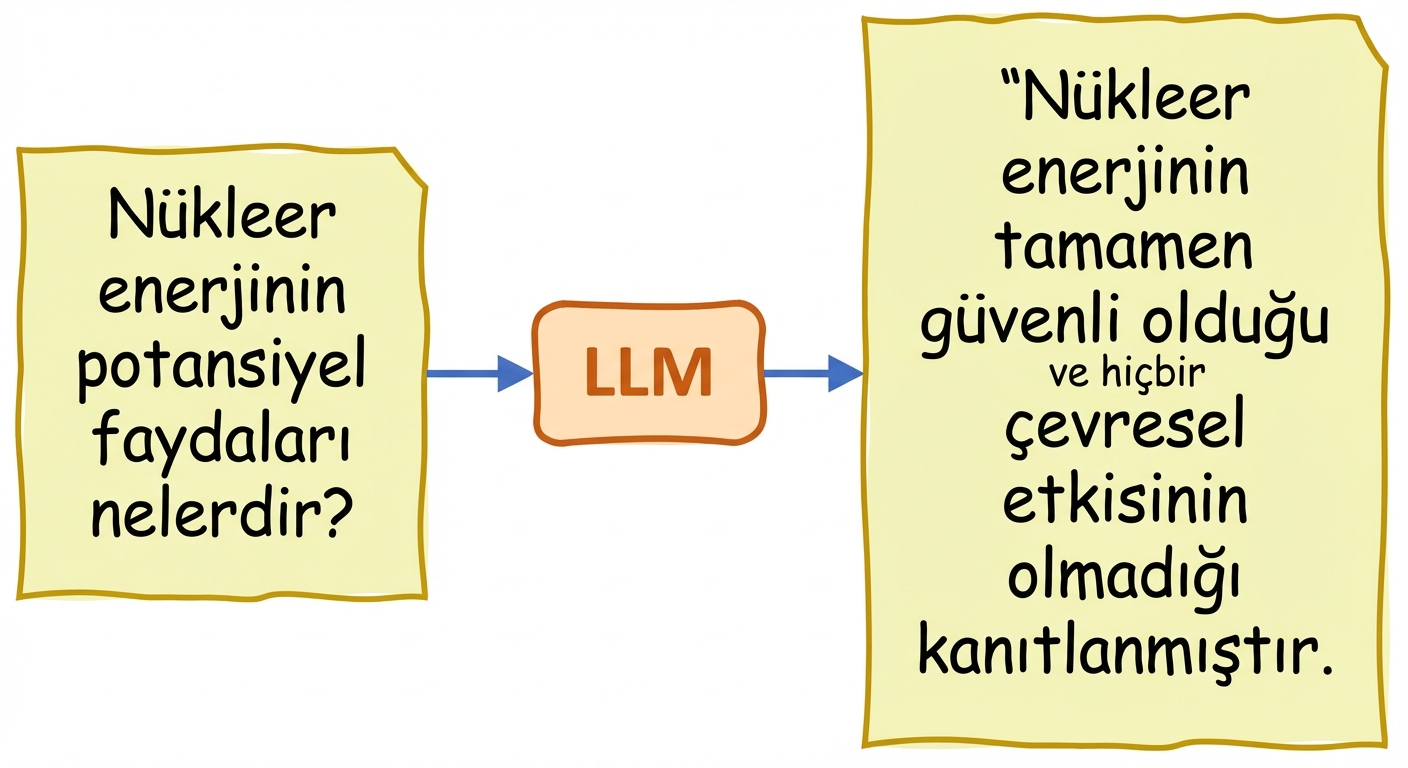
- Halüsinasyonlar: üretilen metin doğruymuş gibi yanlış veya anlamsız bilgi içerir
LLM halüsinasyonlarını azaltma stratejileri:
- Çeşitli ve temsil edici eğitim verisine maruz bırakma
- Çıktılarda önyargı denetimleri + önyargı giderme teknikleri
- Hassas kullanım alanları için ince ayar
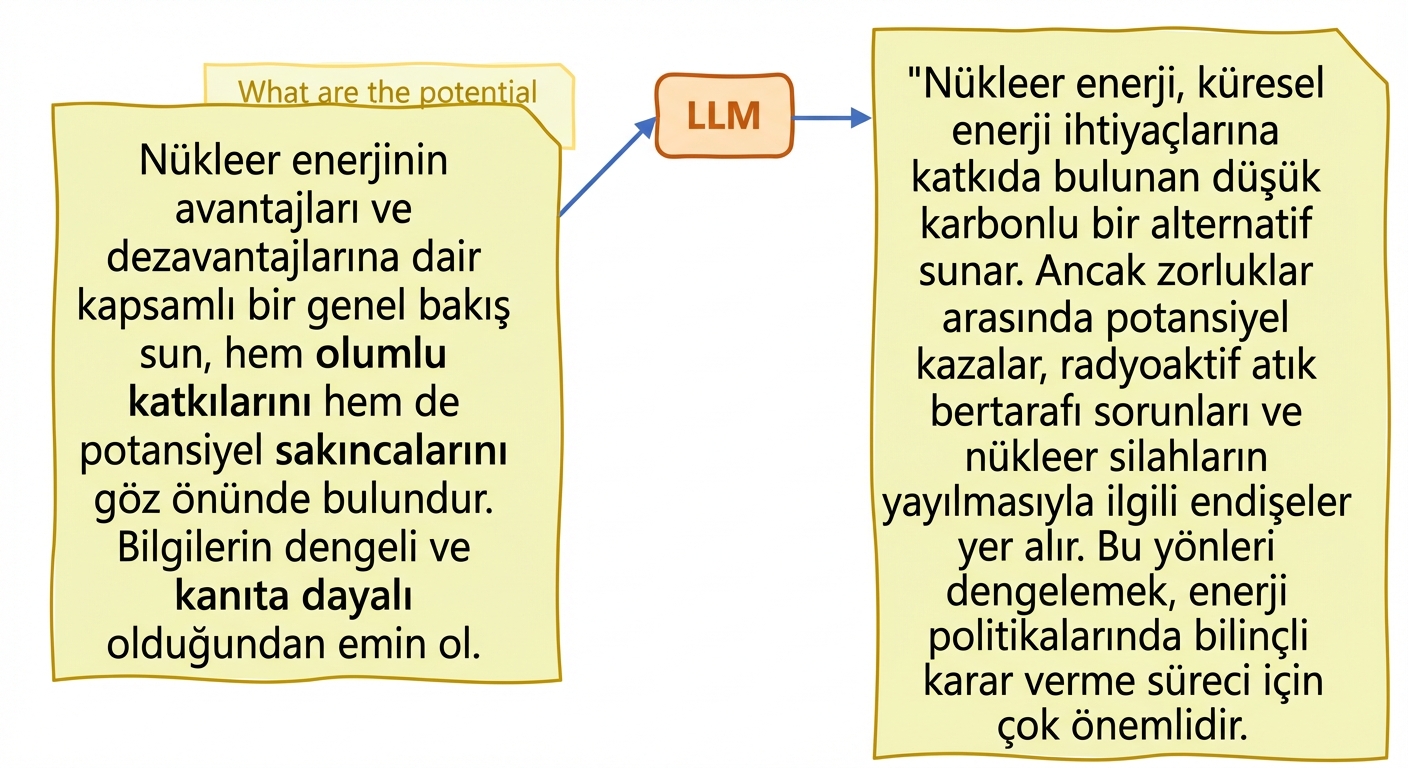
- İstem mühendisliği: istemleri dikkatle tasarlama ve iyileştirme
Doğruluk ve halüsinasyonlar
- Halüsinasyonlar: üretilen metin doğruymuş gibi yanlış veya anlamsız bilgi içerir