Önyargı ve Varyans Sorunlarını Teşhis Etme
Python ile Ağaç Tabanlı Modellerle Machine Learning

Elie Kawerk
Data Scientist
Genelleme Hatasını Tahmin Etme
Bir modelin genelleme hatasını nasıl tahmin ederiz?
Doğrudan yapılamaz çünkü:
$f$ bilinmiyor,
genelde tek bir veri kümeniz vardır,
gürültü öngörülemez.
Genelleme Hatasını Tahmin Etme
Çözüm:
- veriyi eğitim ve test setlerine ayırın,
- $\hat{f}$'i eğitim setine uydurun,
- $\hat{f}$'in hatasını görülmemiş test setinde değerlendirin.
- $\hat{f}$'in genelleme hatası ≈ test seti hatası.
Çapraz Doğrulama ile Daha İyi Değerlendirme
Test setine, $\hat{f}$'in performansından emin olana dek dokunulmamalıdır.
$\hat{f}$'i eğitim setinde değerlendirmek yanlıdır; $\hat{f}$ tüm eğitim noktalarını zaten görmüştür.
Çözüm → Çapraz Doğrulama (ÇD):
K-Katlı ÇD,
Ayırmalı (Hold-Out) ÇD.
K-Katlı ÇD
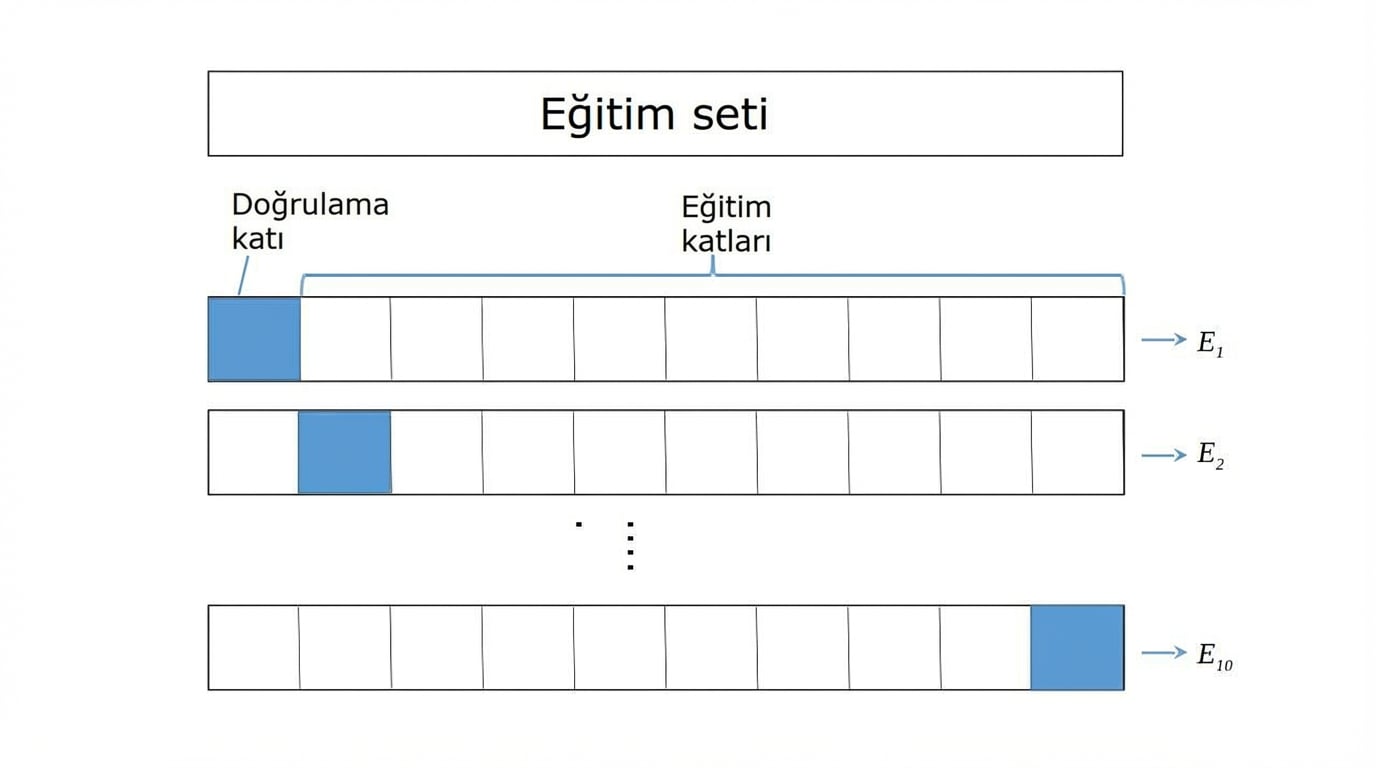
K-Katlı ÇD
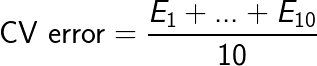
Varyans Sorunlarını Teşhis Etme
$\hat{f}$ yüksek varyans gösteriyorsa:
$\hat{f}$'in ÇV hatası > eğitim seti hatası.
- $\hat{f}$ eğitim setine aşırı uyum sağlar (overfit). Çözüm:
- model karmaşıklığını azaltın,
- örn: azami derinliği düşürün, yaprak başına asgari örnek sayısını artırın, ...
- daha fazla veri toplayın, ..
Önyargı Sorunlarını Teşhis Etme
$\hat{f}$ yüksek önyargı gösteriyorsa:
$\hat{f}$'in ÇV hatası ≈ eğitim seti hatası >> istenen hata.
$\hat{f}$ eğitim setini yetersiz uyar (underfit). Çözüm:
- model karmaşıklığını artırın
- örn: azami derinliği yükseltin, yaprak başına asgari örnek sayısını düşürün, ...
- daha ilgili özellikler toplayın
Auto Veri Kümesinde sklearn ile K-Katlı ÇV
from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error as MSE from sklearn.model_selection import cross_val_score# Set seed for reproducibility SEED = 123 # Split data into 70% train and 30% test X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=SEED)# Instantiate decision tree regressor and assign it to 'dt' dt = DecisionTreeRegressor(max_depth=4, min_samples_leaf=0.14, random_state=SEED)
Auto Veri Kümesinde sklearn ile K-Katlı ÇV
# 10 katlı ÇV ile elde edilen MSE listesini hesaplayın # Tüm CPU çekirdeklerini kullanmak için n_jobs'u -1 yapın MSE_CV = - cross_val_score(dt, X_train, y_train, cv= 10, scoring='neg_mean_squared_error', n_jobs = -1)# 'dt'yi eğitim setine uydurun dt.fit(X_train, y_train) # Eğitim setinin etiketlerini tahmin edin y_predict_train = dt.predict(X_train) # Test setinin etiketlerini tahmin edin y_predict_test = dt.predict(X_test)
# ÇV MSE
print('CV MSE: {:.2f}'.format(MSE_CV.mean()))
CV MSE: 20.51
# Eğitim seti MSE
print('Train MSE: {:.2f}'.format(MSE(y_train, y_predict_train)))
Train MSE: 15.30
# Test seti MSE
print('Test MSE: {:.2f}'.format(MSE(y_test, y_predict_test)))
Test MSE: 20.92
Ayo berlatih!
Python ile Ağaç Tabanlı Modellerle Machine Learning

