Daha iyi kümeleme için özellik dönüştürme
Python'da Unsupervised Learning

Benjamin Wilson
Director of Research at lateral.io
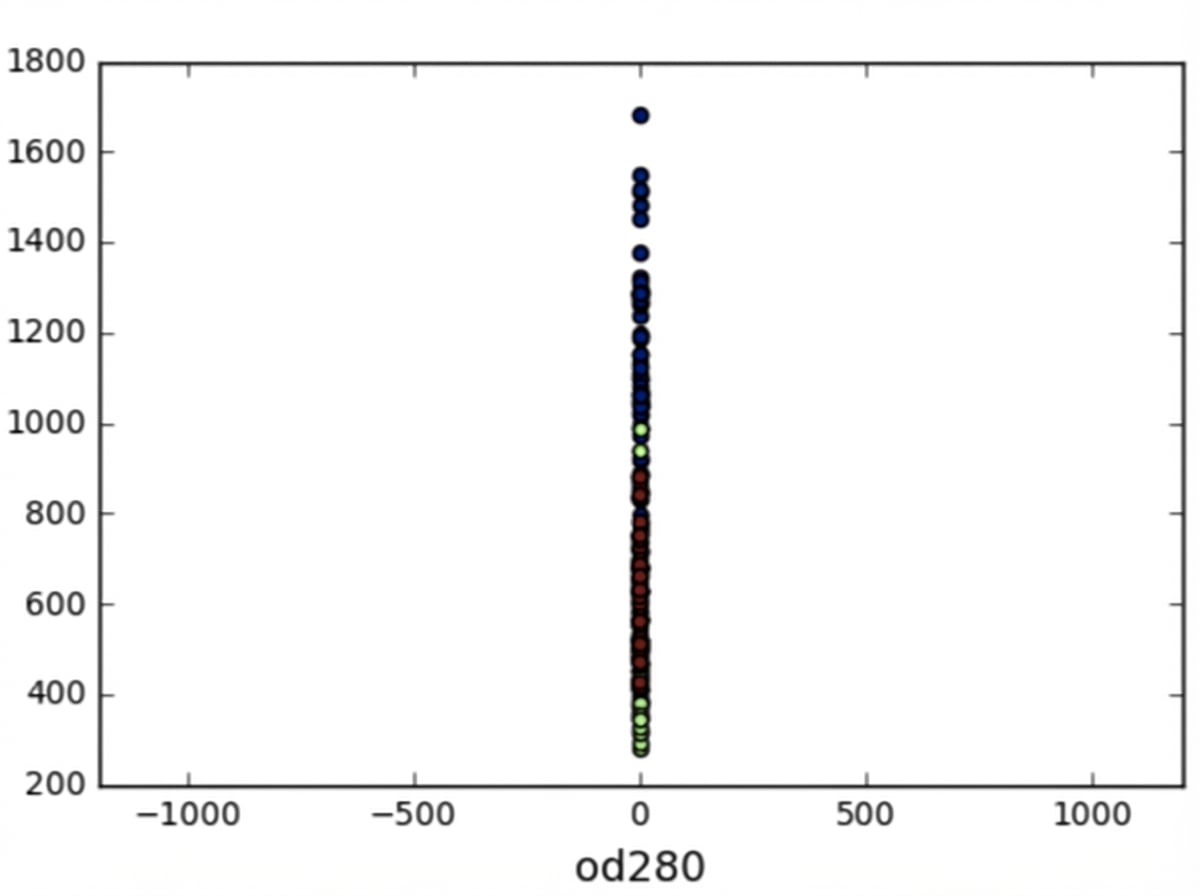
Özellik varyansları
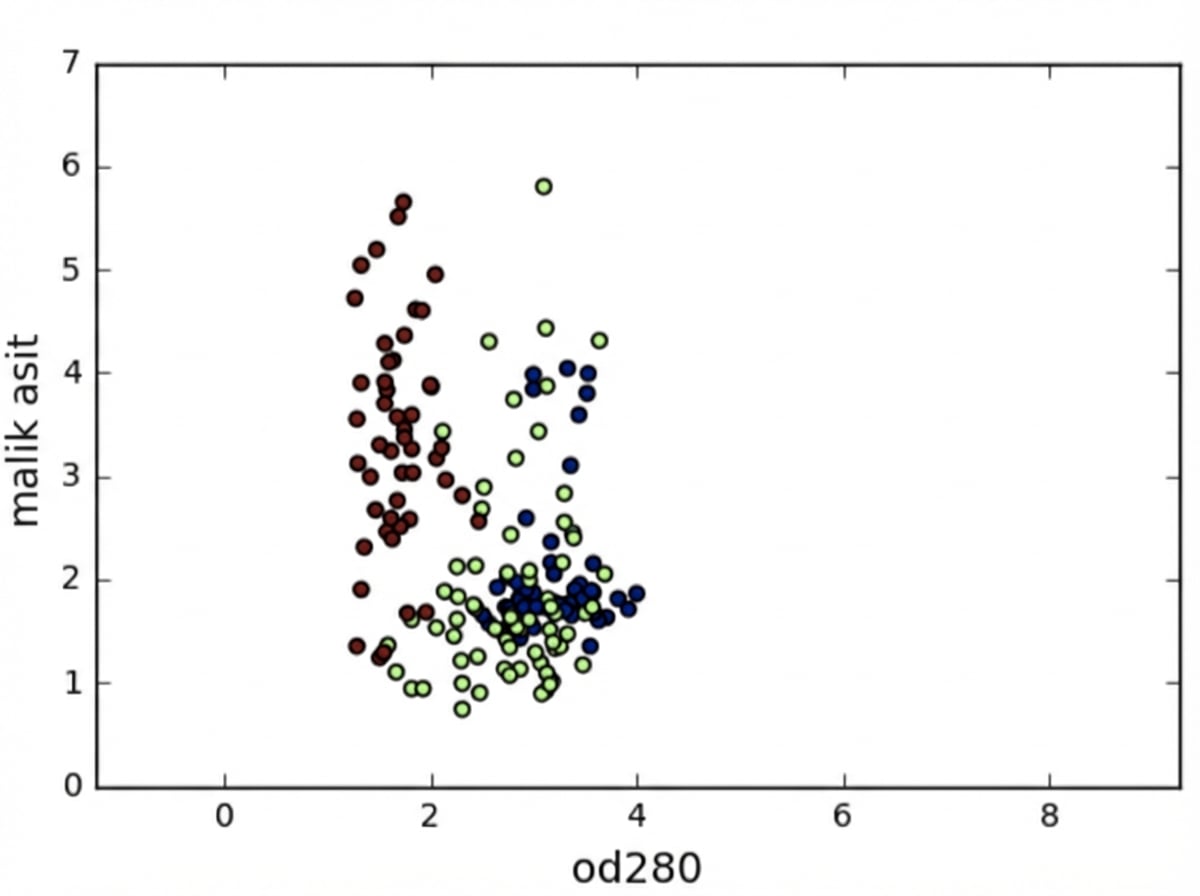
Özellik varyansları
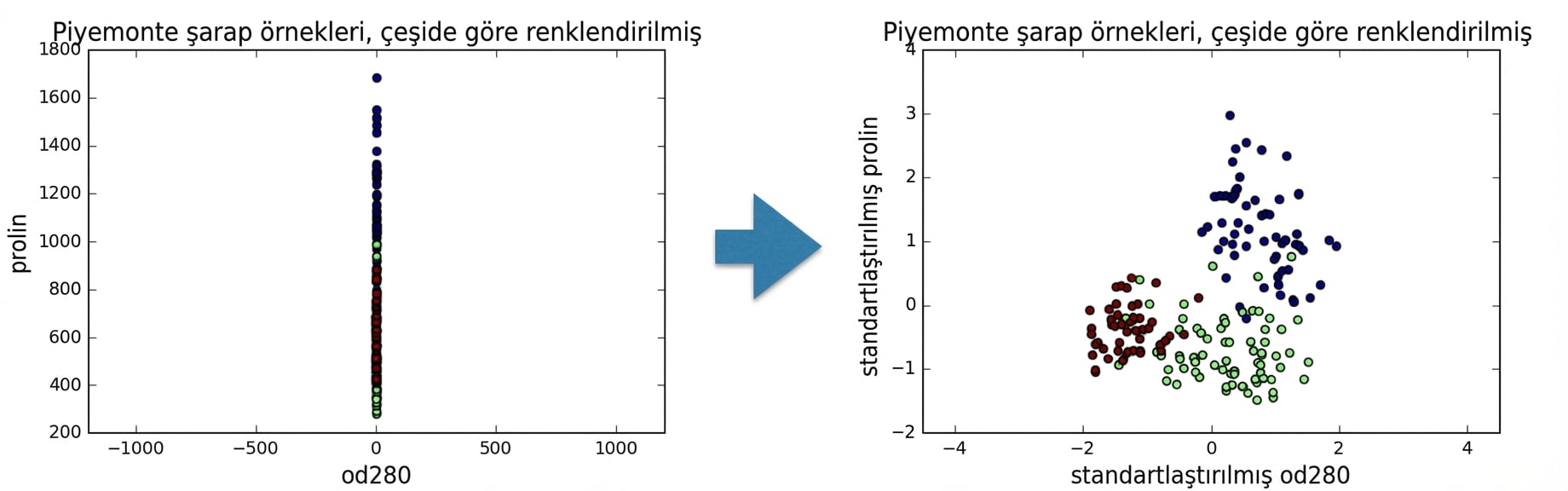
StandardScaler
k-means'te: özellik varyansı = özellik etkisi
StandardScalerher özelliği ortalaması 0, varyansı 1 olacak şekilde dönüştürürÖzellikler "standartlaştırılmış" olur