İnce ayara hazırlık
Python ile LLM'lere Giriş

Jasmin Ludolf
Senior Data Science Content Developer, DataCamp
Pipelines ve auto sınıfları
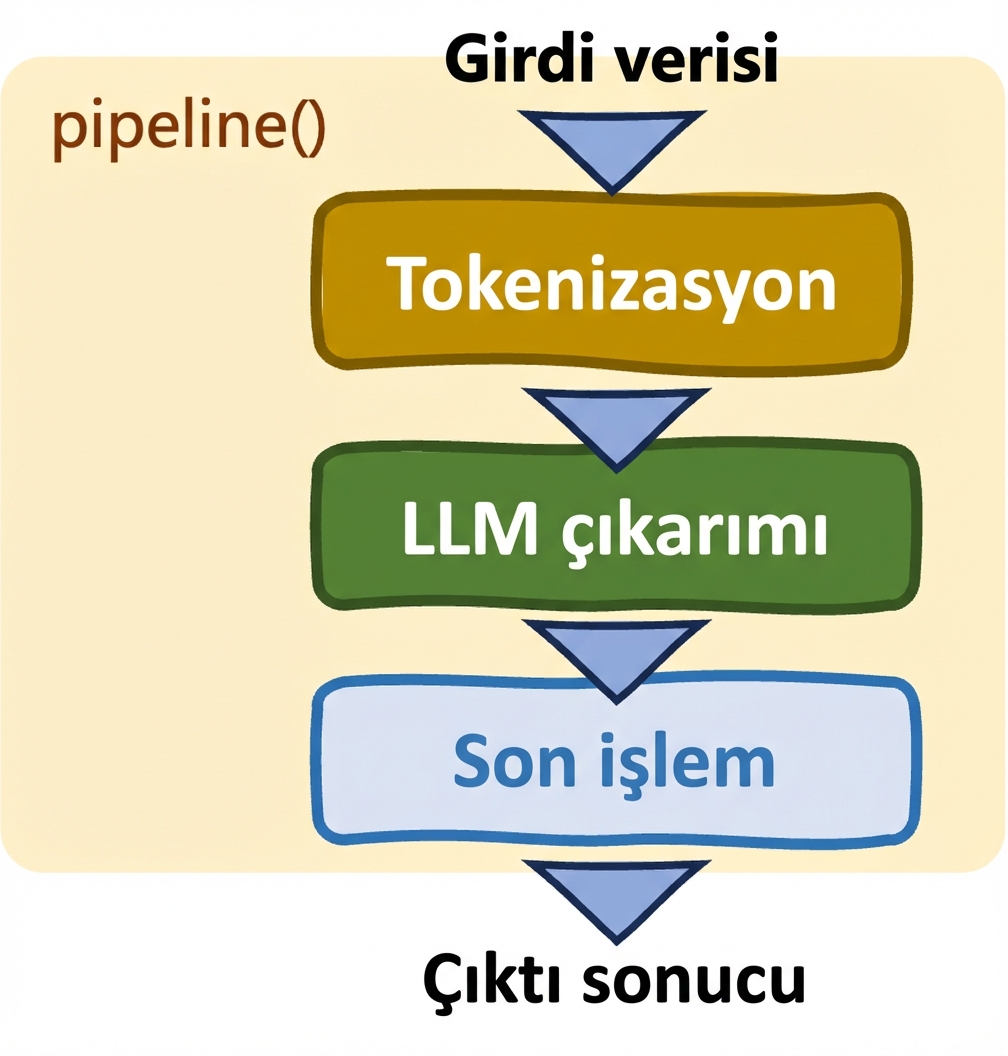
Pipelines: pipeline()
- Görevleri basitleştirir
- Model ve tokenizer'ı otomatik seçer
- Sınırlı kontrol
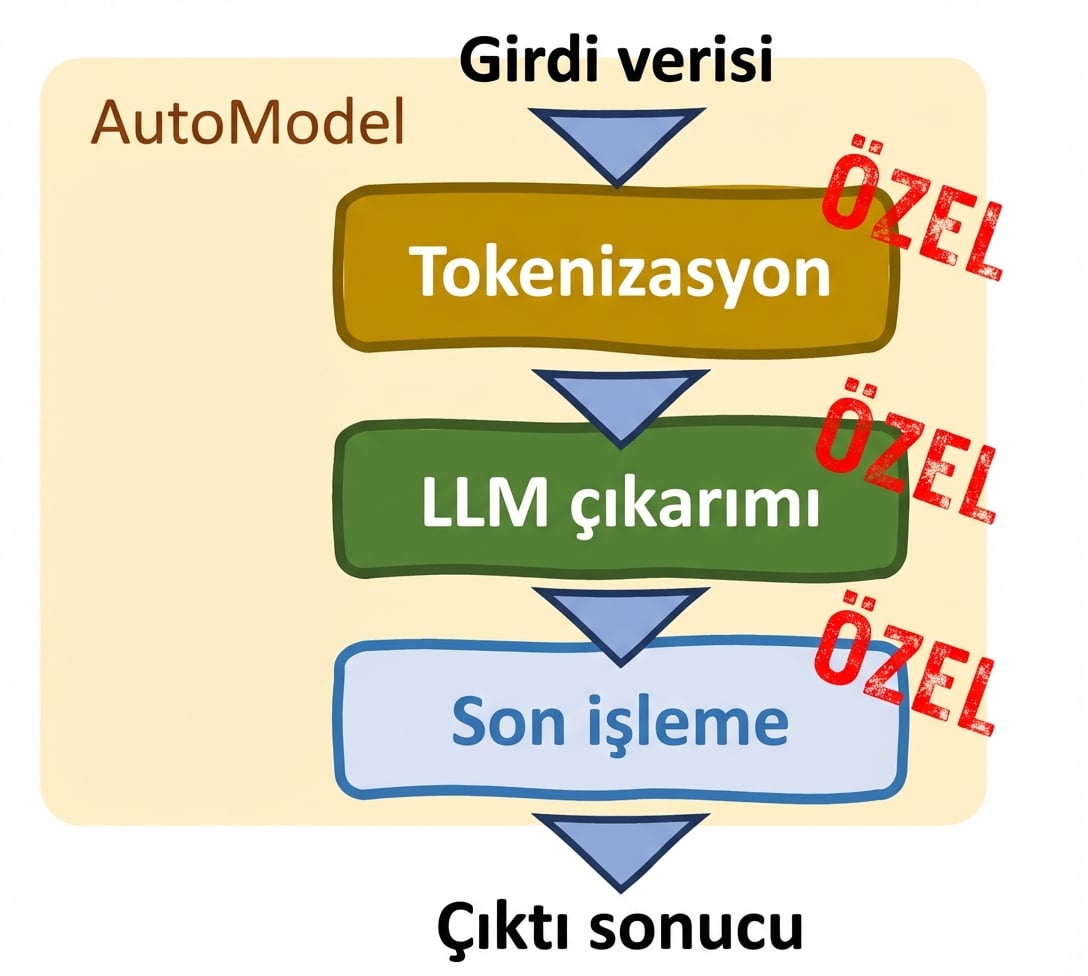
Auto sınıfları (AutoModel sınıfı)
- Özelleştirme
- Manuel ayarlamalar
- İnce ayarı destekler
LLM yaşam döngüsü
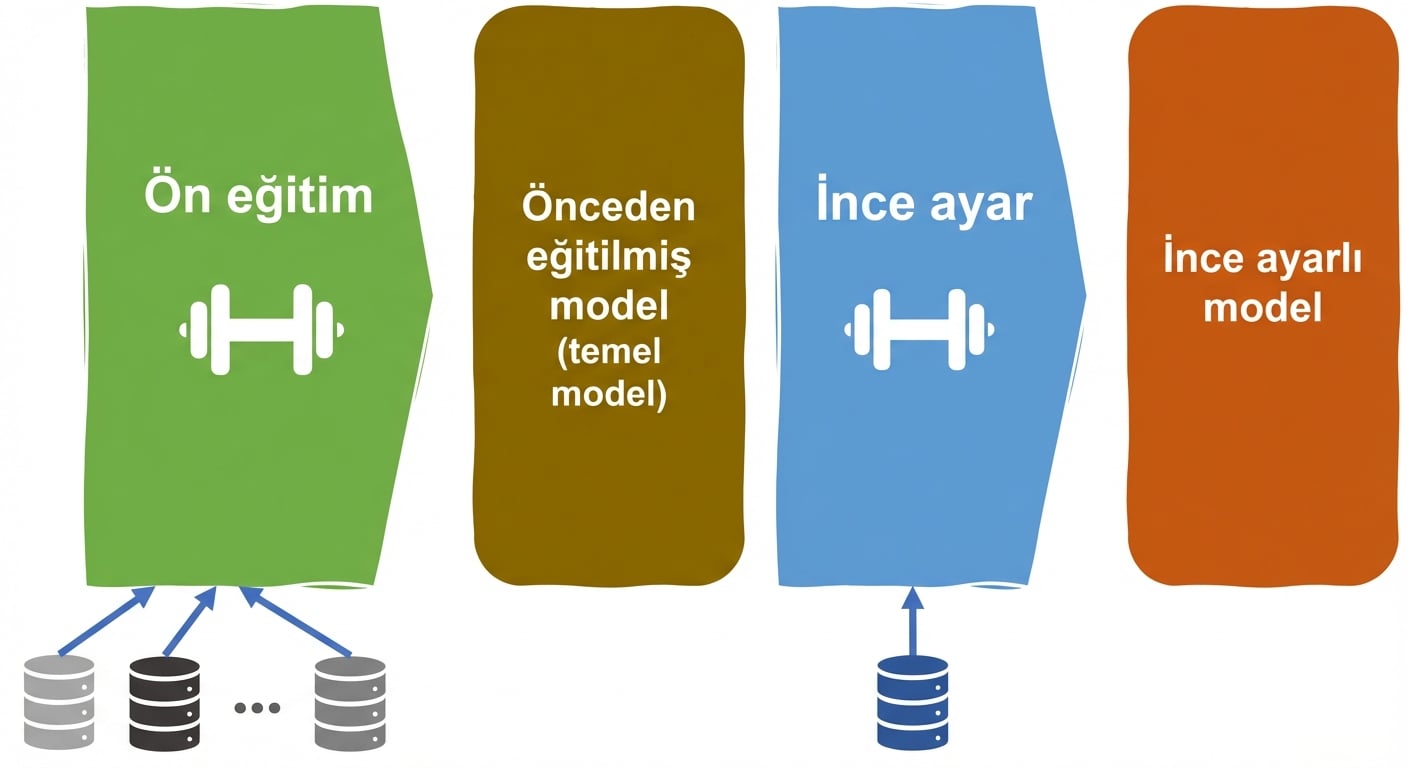
LLM yaşam döngüsü
Alt-birim tokenleştirme
- Modern tokenizer'larda yaygın
- Sözcükler anlamlı alt parçalara bölünür

Alt-birim tokenleştirme
- Modern tokenizer'larda yaygın
- Sözcükler anlamlı alt parçalara bölünür


